
What would happen if you mounted a 1,000-horsepower Formula 1 engine capable of exceeding 350 km/h onto the frame of a compact city car? The moment the ignition turns on, the chassis would likely collapse under the overwhelming force before the vehicle even begins to accelerate. Without a reinforced structure designed to handle that level of power, catastrophic failure would be almost inevitable.
No matter how extraordinary the engine may be, raw output alone is meaningless without the surrounding systems required to control it. A high-performance engine still depends on a rigid chassis, precise steering mechanisms, and reliable braking systems. Without those foundations, power stops being an advantage and instead becomes a liability. Ultimately, the true differentiator is not the engine itself, but the control architecture that governs how that power is directed and utilized.
The same principle increasingly applies in sports as well. With AI-powered technologies such as LaonPeople’s VTrack launch monitor and SwingEz swing analysis systems becoming more widely adopted, it is becoming increasingly clear that golf performance is not determined by physical strength alone. A player may possess tremendous raw power capable of driving the ball extraordinary distances, but if the grip is unstable or the club path cannot be precisely controlled at impact, the ball will still slice helplessly toward the OB line.
Having power is not enough. Without mechanisms capable of delivering and controlling that power with precision, consistent results become impossible. In the end, performance is defined not by output alone, but by control, structure, and the intelligence behind them.
Powerful AI Still Needs a Chassis
The state of AI in 2026 looks remarkably similar.
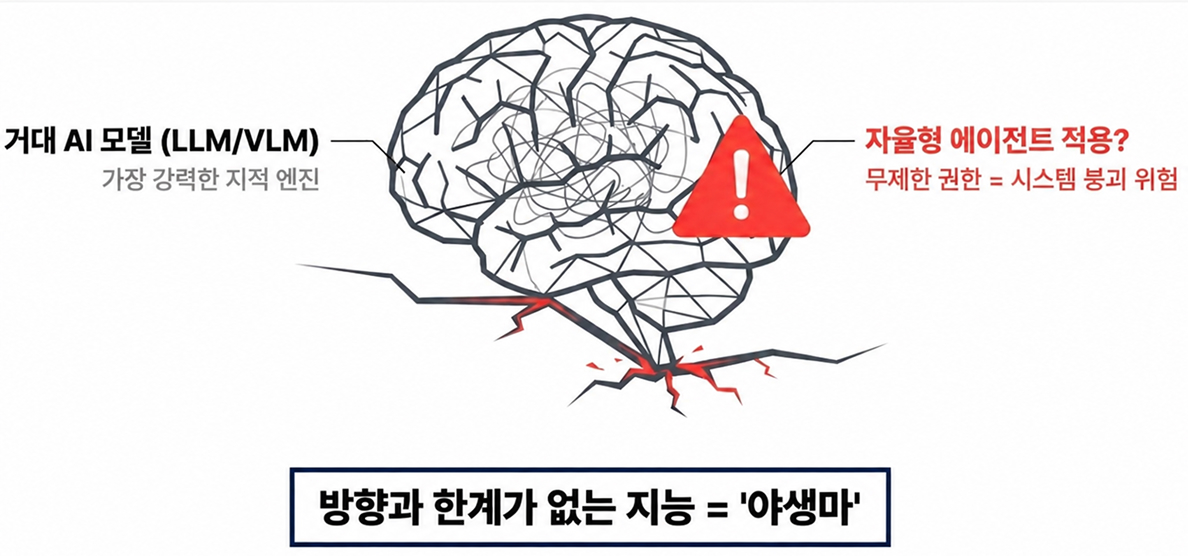
Large Language Models (LLMs) and Vision-Language Models (VLMs), now operating far beyond the scale of GPT-4 with hundreds of billions of parameters, have become some of the most powerful intellectual engines humanity has ever built. Their ability to analyze complex problems, reason across massive knowledge domains, and interact naturally with humans is already approaching a level that feels astonishingly mature.
But this raises a far more important question: what happens when intelligence this powerful is deployed directly into real-world systems without equally sophisticated control structures around it?
Modern AI is no longer limited to passive question answering. Autonomous AI agents are now capable of setting goals independently, calling external APIs, interacting with enterprise systems, and even operating industrial infrastructure with minimal human intervention. Granting these systems unrestricted authority without proper safeguards may ultimately become a dangerous architectural decision.
No matter how advanced the model becomes, hallucinations and reasoning failures still cannot be eliminated entirely. And within autonomous agent environments, a mistaken judgment no longer remains a harmless text-generation error. It can escalate into real-world actions such as deleting files, modifying configurations, transmitting sensitive information externally, or triggering unintended operations that compromise the reliability of entire systems.
In many ways, today’s frontier AI models resemble extraordinarily powerful race engines without fully developed control systems around them. Their capabilities are undeniably impressive, but without carefully designed governance frameworks, operational constraints, and alignment mechanisms, that intelligence can quickly become unstable.
The real challenge facing AI in 2026 is no longer intelligence itself. It is whether we can build the structural “chassis” capable of safely directing that intelligence toward reliable and trustworthy outcomes. Without that layer of control, even the most advanced AI systems may accelerate far beyond the boundaries we originally intended.
The Rise of Harness Engineering
This is precisely where one of the most important architectural ideas of 2026 begins to emerge.
As AI systems become increasingly autonomous, engineers and platform architects around the world are shifting their focus toward a new technical discipline designed to keep these powerful models operating safely and predictably in real-world environments. If modern AI resembles a powerful but untamed race engine, then what the industry now needs is the equivalent of a harness: a structural system capable of guiding that intelligence within controlled boundaries.
This emerging discipline is known as Harness Engineering.
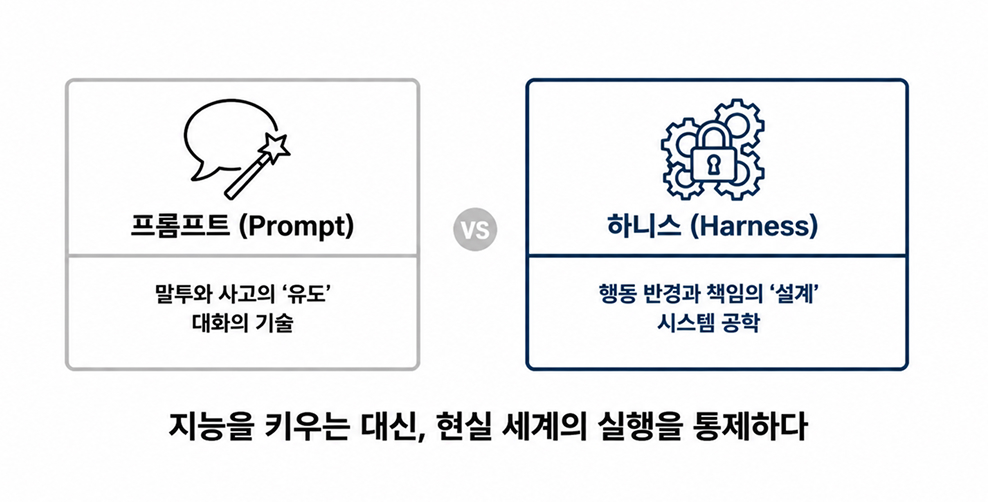
Harness Engineering is not simply about writing better prompts. It is a far broader engineering philosophy centered on defining what an AI system is allowed to do, how far its authority extends, and how the surrounding infrastructure should respond when unexpected behaviors or failures occur.
In other words, the focus is no longer solely on making models smarter. The greater challenge is building robust operational frameworks that allow that intelligence to function responsibly, reliably, and safely within real-world systems.
This marks a major shift in AI architecture. The future is no longer just about designing prompts. It is about designing the harness itself.
And in the era of autonomous AI agents, this may become one of the most critical technological transitions organizations must understand and prepare for.
The Evolution of AI Control Architectures
This naturally leads to another important question:
Why has the relatively unfamiliar term “Harness” suddenly emerged as one of the defining keywords of the AI industry in 2026?
The concept began gaining serious attention through discussions led by Mitchell Hashimoto, the co-founder of HashiCorp, a company widely recognized for its infrastructure automation and developer tooling. While sharing lessons learned from deploying autonomous AI agent systems, Hashimoto highlighted a growing realization within the industry:
making models smarter was no longer the hardest problem. Designing systems that prevent agents from making dangerous mistakes had become even more important.
That perspective quickly resonated across the broader AI ecosystem and gradually evolved into what is now being formalized as Harness Engineering.
To fully understand why this shift matters, however, we first need to step back and examine how AI systems themselves have evolved over the past several years. Harness Engineering did not emerge in isolation. It is the result of a broader progression in how humans interact with, guide, and ultimately control increasingly autonomous AI systems.
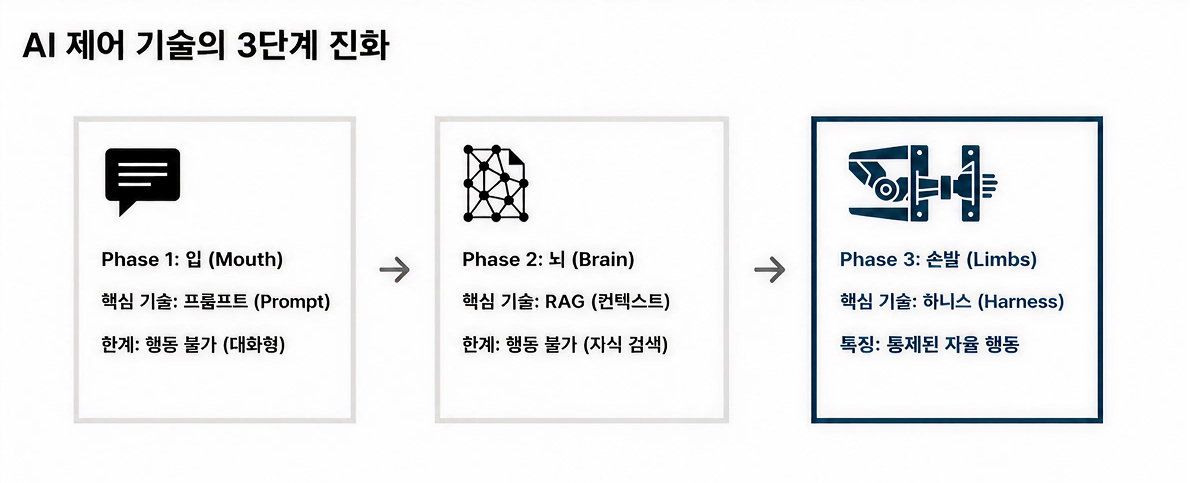
Phase 1. Prompt Engineering: “How Should We Talk to AI?”
When early versions of ChatGPT first emerged, the dominant discipline in AI interaction was undoubtedly Prompt Engineering. At the time, nearly all attention revolved around a single question:
“How should we phrase our instructions to get the outputs we want from AI?”
Users began assigning roles to models:
“You are a veteran marketer with 20 years of experience.”
Others experimented with reasoning guidance prompts such as:
“Please think step by step before answering.”
During this era, Prompt Engineering functioned less like software architecture and more like the art of conversation. The goal was to draw out the most useful responses from the vast reservoir of knowledge and pattern recognition already embedded within the model. Much of the focus centered on shaping the AI’s tone, reasoning flow, and style of interaction.
But despite how powerful these systems appeared, AI at this stage still remained fundamentally passive. It could generate language, but it did not take actions. It did not execute tasks independently, interact with external systems, or carry operational responsibility for real-world outcomes.
Phase 2. Context Engineering & RAG: “What Information Should AI Be Allowed to Read?”
As Prompt Engineering matured, its limitations quickly became impossible to ignore. AI models lacked access to real-time information, internal organizational knowledge, and proprietary documents. As a result, hallucinations, responses that sounded convincing but were factually incorrect, became one of the industry’s most persistent challenges.
To address this problem, a new architectural approach emerged: Context Engineering, along with its most widely adopted implementation, Retrieval-Augmented Generation (RAG).
Under this framework, AI systems no longer generated responses purely from their pretrained knowledge. Instead, before producing an answer, the model would first retrieve relevant information from sources such as internal wikis, enterprise documentation, databases, or up-to-date reference materials, then use that retrieved information as contextual grounding.
In essence, the industry began telling AI something fundamentally different:
“Do not answer freely from imagination. Answer only from the information contained within these documents.”
At this stage, AI was still primarily speaking rather than acting. However, the scope and foundation of its responses were becoming increasingly controlled. By constraining where knowledge could originate, organizations aimed to improve reliability and factual accuracy.
Even so, this approach still carried a major limitation.
The AI still did not act.
Phase 3. Harness Engineering: “How Do We Control AI’s Actions?”
By 2026, AI had evolved far beyond the confines of a simple chat interface. Models were no longer limited to generating responses inside a text box. AI agents had begun searching the web on behalf of users, editing spreadsheets, analyzing server logs to identify system failures, and in some cases even modifying and deploying code autonomously.
At that point, the nature of the problem changed fundamentally.
The moment AI transitioned from a system that merely talks into one capable of taking real-world actions, prompts and contextual grounding alone were no longer sufficient.
Before an AI agent executes a command-line operation, the system must verify whether that action is authorized. If the outcome deviates from expected behavior, the operation must be capable of being halted, rolled back, or isolated automatically. Every action and execution log must also remain traceable for auditing and validation purposes.
This is no longer simply a problem of conversational design.
It becomes a systems engineering challenge involving execution environments, permission management, validation layers, operational safeguards, rollback strategies, and runtime governance.
The structure responsible for managing all of this is what we now call the Harness. And the architectural discipline focused on designing these control frameworks is known as Harness Engineering.
Put simply, the evolution of AI can now be understood as a progression across three distinct stages:
“If Prompt Engineering was about shaping the way AI speaks and reasons,
Harness Engineering is about defining the boundaries of its actions and responsibilities.”
As AI systems grow more powerful, the central challenge is no longer intelligence alone. What matters increasingly is how that intelligence is constrained, governed, and directed to operate responsibly within real-world environments.
This is precisely why Harness Engineering has emerged not as an optional layer, but as the inevitable next stage in the evolution of AI systems.
Why 99% Accuracy Becomes Meaningless in the Real World
Minor mistakes from everyday chatbots, whether in poetry, translation, or casual conversation, are usually harmless. But the equation changes completely when autonomous AI agents are deployed into mission-critical industrial environments or enterprise systems.
Consider a smart factory production line or an intelligent video surveillance system responsible for public safety. What happens if a VLM (Vision-Language Model)-based monitoring agent hallucinates and mistakes reflected light for sparks from a fire? A traditional chatbot might simply output the sentence: “A fire has been detected.” But an AI agent with operational authority could interpret that hallucination as reality and immediately shut down factory power systems or activate sprinklers automatically.
From the AI’s perspective, it was performing a perfectly rational action based on what it believed to be true. In the physical world, however, the consequences could escalate into large-scale production downtime, damaged equipment, and massive material losses.
This is why, in industrial environments, 99% accuracy is not considered reassuring. In practice, it often translates to: “One out of every hundred decisions may catastrophically fail.” And in real-world operational systems, even a 1% failure rate can be unacceptable. At that point, benchmark scores and parameter counts provide very little comfort.
What truly matters is not merely reducing error rates, but structurally preventing model failures from escalating into physical or operational disasters.
This is precisely why experienced AI architects have begun shifting their attention beyond the model itself. The critical question is no longer “How intelligent is the model?” but rather: “What happens when the model is wrong?”
That is the real reason Harness Engineering has become essential.
Harnesses are not built on the assumption that AI is perfect. They are built on the assumption that AI will inevitably make mistakes. Their role is to contain those mistakes before they propagate into dangerous actions by introducing layered validation, permission control, execution boundaries, rollback mechanisms, and operational safeguards.
In other words, Harness Engineering is what transforms AI agents from experimental prototypes into trustworthy production infrastructure.
The Four Core Architectural Layers of Production-Grade AI Agent Harnesses
So what does a trustworthy harness architecture actually look like in real-world deployment environments?
As of 2026, when we examine high-performance local and hybrid AI agent systems such as Anthropic Claude Code or OpenClaw, a remarkably consistent architectural pattern begins to emerge.
These systems are not built as simple chains of model calls. Instead, they resemble finely engineered mechanical systems, more like a Swiss watch than a conventional chatbot pipeline, with multiple interlocking layers operating together in tightly controlled coordination.
Most production-grade agent harnesses that have proven reliable in real operational environments tend to revolve around four critical architectural layers.
① Tools & Action Layer: “Safe Limbs for AI Agents”
This layer serves as the standardized gateway through which an AI agent interacts with the outside world.
Its core principle is straightforward: the agent itself must never gain unrestricted access to critical system resources. Instead, every action must pass through explicitly controlled tools defined by the harness architecture.
For example, when an agent needs to read a file, it is not allowed to access the file system directly. Rather than opening arbitrary system paths on its own, the harness exposes a tightly scoped interface such as read_file(path).
Before executing the request, the harness validates whether the requested path falls within approved sandbox boundaries and complies with predefined security policies. Only after those checks pass does the system return safe results back to the agent.
In other words, the agent may express intent, such as “I want to access this file,” but intent alone never guarantees execution.
Actual execution authority always remains under the control of the harness.
② State & Memory Layer: “The Hippocampus of AI”
Real-world workflows do not unfold in a single interaction.
Analyzing error logs, tracing related code, applying fixes, and validating outcomes often involve dozens of intermediate states and decision points. If an agent forgets what it verified just moments earlier, operational consistency collapses almost immediately.
For this reason, production-grade harness architectures treat state and memory as explicit system design concerns rather than secondary implementation details.
In most advanced agent systems, memory is typically divided into two categories:
- Short-Term Memory (Session State): The immediate context surrounding the current workflow, recent decisions, and active reasoning steps.
- Long-Term Memory (Persistent Memory): Historical task records, learned behavioral patterns, and externalized knowledge stored in vector databases, file systems, or persistent memory stores.
Importantly, sophisticated harness systems do not preserve all context indefinitely.
Irrelevant logs, duplicated outputs, and low-value intermediate states are periodically compressed, summarized, or discarded altogether. This is not merely a performance optimization strategy designed to reduce token usage or computational cost.
In practice, it functions more like a navigational system for cognition itself, continuously preventing the agent from drifting away from its primary objective amid an ever-growing sea of information.
③ Verification Loop: “A Self-Correction System for AI”
Many practitioners consider this layer the true core of modern harness architecture. The critical principle is simple: even if an agent decides on an action, that decision is never executed immediately.
In production-grade systems, every generated output, whether code, commands, configuration changes, or operational decisions, must first pass through a dedicated verification layer before execution is permitted.
These validation procedures are typically highly mechanical, deterministic, and explicit. Common examples include:
- Syntax validation through local linters
- Execution checks using test suites or simulation environments
- Risk pattern detection through rule-based filtering systems
If errors, unsafe behaviors, or logical inconsistencies are detected during this stage, the harness immediately halts execution and returns the failure feedback directly back to the agent itself.
For example:
“An infinite loop was detected in the generated code.”
“This command conflicts with assumptions established in a previous step.”
Through this iterative feedback loop, hallucinations and faulty reasoning are intercepted before they can propagate into real-world actions.
④ Constraints & Guardrails: “The Final Safety Layer”
The final layer is often the most conservative, yet also the most critical.
Its role is straightforward: explicitly block actions that must never be permitted under any circumstances.
Examples include:
- Irreversible commands such as deleting entire file systems
- Attempts to escalate administrative privileges or disable security controls
- Direct access to sensitive system paths or protected information
Even if the agent presents reasoning that appears logically sound, these operations are blocked at the hardcoded policy level before execution can occur.
In some environments, safeguards extend beyond software restrictions altogether, requiring physical isolation mechanisms or mandatory Human-in-the-Loop approval before sensitive actions are allowed to proceed.
Importantly, this layer does not exist because organizations “distrust” AI agents.
In reality, it exists because reliable operational deployment is impossible without it.
In production environments, what matters most is not simply whether a system usually works correctly, but whether it remains safe even in worst-case failure scenarios.

실행 루프의 전체 그림 ‘Agent = Model + Harness’
When we step back and connect all of these architectural layers together, a remarkably clear principle emerges at the heart of modern AI agents:
Agent = Model + Harness
No matter how intelligent a model becomes, intelligence alone is not enough to create a true agent. A model is ultimately just a reasoning engine, a brain capable of receiving inputs and generating outputs. By itself, however, it has no reliable mechanism for interacting safely with the real world, validating its own actions, or controlling the consequences of failure.
To become an actual agent, another layer is required: the harness. The harness acts as the operational system that translates model reasoning into controlled real-world execution.
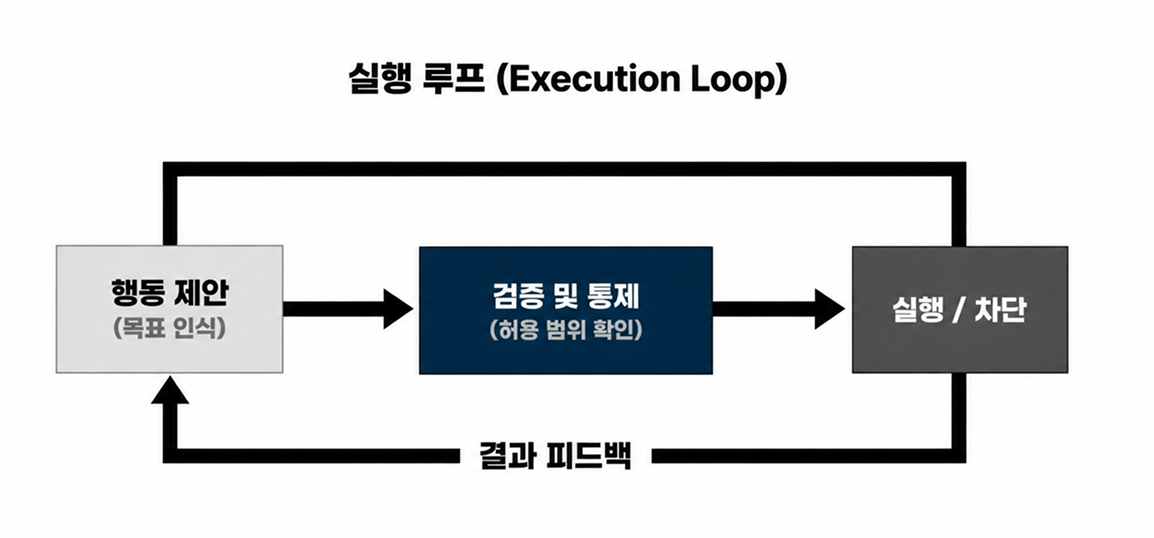
This division of responsibility becomes most visible inside the agent execution loop itself:
- Model (Reasoning): Interprets goals, analyzes context, and proposes actions.
- Harness (Execution & Control): Validates those proposed actions, checks permissions and safety boundaries, decides whether execution should proceed or be blocked, and then feeds the results back into the model.
The true power of this architecture lies in its tolerance for imperfection. Harnesses are not designed around the assumption that models will always be correct. Instead, they are built around the expectation that models will sometimes fail. Their purpose is to ensure that mistakes do not escalate into catastrophic outcomes.
Through layered guardrails, verification loops, execution constraints, and rollback systems, failures are transformed from disasters into manageable operational events.
Equally important, harness architectures introduce model independence. When more capable models emerge, organizations can replace the “brain” without fundamentally redesigning the surrounding operational infrastructure. As long as the harness remains stable, system behavior, governance, and safety characteristics remain largely intact.
This is precisely why, by 2026, competitive advantage has increasingly shifted away from simple model selection and toward harness design itself.
Ultimately, the importance of Harness Engineering is surprisingly straightforward. Its purpose is not merely to invent smarter intelligence. Its purpose is to make intelligence operationally trustworthy in the real world.
AI Dominance Is Shifting from Models to Systems
The competitive landscape among global technology companies has already entered a new phase. The race to build larger and more powerful models still matters, but it is no longer the factor that ultimately determines success.
The real battleground has shifted toward a far more difficult question:
“How reliably can imperfect AI operate inside the complexity of the real world?”
In other words, competitive advantage is moving away from the model itself and toward the harness surrounding it. What now determines business success is whether an organization can design a system capable of surviving unpredictable real-world conditions, incomplete data, changing environments, human intervention, cascading failures, and operational uncertainty.
This is precisely why infrastructure companies, MLOps platforms, and enterprise AI vendors are increasingly focusing on combining AI agents with robust operational architectures. It is also why AI can now be integrated into extraordinarily high-risk domains such as drug discovery pipelines and industrial automation systems.
These deployments are not succeeding because the underlying models are perfect.
They are succeeding because the surrounding harness architectures were designed from the beginning under the assumption that models are inherently imperfect.
In this context, when companies today proudly claim:
“We built the best AI agent,”
what they are often really saying is this:
“We built a rigorously engineered harness capable of preventing a wild, unpredictable model from causing failures in real industrial environments.”
The era of persuading AI through increasingly clever prompts is gradually fading. Replacing it is not blind optimism about the power of intelligence, but an engineering mindset grounded in the recognition that intelligence itself has limits.
Today, building systems that safely contain imperfect AI matters far more than simply building AI that sounds intelligent.
Harness Engineering is not a passing trend. It is the inevitable evolutionary step required to move AI beyond research labs and into the core infrastructure of society itself.
And at the center of this transition stands not the “wizard” obsessed with ever-larger models, but the engineer capable of designing precise systems of control, validation, and operational safety.
So perhaps the most important question we should leave ourselves with is this:
“How strong is the harness surrounding the AI currently operating inside your business?”



