
For those planning AI technology adoption and research, the recent surge in memory and storage prices has come as a significant shock. Furthermore, with the ongoing supply shortage of high performance GPUs, the barrier to building AI hardware infrastructure is rising daily. In this Hardware Famine, what strategic choices should we make to maximize cost efficiency? The era when simply purchasing the most expensive GPU was the correct answer has passed. Now, we must comprehensively consider model parameter size, memory bandwidth, power efficiency (TCO), and batch performance for multi user processing.
Based on recently released benchmark data and specifications, we will analyze four prominent options in the current market NVIDIA DGX Spark, RTX Pro 6000, RTX 5090, and Mac Mini M4 Pro using actual LLM benchmarks.
Strategic Comparison of AI Hardware Options

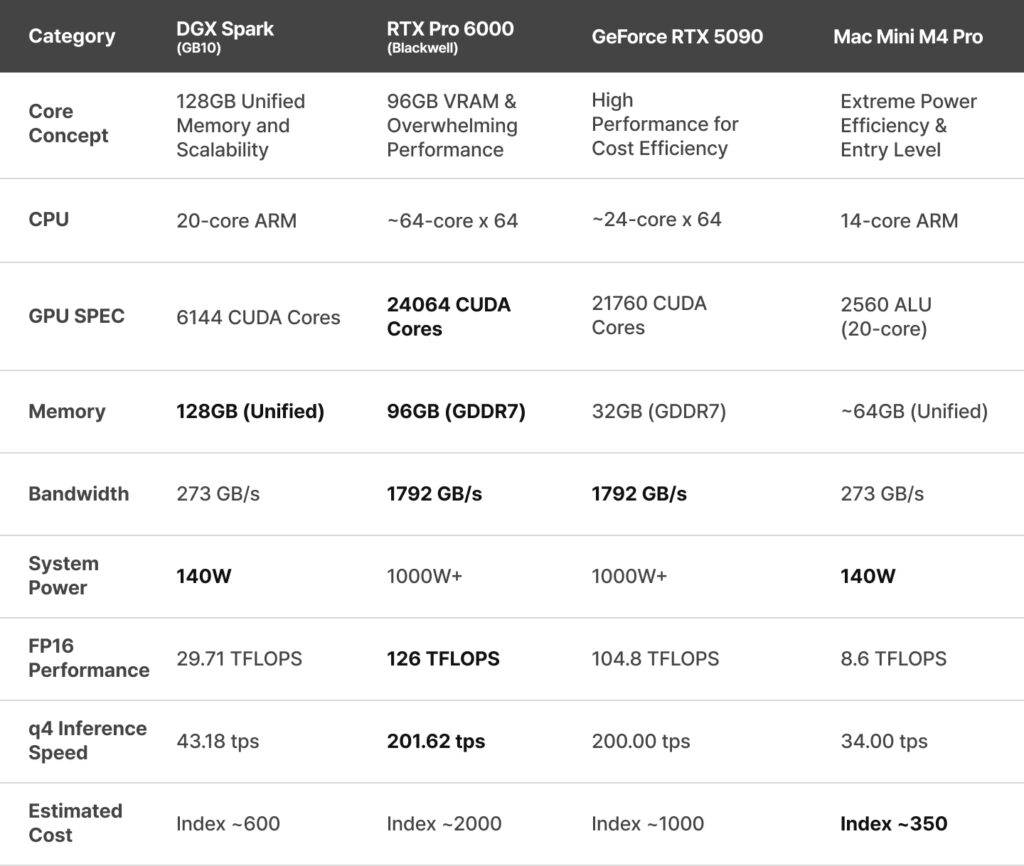
System Class and Character Comparison at a Glance.
1. NVIDIA DGX Spark (GB10): The AI Laboratory on Your Desk for Small Scale Validation
⭕ Advantages: Memory Capacity and Batch Efficiency
- 128GB Unified Memory: As the only small form factor capable of loading massive models of 70B, 100B, or larger into a local environment without quantization, it offers four times the memory of an RTX 5090 (32GB).
- 140W Low Power Consumption: Its minimal power draw makes it the optimal choice for a personal server running 24/7.
- X2 Scalability: By equipping two units and connecting them via a dedicated connector, users can secure up to double the processing speed and memory capacity.
❌ Disadvantages: Single Task Latency
- Bandwidth Limitations: Due to its bandwidth of 273 GB/s, the query response speed (Latency) for a single user is significantly slower compared to the RTX series.
- ARM Architecture: For those wishing to run the latest models without constraints, additional time is required to handle aarch compatible library processing due to the ARM architecture.
2. RTX Pro 6000 Workstation: Enterprise Grade Model Processing Power
⭕ Advantages: Uncompromising Performance
- 96GB GDDR7 VRAM: While approaching the capacity of the DGX Spark, it maintains speeds comparable to the RTX 5090. Its massive bandwidth of 1,792 GB/s allows even large scale models to be processed in an instant.
- 4,000 AI TOPS Class Computing: It possesses powerful computational capabilities perfectly suited for the backends of commercial AI services.
❌ Disadvantages: Cost and Infrastructure
- High Cost and Power Consumption: The initial setup cost is the highest among its class, requiring a 1,000W class power supply and dedicated cooling facilities.
3. GeForce RTX 5090 PC: Rapid Validation and High Speed Personal Inference
⭕ Advantages: Peak Response Speed (Latency)
- Overwhelming Velocity: Recording 200 tokens per second (tps) based on q4 quantization, it offers the fastest perceived response speed for individual users relative to its price.
- Accessibility: Component procurement is relatively easy, and the hardware allows for versatile use, including high end gaming.
❌ Disadvantages: The 32GB Wall
- Model Size Constraints: The 32GB VRAM makes 4 bit quantization mandatory when running 70B models. There is insufficient memory headroom for significant batch processing or large context windows.
4. Mac Mini M4 Pro: The Most Efficient Entry-Level Machine, but Limited to Popular Model PoCs
⭕ Advantages: Cost Efficiency and Accessibility
- Economic Performance with Index ~350: At approximately half the cost of a DGX Spark, users can experience a 64GB Unified Memory environment.
- Respectable Performance: With a bandwidth of 273 GB/s and 140W low power consumption, it achieves a practical speed of 34 tps (based on q4 quantization), making it optimal for beginners or Proof of Concept (PoC) tasks.
❌ Disadvantages: Absence of CUDA and Limited Scalability
- Software Compatibility: It is difficult to fully utilize NVIDIA’s CUDA ecosystem, which may lead to compatibility issues with numerous AI libraries.
🚀Deep Analysis: Batch Processing Performance for Service Scaling
When moving beyond “How fast is it for me? (Latency)” to “How many users can it respond to simultaneously? (Throughput),” the criteria for selection change completely.

💡 Analytical Insights
- The Reversal of DGX Spark
While the single user speed is relatively slow at 28 tps, the throughput surges to 368 tps when the batch size is increased. This suggests that for server purposes where multiple users connect simultaneously or where massive amounts of data must be processed in parallel (Batch Jobs), the DGX Spark can be more efficient than the RTX 5090. - The Supremacy of RTX Pro 6000
It demonstrates a phenomenal throughput of 2,579 tokens per second at a batch size of 32. This level of performance allows for generating answers without latency even when dozens of users ask questions at the same time, making it an essential piece of equipment for commercial services. - The Limitations of RTX 5090
Although it recorded 278 tps at a batch size of 2, it is difficult to significantly increase the batch size due to the lack of VRAM capacity. (Increasing batch size requires substantial additional VRAM for the KV Cache). Consequently, its role is limited to a high performance assistant for 1 or 2 users or for small scale tasks.
🎯 Conclusion: What is the Optimal Choice?
“Budget is limited, but 64GB or more of memory is essential, and you only need to run well known models.”
👉 Mac Mini M4 Pro (Cost Efficient Entry)
“Budget is limited, but you must run or test exceptionally large models. 100GB or more of GPU memory is essential. You need to operate a 24/7 low power server with multi user processing.”
👉 DGX Spark (High Efficiency Server)
“As a single user, peak response speed (Latency) is the top priority.”
👉 RTX 5090 (High End Personal)
“Large scale traffic processing for semi commercial or professional services is required”
👉 RTX Pro 6000 (Enterprise)
The selection of the optimal equipment should be proposed based on whether the goal is Rapid Model Testing and PoC (Latency) or Service for the Masses (Throughput).



