
A New Paradigm for the Edge Computing Era: The Arrival of YOLO26
In January 2026, YOLO26 was finally unveiled, choosing a path diametrically opposed to recent AI development trends. While the past few years favored stacking complex structures to achieve higher accuracy, YOLO26 boldly declared a diet. This shift was made to embrace the Edge first philosophy, which is most welcomed in practical field applications.
The greatest appeal of YOLO26 is that it is not merely a top student performing well on benchmarks. It is a practical talent that runs smoothly on low power industrial chips or robotic brains (ARM CPUs) rather than just high performance lab computers. It significantly reduces the deployment friction that has long plagued developers when migrating laboratory models to field equipment.
This article explores how YOLO26 eliminated unnecessary bulk to simplify its structure and how it maintained performance by borrowing clever learning methods from Large Language Models (LLMs). We will look into the innovation that makes YOLO26 the standard for vision AI projects beyond 2026.
1. The Evolution of YOLO and Clearing Technical Debt
The YOLO framework has undergone numerous changes since YOLOv1 appeared in 2016. However, the complex graph structures introduced for accuracy and operations causing overhead on specific hardware accelerators have acted as a form of technical debt. YOLO26 boldly sheds this complexity and returns to a structure optimized for edge environments.
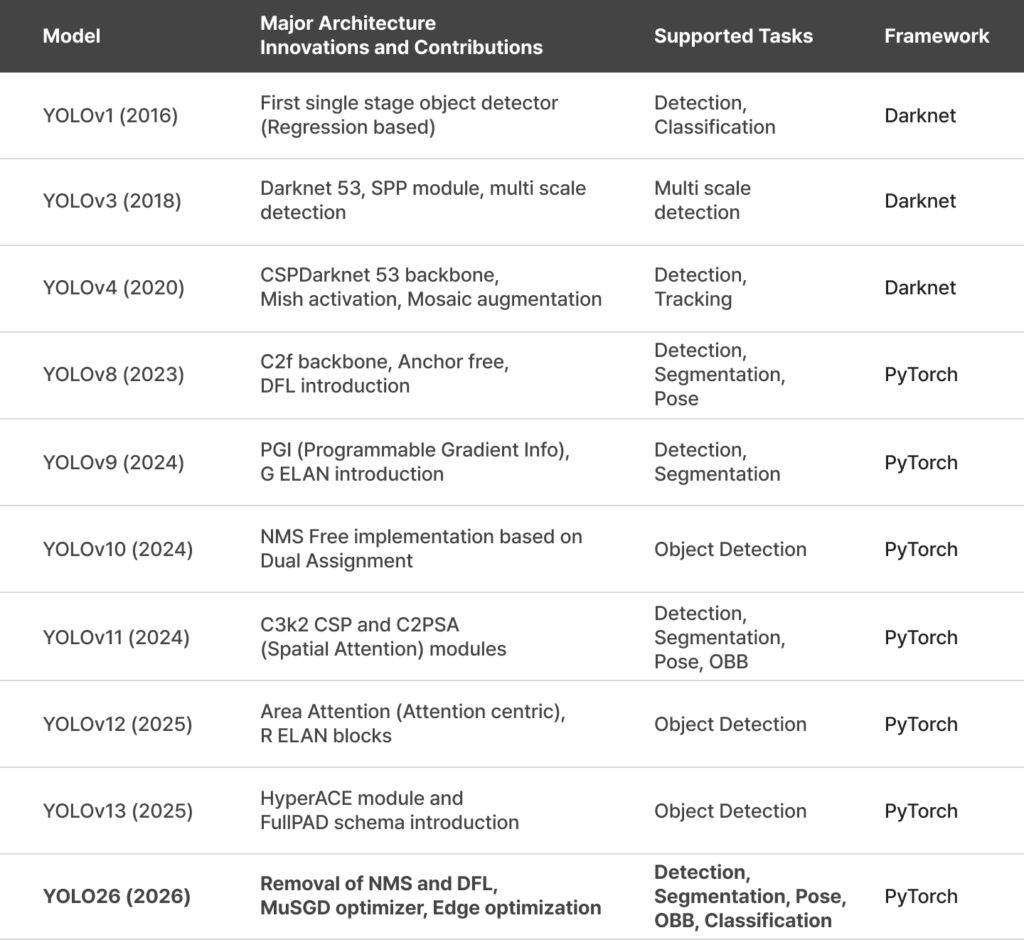
2. Architectural Innovation: Four Core Technologies for Edge Optimization
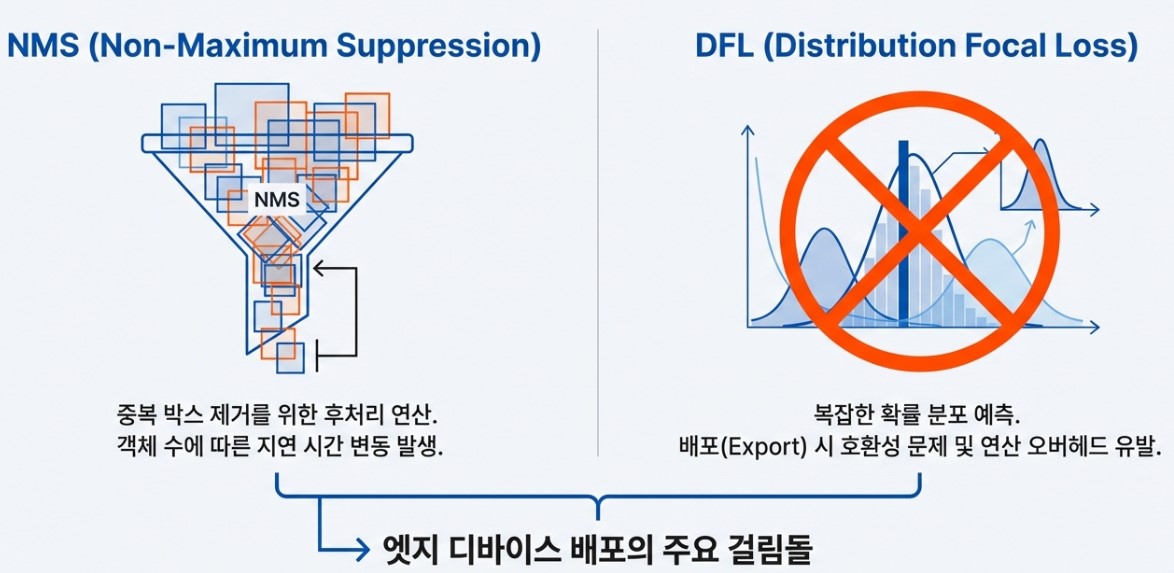
2.1 End to End NMS Free Inference and Jitter Removal
Any developer who has applied object detection models to real world tasks knows how tedious it is to handle numerous overlapping boxes. We previously relied on a post processing step called NMS (Non Maximum Suppression) to pick the single correct box among many. However, YOLO26 eliminates this complex process and implements true End to End inference that flows seamlessly from input to result.

The core of YOLO26 is that the model no longer uses a strategy of predicting many boxes and filtering them later. Instead, it is trained from the start to predict only one correct box per object. By redesigning the prediction head at the very end of the model, it directly outputs results without redundancy. Consequently, a separate NMS process is entirely unnecessary during inference.
Furthermore, it simplifies coordinate calculation to enhance lightweight characteristics. While previous models used complex DFL (Distribution Focal Loss) for precision, YOLO26 adopts an intuitive method that hardware can process faster. Any potential loss in accuracy was effectively compensated through new training techniques.
The results are impressive. With heavy NMS operations gone, CPU processing speed is more than 40% faster than previous models. Most importantly, processing time remains consistent even as the number of objects increases. This simplifies the inference pipeline and enables faster, more stable performance on resource constrained edge devices. This offers a decisive advantage for robotics and autonomous systems where real time control loops are essential.
The elimination of complex post processing code has significantly reduced the compatibility issues developers used to face when converting models across different platforms. Now, developers can implement AI vision more quickly and cleanly through YOLO26.
2.2 Bold Removal of Distribution Focal Loss (DFL)
Previous generations like YOLOv8 or YOLO11 utilized a technique called Distribution Focal Loss (DFL) to achieve pinpoint accuracy in object localization. Essentially, instead of defining bounding box coordinates as single fixed numbers, it predicted them as probability distributions to capture objects with ambiguous boundaries. While this improved accuracy, the complex calculations slowed down inference speeds and often became a major hurdle for model compatibility when converting to different platforms.
YOLO26 has boldly removed DFL. By discarding complex probability calculations, the model returns to a simple and intuitive Direct Regression method for coordinate prediction. This shift has significantly simplified the model architecture, granting it the flexibility to run lightly and quickly on any hardware. While there might be concerns regarding a drop in precision due to this simplified approach, YOLO26 perfectly compensates for this through clever training strategies.
First, it introduced ProgLoss to boost overall performance by guiding the model to focus more on difficult problems as training progresses. Additionally, it implemented STAL technology to ensure that small or occluded objects, which were frequently missed by older models, are captured during the learning process. Furthermore, by incorporating the MuSGD optimizer inspired by Large Language Model (LLM) training techniques, YOLO26 has secured both training speed and stability.
Ultimately, YOLO26 has increased speed by offloading heavy burdens during the inference stage while preventing accuracy loss through a more sophisticated training design. For developers, this means experiencing a model that is lighter and more compatible while actually delivering superior performance.
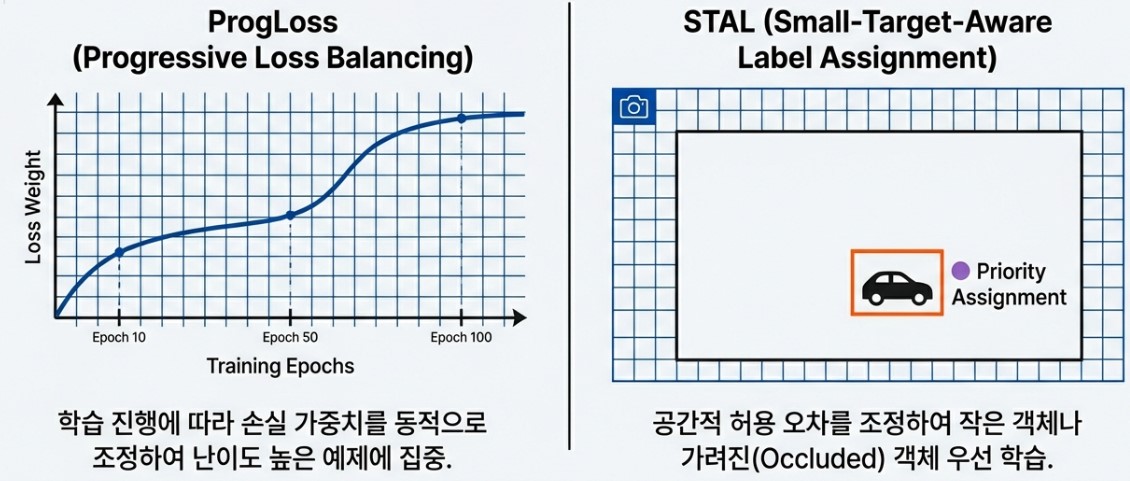
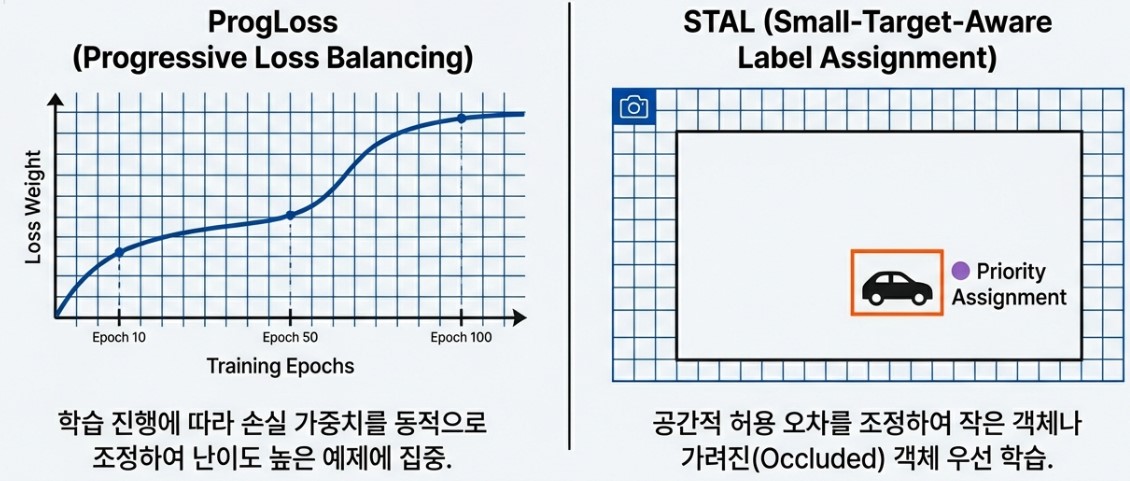
2.3 ProgLoss and STAL: Refining Small Object Detection
What is the secret behind YOLO26 maintaining, or even sharpening, its detection capabilities after boldly removing complex operational components like DFL and NMS? The answer lies in two innovative supporters hidden within the training stage: ProgLoss and STAL. They act like teachers who push the model not to settle for easy problems and provide intensive tutoring on the most difficult areas.
Generally, AI models tend to focus on large and clear objects that are easy to identify as training repeats. This is similar to a student who tries to maintain their score by only solving easy questions while studying for an exam. This is where Progressive Loss Equilibrium (ProgLoss) comes into play. ProgLoss changes the scoring criteria or weights in real time according to the training progress. Whenever the model becomes complacent by adapting to easy examples, ProgLoss places greater weight on the unconquered, difficult cases to ensure the model stays focused until the end. As a result, the model gains a well balanced sense of recognition without being biased toward specific data.
However, overall balance alone is not enough, as small or blurry objects that look like mere dots on the screen remain the toughest challenges for AI. This is where Small Target Aware Label Assignment (STAL) acts as the problem solver. STAL prioritizes small objects that previous models often ignored due to a severe lack of pixel information. By flexibly adjusting the target assignment range around small objects, it sends a strong signal to the model that even these tiny points are important answers that must not be missed.
Ultimately, if ProgLoss is the supervisor that maintains the overall training balance to prevent the model from taking the easy path, STAL is the specialized tutor that helps the model capture its greatest weakness, small objects. Thanks to the perfect collaboration between these two technologies, YOLO26 can deliver overwhelming performance in fields where small details are vital, such as drone imagery or precision medical diagnostics, all while stripping away heavy operational processes.
2.4 MuSGD Optimizer: Successful Transplantation of LLM Technology
The final piece of the puzzle explaining how YOLO26 achieved better performance despite a simpler structure lies in its training tool, the Optimizer. Interestingly, YOLO26 borrowed a training secret from the Large Language Models (LLMs) that are currently taking the AI industry by storm. This is the new optimizer known as MuSGD.
Commonly used tools like AdamW update parameters individually, a method that often causes the training direction to fluctuate or takes a long time to find the optimal solution. In contrast, MuSGD solves this problem by introducing the Newton Schulz iteration, a powerful mathematical technique used in training LLMs like the Kimi K2 model. To use a simple analogy, instead of wandering through a forest looking at every single tree, it is like using a compass to mathematically align the fastest straight path for training. This is technically referred to as Matrix Orthogonalization, which allows the model to move directly toward the correct answer without unnecessary trial and error.
This technology is particularly vital for YOLO26 due to the model’s diet. As mentioned earlier, YOLO26 removed complex safety measures like DFL to stay lightweight. MuSGD serves as a powerful guide in a situation where training could have otherwise become unstable. As a result, developers can train the model faster and more reliably without the need for complex parameter tuning. Ultimately, MuSGD is the hidden contributor that allows the lightweight YOLO26 to possess intelligence rivaling that of giant models.
3. Integrated Multi-task Framework
YOLO26 supports five core vision tasks through a single backbone and has integrated specialized modules for each task.
- Object Detection: Utilizes an anchor free and end to end NMS free approach.
- Instance Segmentation: Generates sophisticated mask boundaries by combining a Multi scale Proto Module with semantic segmentation loss.
- Pose/Keypoints Estimation: Manages the uncertainty of complex joint positions by integrating Residual Log likelihood Estimation (RLE) techniques.
- Oriented Detection (OBB): Achieves precise detection of rotated objects through the application of specialized Angle Loss.
- Classification: Supports ultra fast classification via a high efficiency head based on ImageNet.
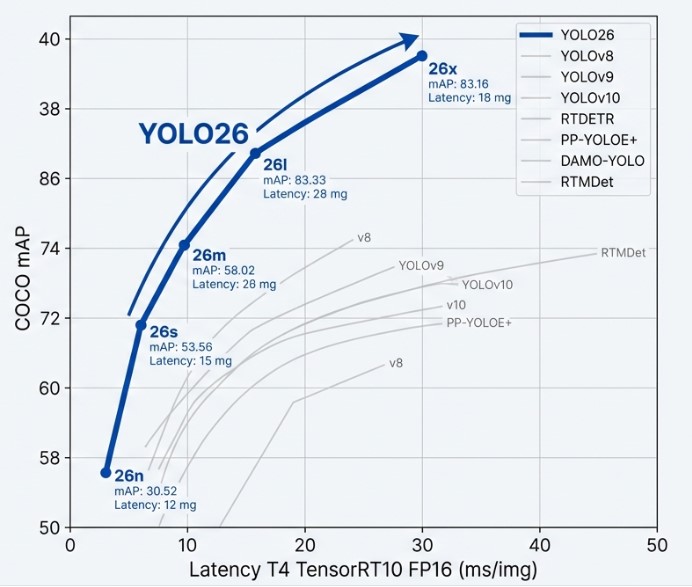
4. Performance Benchmarks: An Overwhelming Balance of Speed and Accuracy
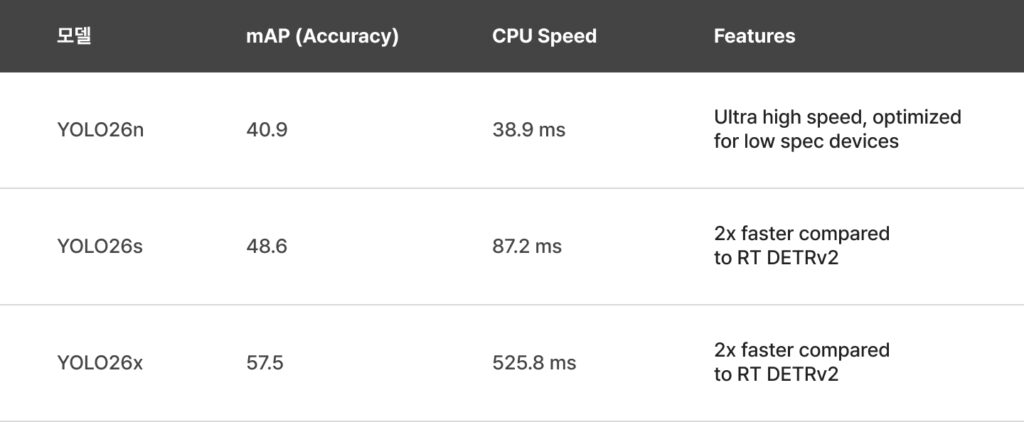
The fact that YOLO26 is not just a successor in name only becomes clear when compared to its predecessor, YOLO11. Focusing on the Nano version, the lightest model in the lineup, YOLO26 achieves higher accuracy while running more than 40% faster than YOLO11. This is akin to increasing a car’s engine performance while simultaneously reducing its chassis weight. The ability to run smoothly even on low spec devices like Raspberry Pi is a highly attractive factor for field developers.
When compared to high performance models such as YOLOv12 or v13, the pragmatism of YOLO26 stands out even more. While competitors have introduced a wide array of complex new technologies to boost accuracy, those additions often made the models heavier and difficult to optimize on specific hardware. In contrast, the simplified structure of YOLO26 experiences almost no performance degradation even after quantization for mobile or edge devices, ensuring stable operation in any environment.
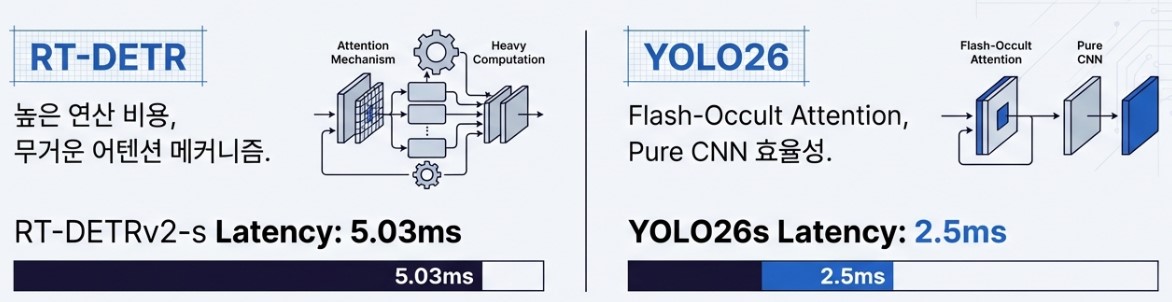
An interesting point of comparison is the battle against recent Transformer based models like RT-DETR. While Transformer models are known for their superior contextual understanding, YOLO26 overwhelms them in terms of speed. It maintains nearly double the processing speed while delivering similar accuracy. Ultimately, rather than chasing complex trends, YOLO26 focused on the fundamentals: Deterministic Latency and Compatibility. In systems like autonomous vehicles where even a 0.01 second delay is unacceptable, guaranteeing a predictable response speed is a more powerful weapon than any flashy feature.
[참고: 모델 성능 요약 (COCO 데이터셋 기준)]
5. Practical Deployment and Industry-Specific Strategies
5.1 Flexible Export and Quantization Strengths
YOLO26 supports all major formats including ONNX, TensorRT, CoreML, and TFLite. Thanks to architectural simplification such as the removal of DFL, the model exhibits low weight sensitivity during INT8 or FP16 quantization, which minimizes precision loss. This prevents conflicts with hardware compilers and enables stable industrial scale deployment.
5-2. Industry Application Scenarios
- Autonomous Driving and Robotics By removing NMS, the model guarantees consistent response times regardless of object density, ensuring stability in real time control systems.
- Smart Factories YOLO26 performs real time defect inspections at over 25 frames per second even on low spec CPU embedded devices, significantly reducing implementation costs.
- Medical and Aerial Imagery Utilizing the STAL algorithm, the model achieves high precision detection of minute objects, such as lesions in X ray images or small targets in long distance drone footage.
Conclusion and Future Outlook: Vision AI Beyond 2026
The emergence of YOLO26 signifies more than a mere version upgrade; it suggests a paradigm shift in object detection from complex computation to intelligent training. Based on this, we can forecast three major directions for the future evolution of the YOLO series.
First is the standardization of End to End architectures. As proven by YOLO26, eliminating cumbersome post processing like NMS has become the most definitive way to achieve both speed and accuracy. Future YOLO models will likely adopt NMS free methods as the default, evolving into fully intuitive models that output correct coordinates immediately upon input without any intermediate steps.
Second is the acceleration of edge device friendly designs. The trend toward lightweight models that can operate in environments without heavy GPUs will intensify. Rather than simply reducing model size, development will focus on adopting simplified operational structures preferred by hardware accelerators (NPUs), as seen in YOLO26, to increase perceived speed. This will act as a catalyst for embedding AI vision across various industrial fields, including robots, drones, and mobile devices.
Finally, we anticipate a phased integration with Vision Language Models (VLMs). While current YOLO models are mostly limited to closed set detection, finding only pre trained objects, future iterations will evolve toward enhancing the efficiency of large scale AI models and understanding language independently.
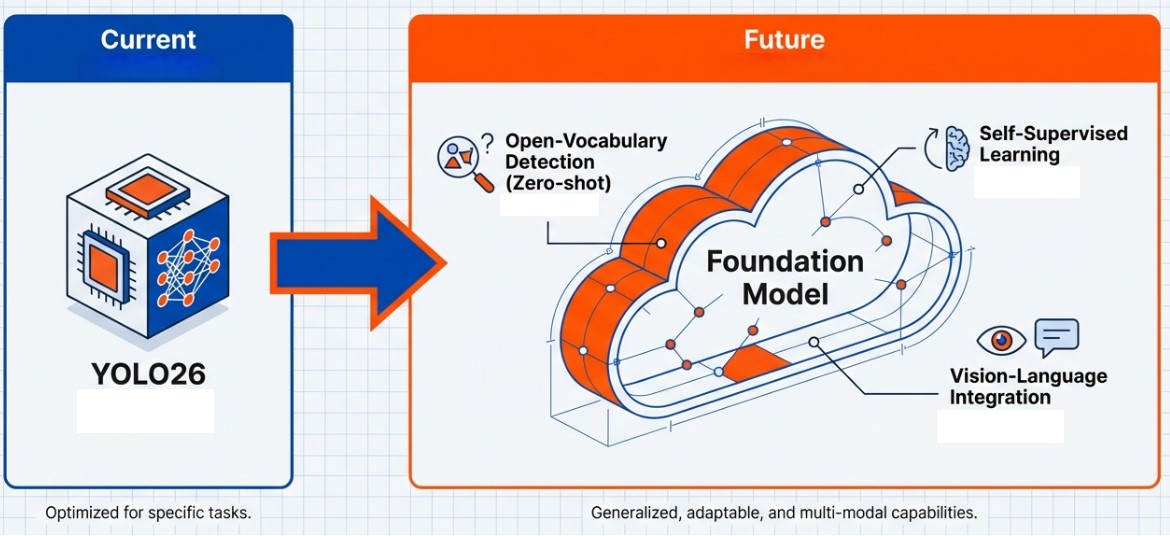
Initially, YOLO will serve as a real time pre filter to drastically reduce the computational load of heavy VLMs. Relying on giant models for all image processing is inefficient in terms of cost and speed. Therefore, a hybrid pipeline will become common, where a fast and lightweight YOLO first filters the locations of objects of interest, and the VLM performs an in depth analysis only on those selected regions. This ensures system wide inference speed while leveraging the advanced recognition capabilities of VLMs.
Looking further ahead, YOLO may evolve into a model possessing its own Open Vocabulary Detection capabilities. This would allow it to find targets immediately based on text commands like “Find the person wearing a red hat” without additional training (Zero shot). To achieve this, intelligent hybrid architectures combining self supervised learning with the strengths of both CNNs and Transformers will be introduced.
Ultimately, YOLO will transcend being a simple object detector to become a universal Vision Foundation Model. Becoming the fast and accurate eyes of large scale AI agents that understand human language and context is the true future of YOLO.



