
We are living in the era of “bigger is better” AI.
Every day, massive large language models (LLMs) with hundreds of billions of parameters continue to break new records, outperforming humans across increasingly complex tasks. But the moment we try to deploy these impressive models into real-world environments, we run into a harsh reality.
There is a massive gap between heavyweight AI models designed for cloud infrastructure and the physical limitations of edge devices such as smartphones, autonomous drones, and industrial vision cameras. This gap is often referred to as the Deployment Chasm.
No matter how intelligent an AI model may be, it remains only half a revolution if it cannot operate reliably in real time at the edge.
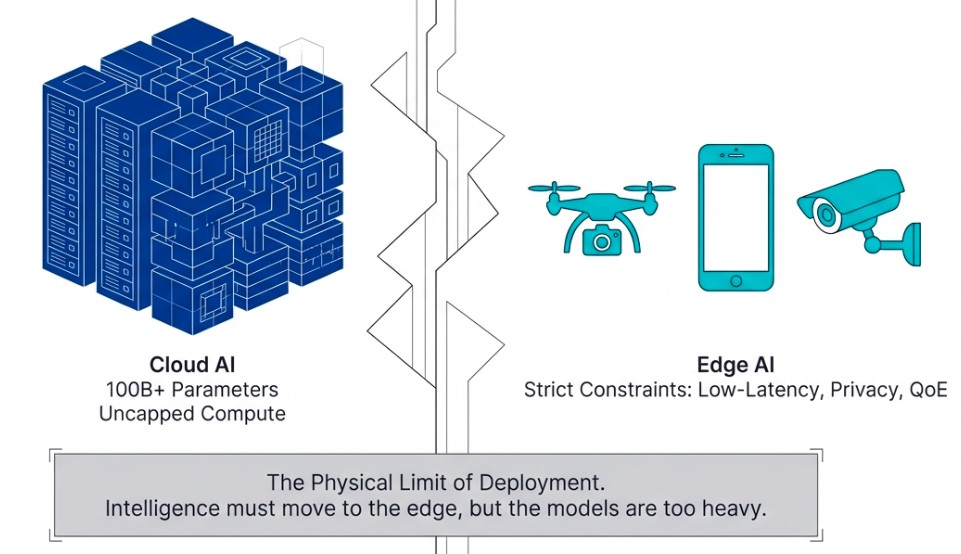
The market is already shifting in response to this challenge. The mobile edge computing market is expected to grow nearly tenfold, from $1.65 billion in 2024 to $13.5 billion by 2032. Ultra-low latency for instant decision-making, privacy protection through on-device processing, and uninterrupted quality of experience (QoE) are no longer optional features. They are becoming fundamental requirements for survival.
As a result, model compression has emerged as one of the most critical strategies in modern AI system architecture. The question is no longer whether powerful models can be built, but how efficiently they can be compressed and deployed.
Among the many approaches to lightweight AI optimization, one technique has emerged as both elegant and remarkably effective: Knowledge Distillation (KD).
A compelling example came from DeepSeek-R1-8B, which drew significant attention across the AI industry last year. By transferring the reasoning capabilities of a massive 685B-parameter teacher model into a compact 8B student model, DeepSeek achieved performance that rivaled or even surpassed much larger 235B-class models.
This demonstrated that knowledge distillation is far more than simple parameter reduction. It is a sophisticated process of extracting and transferring the core intelligence of large-scale models into smaller, highly efficient architectures.
For edge AI environments where hardware resources are severely constrained, such high-efficiency compression techniques are becoming one of the most practical paths toward deploying high-performance AI systems in the real world.
Fitting a Giant Brain into a Tiny Chip: Understanding Knowledge Distillation
It is already well known that large language models consume enormous computational resources and power in cloud environments. However, bringing this intelligence into edge devices requires a completely different optimization strategy.
At first glance, one might assume that simply training a smaller model from scratch for edge deployment would solve the problem. In reality, this is like handing a child hundreds of advanced physics textbooks and expecting them to independently master quantum mechanics.
The learning efficiency is poor, and the ceiling of achievable intelligence becomes severely limited.
Knowledge distillation was introduced to overcome this limitation.
The idea is surprisingly intuitive. A large pretrained model with extensive knowledge becomes the teacher model, while a lightweight model intended for deployment on edge devices becomes the student model.
Rather than forcing the student model to learn entirely from raw data, the teacher guides the student by transferring its learned understanding of data distributions, reasoning patterns, and contextual relationships.
In other words, the student model does not merely memorize answers. It learns how the teacher thinks.

This transfer process relies heavily on what researchers call soft labels.
Traditional AI training uses hard labels, where the model is told that an image is definitively a cat or definitively a dog. But teacher models contain much richer probabilistic information beneath those final predictions.
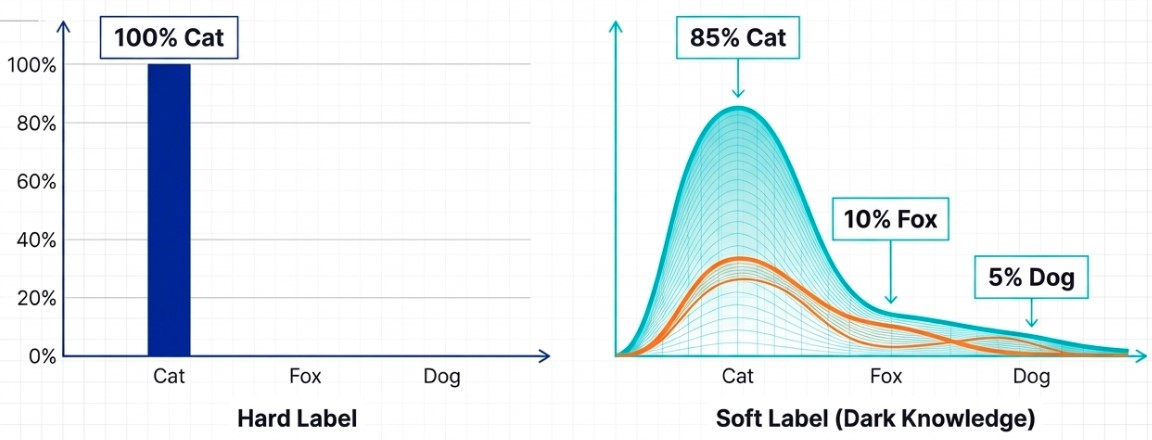
A teacher model may recognize that an image is highly likely to be a cat, while also understanding that certain features share similarities with dogs. These subtle probability distributions carry valuable structural information about the data itself.
Researchers refer to this hidden information as Dark Knowledge.
Through knowledge distillation, the student model absorbs these nuanced relationships instead of simply memorizing correct answers. It learns the fine boundaries between classes, hidden correlations within data, and the reasoning behavior of the teacher model itself.
It is similar to an apprentice learning not only the final brushstroke of a master painter, but also the precise pressure, timing, and movement behind it.
This becomes especially powerful in edge AI environments.
Industrial machine vision cameras operating on high-speed production lines must detect defects within milliseconds. Autonomous drones must make real-time decisions under unpredictable conditions. Yet these devices lack the memory capacity, computational power, and energy budget required to run massive AI models directly.
Knowledge distillation changes that equation.
By inheriting the reasoning structure of the teacher model, lightweight student models can achieve surprisingly high accuracy while operating with far fewer computational resources.
Ultimately, knowledge distillation allows the massive parameter count of large models to remain in the cloud while transferring only the essential reasoning intelligence to edge devices.
This is precisely why compact models like DeepSeek’s 8B architecture were able to outperform much larger systems through highly optimized knowledge transfer and compression efficiency.
The Alchemy of Dark Knowledge: Temperature Scaling and Optimization
For student models to fully absorb the intelligence of teacher models, hidden probabilistic information must first be revealed.
This is where one of the most important mechanisms in knowledge distillation comes into play: the temperature parameter (T).
Teacher models generate raw prediction values called logits, which are converted into probability distributions through the Softmax function.
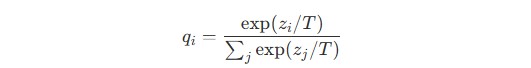
Under normal conditions, AI models operate with T=1, producing extremely sharp probability distributions that heavily favor the correct answer. However, increasing the temperature softens the distribution, exposing the relative probabilities of alternative predictions.
This process allows student models to learn not only what the answer is, but why other possibilities remain partially plausible.
In industrial machine vision systems, for example, a teacher model may classify a defect as a scratch with 85% confidence while simultaneously recognizing similarities to dust particles or lighting artifacts.
These subtle relationships form the foundation of robust decision-making.
Why does this matter so much for edge AI?
Because it smooths the model’s decision boundaries.
Edge environments are inherently noisy and unpredictable. Lighting conditions shift constantly in manufacturing facilities, and autonomous systems encounter endless unseen variables in real-world environments.
A model trained solely on hard labels often develops brittle decision boundaries, making it vulnerable to failure under unfamiliar conditions.
By contrast, student models trained with dark knowledge inherit smoother and more generalized reasoning behavior, allowing them to respond more flexibly to unseen data.
This improved generalization is one of the key reasons distilled models can perform reliably even under highly constrained edge deployment scenarios.
Capacity Matching: The Strategic Dilemma
However, extracting dark knowledge alone is not enough.
System architects must also solve a critical challenge known as Capacity Matching.
Even the greatest teacher cannot successfully educate a student whose capacity is too limited to absorb the material.
If the student model becomes excessively small for edge deployment, it may lack the representational capacity required to absorb the teacher model’s complex knowledge. On the other hand, increasing the size of the student model undermines the original goal of ultra-lightweight edge deployment.
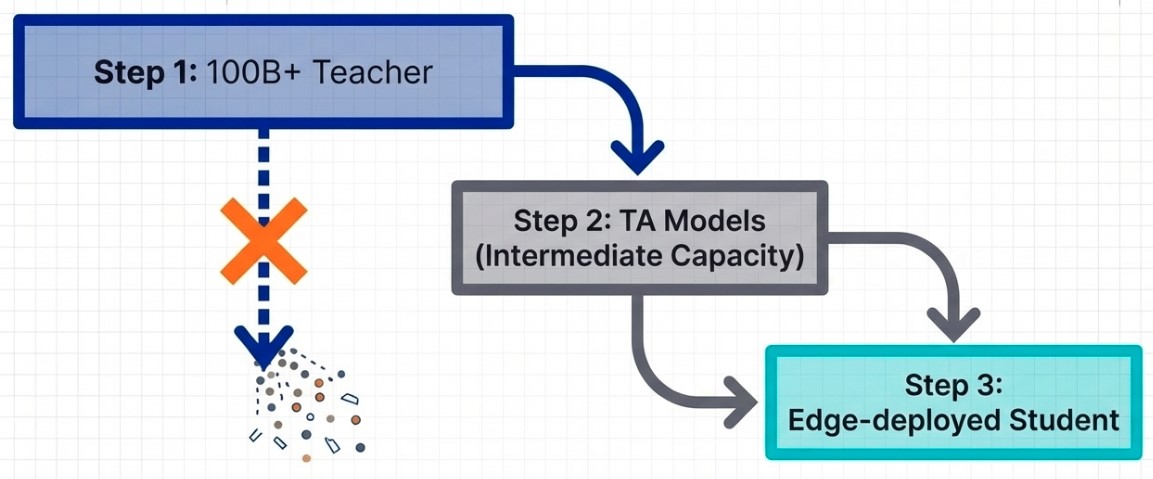
To solve this dilemma, engineers increasingly rely on Progressive Distillation.
Instead of transferring knowledge directly from a massive teacher model to a tiny edge model, intermediate “teaching assistant” models are introduced between them.
Knowledge is distilled gradually through multiple stages, minimizing information loss while enabling extreme compression efficiency.
This staged approach allows sophisticated reasoning capabilities to survive even within highly constrained edge processors and mobile chipsets.
In this sense, knowledge distillation is not merely a compression technique. It is a sophisticated engineering discipline that carefully balances the infinite ambitions of AI software against the physical limitations of hardware.
Prune, Distill, Quantize: Hardware-Software Co-Optimization
In edge AI, algorithmic excellence alone is not enough.
True deployment success requires tight co-design between software intelligence and hardware architecture.
One of the biggest misconceptions in edge AI optimization is focusing solely on computational throughput such as FLOPs. In practice, the real bottleneck often comes from memory access cost.
Moving massive amounts of model data between memory and processing units consumes enormous energy and creates severe bandwidth limitations.
To overcome this challenge, knowledge distillation is commonly combined with two additional optimization techniques:
- Pruning (P)
- Quantization (Q)
Together, these approaches form what many engineers call the PDQ strategy.
Pruning removes less important neural connections to create sparse architectures. Distillation then restores lost intelligence using dark knowledge from the teacher model. Finally, quantization compresses numerical precision from heavy FP32 representations down to INT8 or lower formats, dramatically reducing memory requirements.
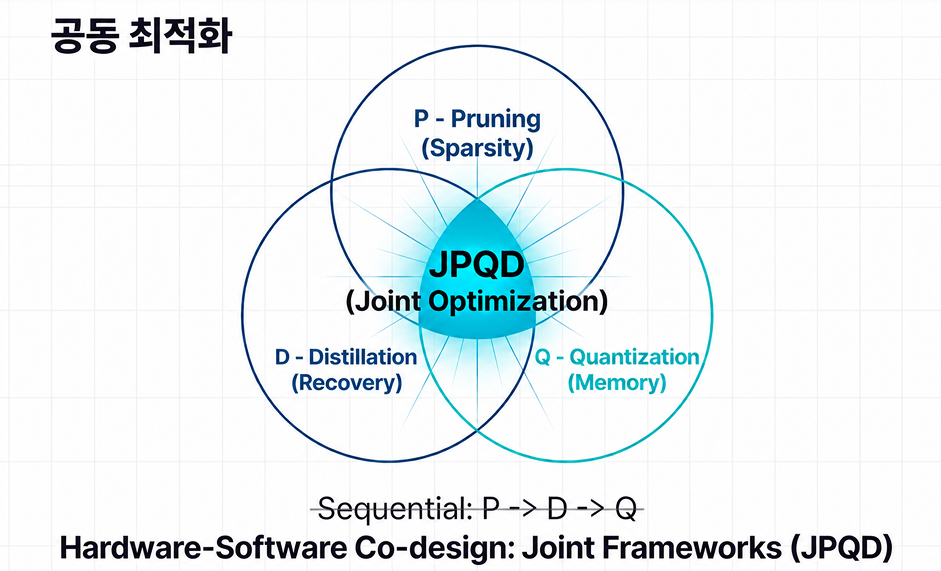
Modern optimization frameworks increasingly perform these processes simultaneously through approaches such as Joint Pruning, Quantization, and Distillation (JPQD).
This enables models to maintain reasoning performance even under aggressive compression.
The final step is hardware calibration.
Different edge accelerators prefer different numerical formats. Google Coral Edge TPU systems rely heavily on strict INT8 quantization, while NVIDIA Jetson platforms support flexible mixed-precision architectures combining FP16 and INT8 operations.
Through these optimization pipelines, models that once required enormous cloud infrastructure can ultimately operate entirely offline on compact edge devices, generating real-time responses directly on-device.
Federated Distillation and the Right to Be Forgotten
As AI agents become increasingly integrated into our personal lives, privacy becomes a defining challenge.
Calendars, conversations, financial records, and health information all represent highly sensitive data. Sending such information continuously to centralized cloud servers creates enormous security and regulatory risks.
This is where Federated Distillation (FD) enters the picture.
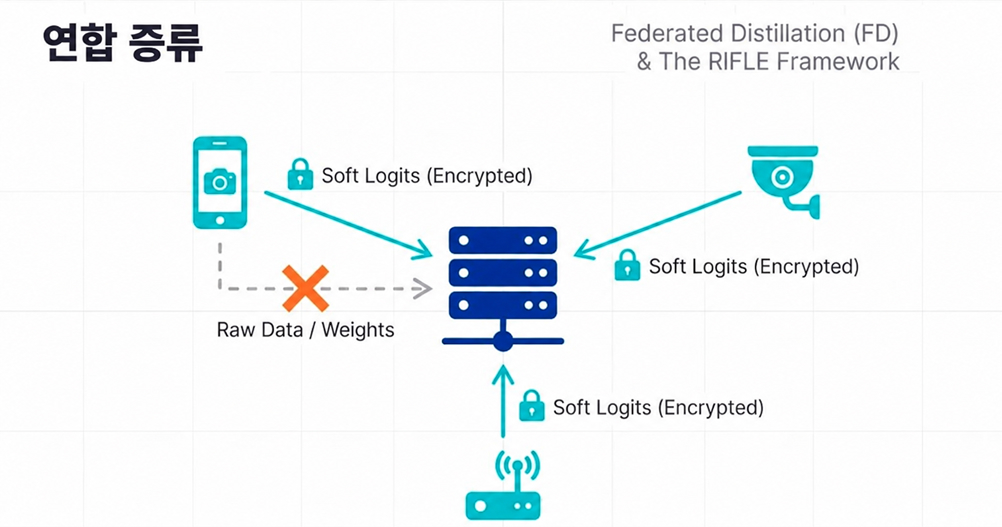
Traditional federated learning approaches exchanged full model weights between devices and servers. But in the era of billion-parameter LLMs, this creates excessive communication overhead and potential privacy vulnerabilities.
Federated distillation takes a different approach.
Instead of transmitting raw model weights, edge devices share only compressed probabilistic outputs such as soft logits.
In simple terms, millions of devices privately learn from their own local data while sharing only distilled “insights” rather than the original information itself.
This dramatically reduces communication cost while significantly improving privacy protection.
Federated Unlearning and the AI Era’s “Right to Be Forgotten”
Privacy protection does not end with secure training.
Users must also retain the right to remove their contributions from AI systems entirely.
Historically, removing a single user’s data from a trained model required retraining the entire model from scratch, an enormously expensive process.
Emerging techniques such as Federated Unlearning (ZeroFU) aim to solve this problem.
Rather than rebuilding the model entirely, these approaches selectively remove the influence of specific users from the trained intelligence itself.
This allows organizations to comply with strict privacy regulations such as GDPR while avoiding the catastrophic cost of full retraining.
Ultimately, knowledge distillation for edge AI is evolving far beyond simple model compression.
It is becoming a foundational technology for building intelligent, privacy-preserving, and ethically deployable AI ecosystems that can operate securely at the edge.
From Smartphones to Industrial VLMs: The Frontline of Edge AI
Lightweight AI models infused with dark knowledge and tightly synchronized with hardware are rapidly moving beyond the boundaries of the cloud and into the most dynamic environments of the real world.
The most immediate transformation is already happening in the devices we carry every day: smartphones and wearables.
Real-time language translation on an airplane with no internet connection, or on-device AI agents capable of managing schedules without sending sensitive personal data to external servers, would have seemed almost impossible just a few years ago. These breakthroughs have only become feasible through the combination of advanced compression techniques and federated distillation architectures discussed earlier.
Edge AI is also becoming mission-critical in robotics and autonomous systems, where environments are unpredictable and response times are measured in milliseconds.
When a high-speed drone or an autonomous mobile robot (AMR) in a factory encounters an unexpected obstacle, there is no time to query a cloud server and wait for a response. The system must recognize the situation, make a decision, and execute an evasive action instantly on-device.
This ultra-low-latency reasoning capability is precisely what highly optimized edge AI models are designed to deliver.
The Peak of Optimization: How LaonPeople Brought Generative AI Surveillance to the Edge with “AI Box”
The true value of edge AI optimization becomes most visible in real-world surveillance environments, where extreme accuracy and real-time responsiveness are non-negotiable.
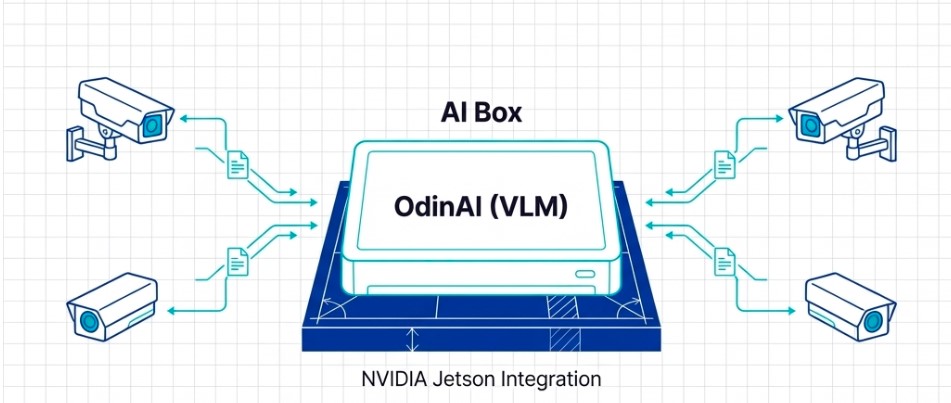
One compelling example is LaonPeople’s AI Box, a system built upon 16 years of expertise in machine vision engineering. More than just another edge device, AI Box demonstrates how sophisticated edge AI architectures can be successfully deployed in demanding industrial environments.
At the center of this system is OdinAI, LaonPeople’s generative AI-based surveillance solution.
To interpret the massive streams of visual data generated by industrial facilities and traffic intersections in real time, OdinAI relies on advanced Vision-Language Models (VLMs) capable of understanding both images and natural language simultaneously.
The challenge, however, was formidable.
How do you deploy a computationally intensive VLM, typically designed for massive cloud GPU clusters, onto a compact edge device operating in harsh field environments?
LaonPeople solved this through extensive optimization and hardware-software co-design.
By carefully tuning the architecture, the company successfully deployed the model entirely on NVIDIA Jetson-based edge hardware. More importantly, the achievement went far beyond simple model compression.
A single edge device was able to process and analyze four concurrent high-resolution video streams in real time, entirely on-device.
This is a textbook example of how hardware-software co-optimization works in practice.
The system architecture combines multiple advanced optimization strategies simultaneously:
- Pruning, to remove unnecessary neural network structures
- Quantization, optimized for the mixed-precision characteristics of the Jetson platform
- Knowledge Distillation, to preserve the reasoning intelligence of large teacher models within compact edge architectures
Through this tightly engineered optimization pipeline, LaonPeople overcame critical memory bandwidth limitations while delivering a fully operational generative AI surveillance system without relying on cloud infrastructure.
As a result, OdinAI has been successfully deployed in intelligent transportation systems (ITS) and smart surveillance environments where real-time decision-making is essential.
Ultimately, this is the true promise of edge AI:
Taking the intelligence once confined to massive cloud servers and compressing it into resilient, highly optimized edge systems capable of solving complex real-world problems directly where the data is generated.
Beyond Compression: The Future of Agentic AI at the Edge
The frontier of AI innovation is no longer confined to massive cloud infrastructure. It is rapidly expanding into the fast, compact, and highly dynamic world of edge computing.
Recent breakthroughs such as Meta’s lightweight Llama 3.2 (1B/3B) models, capable of real-time on-device text processing, and DeepSeek-R1-Distill-1.5B, which successfully transfers powerful reasoning capabilities into mobile-class hardware, represent major milestones in this evolution.
But the true destination of knowledge distillation and edge optimization goes far beyond simple model compression.
The extraction of dark knowledge, hardware-software co-optimization through PDQ strategies, privacy-preserving federated distillation, and even ESG-driven efficiency gains are all converging toward something much larger:
The emergence of Mobile Agentic AI.
These technologies are transforming passive edge devices into intelligent systems capable of perceiving, reasoning, and acting autonomously in real-world environments.
Achieving fully generalized intelligence at the edge may still remain a long-term ambition. Yet the technological foundation supporting that future is steadily taking shape.
LaonPeople’s AI Box powered by OdinAI offers a compelling glimpse into that future.
Even computationally demanding Vision-Language Models (VLMs), once considered impractical outside large cloud environments, are now being optimized to run directly on edge chipsets while performing real-time surveillance and situational analysis.
The so-called Deployment Chasm between hyperscale AI models and real-world edge devices is beginning to collapse.
Knowledge distillation is evolving into something much larger than a compression technique. It is becoming a global intelligence transfer framework, capable of distributing the reasoning capabilities of large-scale AI systems into devices embedded throughout everyday life.
What happens when industrial surveillance systems, autonomous machines, and even the smartphones in our pockets begin to possess the intelligence once reserved for massive cloud infrastructure?
That transformation is already underway.
And as architects standing at the forefront of this shift, we are no longer simply imagining the future of edge AI. We are actively engineering it.



