
When using generative AI like ChatGPT or Claude in work or daily life, we sometimes hit a wall. When asked about the latest information the AI hasn’t learned, it might give nonsensical answers known as Hallucination, or it may struggle to understand complex internal company documents, repeating only superficial responses.
To solve these problems, a technology called RAG (Retrieval Augmented Generation) emerged. Instead of forcing the AI to answer blindly, this method makes the AI first find and read relevant documents and then respond based on that content. It is like taking an exam not by relying solely on memory, but by having a reference book by your side to find the right answers.
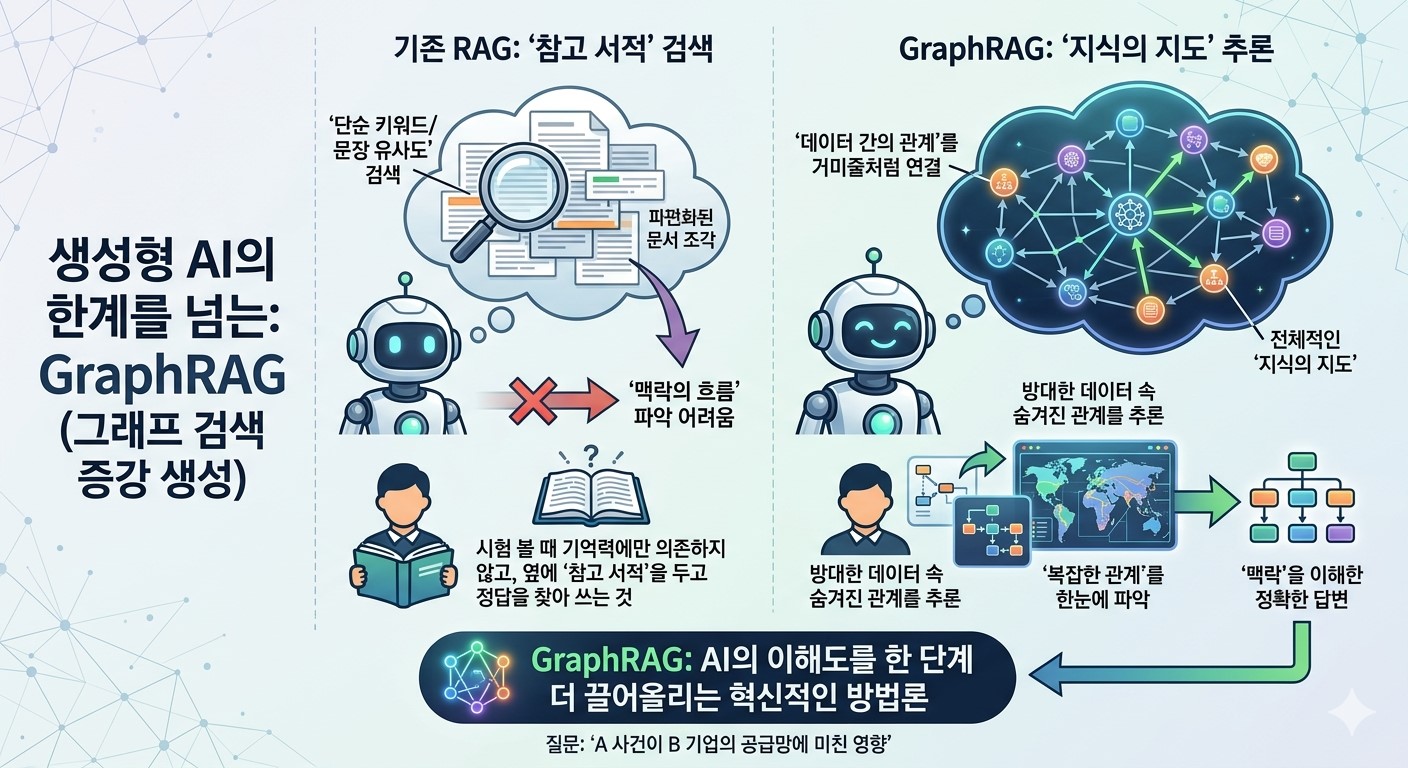
However, as the volume of data grows and the connections between information become more intricate, traditional RAG methods have also begun to show their limitations. This is because it is difficult to grasp the flow of context or complex relationships scattered across multiple documents using only simple keywords or sentence similarity.
For instance, if asked about the impact of Event A on Company B’s supply chain, while traditional RAG might bring back fragmented pieces of documents, GraphRAG connects the relationships between data like a spiderweb and answers by drawing a comprehensive map of knowledge.
In this post, we will look beyond simple search to explore the core principles of GraphRAG, which infers hidden relationships within data, and examine in detail why this is an innovative methodology that takes AI’s level of understanding to the next level.
Why Graph Now?
Traditional RAG stores data by dividing it into meaningful Chunks. For example, if there is a massive 1,000 page novel, it might be saved by cutting it into 300 character segments. When a user asks a question, the AI performs a search to pick up a few chunks containing words most similar to the query, much like grabbing books from a bookstore shelf.
This is where a critical limitation emerges. What if the question is, “How does the protagonist’s psychological state change throughout the entire novel?” The AI would need to simultaneously connect and read fragmented information scattered across pages 15, 465, and 793. However, because the traditional method looks at each chunk separately without knowing the correlations between them, it often misses the overall context of the story.
This is where the Graph enters as a savior. A graph does not stop at simply cutting text; it extracts key elements hidden within the data as points (nodes) and lines (edges) to define organic relationships.
It goes beyond simply noting that Person A appears. It identifies hidden links between chunks, such as Person A is the CEO of Company B, and Company B is currently developing New Drug C, to draw a massive Map of Knowledge in advance. With such a sophisticated map, the AI can follow the lines of relationship to grasp the entire context, even if the pieces of information are far apart.
Ultimately, GraphRAG is an innovative technology that expands RAG from the realm of simple information retrieval into the realm of inference, weaving scattered information together to understand the whole. This is the secret to finding accurate answers without getting lost, even in a labyrinth of information.
Three Key Recipes for Drawing a Graph Map
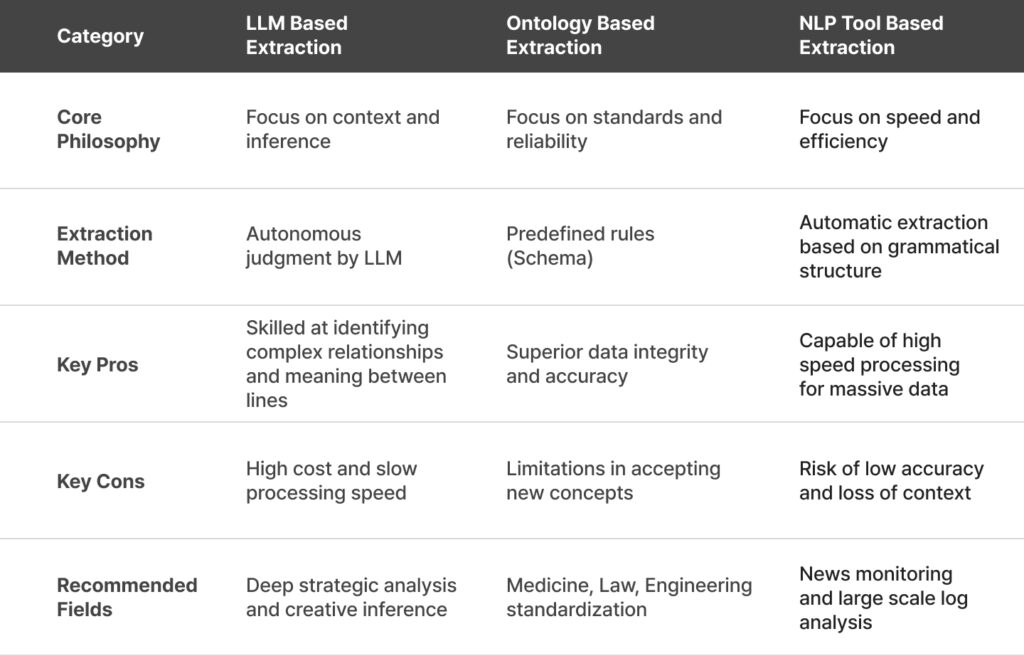
The methods for extracting a sophisticated map called a “Graph” from the raw material of data are largely divided into three categories. Just as the precision and cost of a dish vary depending on the culinary tools chosen, each method possesses its own unique design philosophy.

① LLM-Based Extraction (The Brainy Way): “Having the AI Draw the Map Itself”
Microsoft’s approach has now become an indispensable milestone when discussing GraphRAG. This method is special because it utilizes the AI (LLM) not merely for generating answers, but as an expert capable of identifying complex relationships between data points to draw a map.
A uniquely appealing feature of the MS approach is that it clusters scattered information into “Communities” (villages) and summarizes them. This allows the system to flawlessly answer comprehensive, high-level questions that span the entire dataset, such as “What is the overall atmosphere of this entire community?” It demonstrates a higher level of insight, distinctly different from traditional methods that only looked at individual fragments of information.
- How it works: The LLM carefully reads the entire text and makes its own judgments. For example, upon reading “Nanoparticles perform cancer cell targeting functions,” it actively defines and extracts the relationship: “Nanoparticle (Node) — [performs] → Targeting function (Node).”
- Pros: It is exceptionally intelligent. Even without a human setting specific rules, it captures subtle relationships hidden within the context or the “meaning between the lines.” The greatest charm is its ability to incorporate metaphorical expressions or complex causal relationships into the graph.
- Cons: High intelligence comes with a price. Feeding tens of thousands of pages of documents to an LLM consumes massive token costs and computation time. It is akin to assigning hundreds of PhD-level experts to summarize one book each, creating a significant economic burden when processing large-scale data.
② Ontology-Based Extraction (The Structured Way): “Assembling Information According to a Rigid Blueprint”
This method is the Ontology-Based Extraction, which is akin to building a house according to a fixed blueprint. Here, Ontology refers to a type of data genealogy or a strict classification system. Simply put, instead of gathering information randomly, it is a method of assembling it according to pre-agreed standard specifications and frameworks.
- How it works: An expert establishes strict rules in advance. For example, a guideline is set in stone stating, “Our system only permits nodes for Person, Organization, and Technology, and relationships are limited to Belongs to or Developed by.” The AI then selects and stores only the information that fits this specific blueprint.
- Pros: The purity of the data is exceptionally high. Since everything moves within a set framework, there are fewer errors, and the resulting values are highly refined. This method is essential in specialized fields like medicine, law, and finance, where data reliability and accuracy are paramount.
- Cons: It lacks flexibility. If a new concept or unexpected information not in the blueprint appears, the system fails to recognize it and leaves it out. It is like having a map that only distinguishes between Black and White; when Grey appears, there is no way to represent it.
③ NLP Tool-Based Extraction (The Fast Way): “Clearing a Highway through Mechanical Analysis”
The final method is the NLP Tool-Based Extraction, often called the “Light-speed Automatic Classification System.” While previous methods focused on deep reasoning (LLM) or sophisticated blueprints (Ontology), the core of this approach lies in overwhelming processing speed and efficiency. It is characterized by the mechanical analysis of a sentence’s grammatical structure using traditional Natural Language Processing (NLP) techniques. It is similar to a robotic arm on a conveyor belt instantly categorizing tens of thousands of pouring parts according to a set formula: Subject, Verb, and Object.
This method does not incur the high computational costs of the LLM approach, offering the best cost-effectiveness when massive mountains of documents need to be converted into a graph quickly and affordably. While it may have limitations in identifying complex relationships when contexts are intricate or filled with pronouns (he, it, this, etc.), there is no better ally when you need to grasp the overall outline of data in an instant.
- How it works: It uses algorithms that analyze the grammatical structure of a sentence. From a sentence like “A did B,” it mechanically identifies the subject, verb, and object to immediately generate a Triple system: [Subject] — (Action) → [Object].
- Pros: Overwhelming speed and efficiency. Because it doesn’t engage in deep “thinking” like an LLM, it can convert mountainous data into a graph in a flash at almost no cost. It is optimized for large-scale, real-time data processing.
- Cons: The depth of analysis is shallow. If a sentence becomes slightly complex or uses frequent pronouns like “it” or “this,” the system can easily lose context and get the relationships tangled. While it excels at drawing the overall terrain quickly, one shouldn’t expect the profound insights captured by more advanced methods.
Comparing Graph Extraction Methodologies at a Glance >>
Which “Map” Is Right for Us?
“So, which method should you choose to build a GraphRAG perfectly suited for your company? The answer lies in the nature of the data you possess.
If your data demands deep context such as cutting-edge technical papers or complex business strategies, the LLM based approach is recommended. Even with higher initial costs, the sophisticated insights it provides justify the investment. Conversely, if your format is rigid and requires zero margin for error such as medical records or manufacturing process manuals, then the Ontology based method is the solution. If you simply want to quickly scan a massive news archive to identify trends, the NLP based approach will be the most economical and efficient choice.
This choice is more than just a technical decision; it is a process of determining how the AI perceives the world. While AI in the past spoke based on the statistical probability of words, AI in the GraphRAG era has begun to converse by understanding the causality between data points. When we stop leaving data as meaningless fragments and instead grasp the context of how they are connected, AI intelligence finally takes a leap forward.
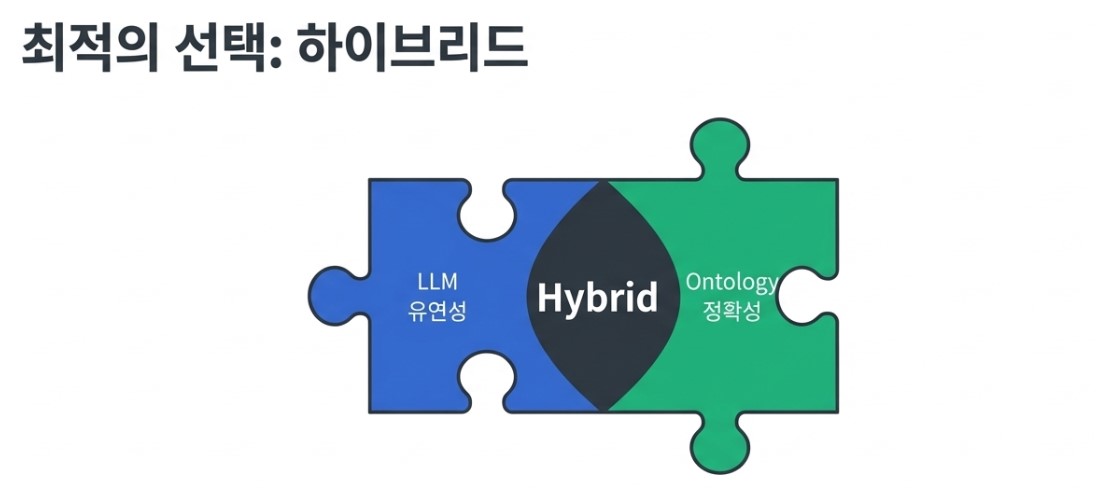
Ultimately, the key lies in how to create more accurate and meaningful connection points. The three methods we explored are not in competition. Recently, hybrid approaches combining the flexibility of LLMs with the accuracy of Ontologies are being actively researched.
In what state is your data sleeping right now? Is it merely cold fragments of text piled up somewhere in a server, or is it a breathing Knowledge Graph organically connected? The journey to making AI perfectly understand your business begins with this very act of Graph Creation.
The Process of Finding Answers Along the Map: 3 Stages of Graph Retrieval
We have previously explored the recipes for drawing a sophisticated Map of Knowledge or Graph from the raw material of data. However, simply drawing a precise map is not enough. Just as a treasure map itself is not the treasure, the process of looking at this map to find where the answer is actually hidden, known as Graph Retrieval, must be performed to complete the AI’s response.
While traditional RAG was similar to simply picking up a similar book from a bookstore shelf, GraphRAG retrieval resembles a skilled detective following clues to understand the full picture of a case. Let us break down that specific process in an easy to understand way.
Graph based retrieval is not merely about matching words; it is a process of following the stems of relationships, and it operates through three major stages.
✅ Step 1: Finding Clues (Entity Linking and Initial Retrieval)
When a user asks a question, the system first identifies the core keywords or entities within that query. For example, if the question is “What are the side effects of Drug A in treating Disease B?”, the system first locates the nodes for Drug A and Disease B within the knowledge graph.
Traditional RAG methods search for text fragments containing Drug A and Disease B much like a search engine. In contrast, GraphRAG directly accesses these predefined nodes, preparing to look down at all the information connected to those specific points at a single glance.
✅ Step 2: Tracking Relationships (Relational Traversal and Subgraph Extraction)
Once the core nodes of the query are identified, it is time to explore the network of relationships extending around them. This is the moment where the true power of the graph is unleashed. The AI does not simply stop at the term Drug A; it begins to gather information related to the query in a three dimensional way by following the edges or lines extending from that node.
First, this process enables the expansion of context. For example, when a user simply asks about the side effects of a new drug, the system traces a logical path: Drug A via Ingredient to Substance X via Reaction to Receptor Y via Induces to Dizziness. Even if words like Receptor or Substance X were not directly mentioned in the query, the AI can unearth hidden causal relationships one after another by following the graph lines, much like pulling up a string of connected vines.
The information gathered leads to the Subgraph Extraction stage, which is optimized for the specific question. From the vast overall knowledge map, the system carves out only the nodes and relationships essential for the current answer to construct a small, customized map. As a result, the AI moves beyond the struggle of piecing together fragmented document scraps seen in traditional RAG. Instead, it holds a single, logically complete context, allowing it to provide much deeper and more accurate responses.
Ultimately, this is a process where the depth of search goes beyond the surface of the text and enters the very structure of knowledge.
✅ Step 3: Grasping Global Context (Community Summarization and Global Search)
The final stage is the process of moving beyond individual elements of the graph to grasp the overall flow. As one of the unique strengths showcased by Microsoft’s GraphRAG, the core lies in utilizing information at the Community or cluster level, formed by numerous nodes closely connected within the graph.
First, the system does not stop at simply finding individual data points. It reads the overall flow by referring to summarized versions of clusters where related information is gathered within the massive map of knowledge. This true value is revealed when a question is broad and comprehensive, such as “What are the overall risk factors for this project?” Instead of cross referencing thousands of individual nodes one by one, the system first identifies summary information from communities already grouped under themes like Risk Management or Process Delays, establishing the skeletal structure for a macroscopic answer.
Ultimately, the AI generates a Comprehensive Response by combining the detailed clues secured in steps 1 and 2 with the global context from step 3. The Large Language Model LLM receives these rich Evidences of Relationship and provides a deep, logically organized answer, much like an expert who thoroughly understands the field. Consequently, the user receives high level insights where the entire context is perfectly reflected, rather than a mere listing of fragmentary information.
Why GraphRAG Is Called the Completion of RAG
Ultimately, the core of Graph Retrieval lies in connectivity and structuring. To help with understanding, let us intuitively compare the utilization methods of traditional RAG and GraphRAG.
Traditional RAG vs GraphRAG: Comparison of Utilization Scenarios>>

3 Dramatic Corporate Transformations Driven by GraphRAG
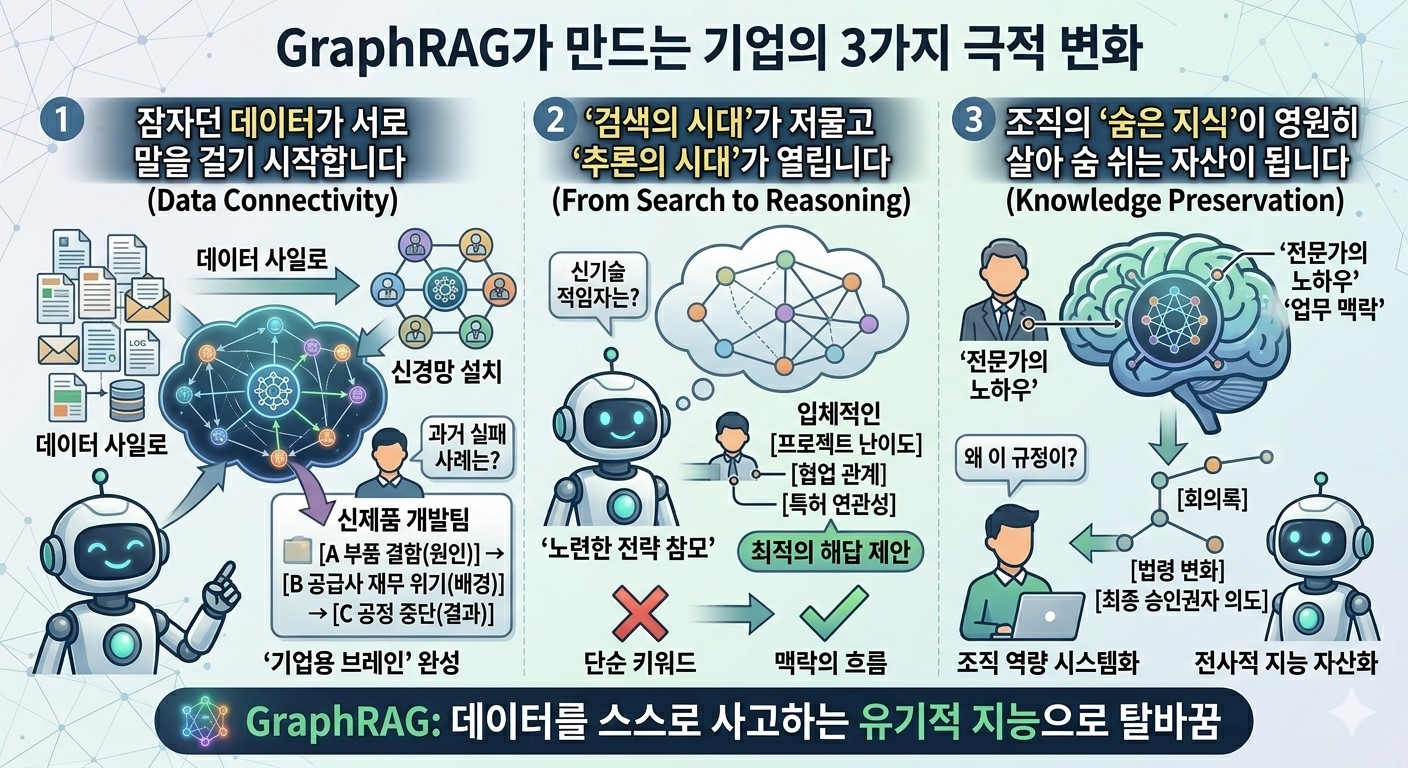
Are you still stuck at the level of simply finding documents well? Implementing GraphRAG means that a company’s data transforms from mere records into organic intelligence capable of thinking on its own. Here are three decisive qualitative changes that will redefine your organization’s competitiveness.
📍 Dormant Data Begins to Converse with Each Other
Many companies struggle with Data Silos, where information is disconnected between departments. While traditional methods were like stacking bundles of documents in a warehouse, GraphRAG is the process of installing a neural network between all data points. For example, when a new product development team asks about past failure cases, the AI does more than just find a report. It reveals a massive map of causality: “A defect in Component A (Cause) coincided with the financial crisis of Supplier B (Background), leading to the total shutdown of Process C (Result).” This is the moment fragmented information gathers to complete a living Corporate Brain.
📍 The Era of Search Ends and the Era of Inference Begins
The frustration of missing desired information because of mismatched keywords is now a thing of the past. This is because GraphRAG calculates the logical distance between a question and the data. To the question “Who in our company is the best fit for this specific new technology?”, the AI does not simply skim keywords on a resume. Instead, it three dimensionally analyzes the difficulty of projects the employee performed, their collaboration networks, and the relevance of their held patents. The AI transforms from a simple information courier into a seasoned strategic advisor that pierces through the context of data to suggest optimal solutions.
📍 The Hidden Knowledge of the Organization Becomes a Permanently Breathing Asset
Every time a veteran employee leaves, the loss of their decades of know-how and work context is a significant blow to the company. GraphRAG preserves unstructured knowledge that previously existed only in an expert’s mind by capturing it in a graph structure. Thanks to this, even a newly joined employee can ask, “Why was this strict regulation introduced?” and immediately grasp the intense meeting minutes of that time, changes in legislation, and even the final approver’s original intent. This is the process where organizational capabilities, which once relied on individual memory, are permanently turned into assets as a systemized Enterprise Intelligence.
Beyond Search to Intelligent Inference
GraphRAG is not simply a version of RAG with slightly better performance. It is a technology that completely shifts the paradigm of looking at information from keyword centric to relationship centric.
While traditional RAG focused on finding What, GraphRAG answers How things are connected. As the volume of data grows and the relationships between those data points become more complex, the true value of GraphRAG will shine even brighter.
Have you been dissatisfied with simple search results in your business domain? If so, it is now time to implement GraphRAG, which will draw the lines of relationship between your data points.



