
Beyond Text into the Era of Vision: The Background of LMMs
The paradigm of artificial intelligence research is rapidly shifting beyond the success of Large Language Models (LLMs) toward Large Multimodal Models (LMMs) that integratedly process visual information. While early multimodal research was limited to simple image captioning or short-form Visual Question Answering (VQA), the core focus has now become the ability to understand complex human instructions within a visual context and perform logical reasoning.
In this context, LLaVA (Large Language-and-Vision Assistant) emerged as a symbolic model leading the open source ecosystem against proprietary giant models. LLaVA is more than just an image description tool. it has laid the foundation for a general purpose visual assistant model that understands human intent within a visual context. By transparently releasing its data and weights, LLaVA is driving the democratization of technology.

The Backbone of LLaVA: Understanding the Minimalist Architecture
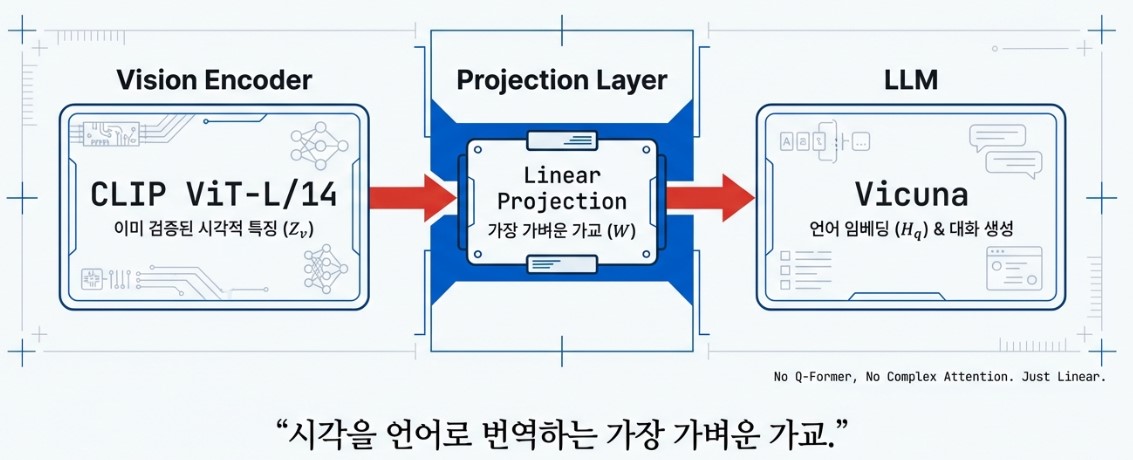
The design philosophy of LLaVA focuses on structural simplicity and efficient integration rather than building an overly complex system. To achieve this, it organically connects three core elements that perform distinct roles, resulting in a lightweight yet powerful multimodal performance.
First, the Vision Encoder, which is responsible for perceiving images, adopts OpenAI’s CLIP (ViT-L/14) model. CLIP is exceptionally skilled at linking visual concepts to linguistic expressions as it has been pre-trained on a vast array of image text pairs. LLaVA specifically utilizes the Grid Features from the final layer to meticulously preserve the spatial structure of objects within an image.
The visual information extracted in this manner passes through a bridge known as the Projection Layer. The role of this layer is to map visual feature vectors into an embedding space that the language model can comprehend. While the early models utilized a simple Linear Layer, the architecture has since evolved into a Multi-Layer Perceptron (MLP) structure that better captures the complex non-linear relationships between visual and linguistic information.
Finally, the Language Model (LLM), which serves as the brain of the system, is powered by the Vicuna model, which is based on Meta’s LLaMA and optimized for conversational performance. The LLM receives the visual tokens from the projection layer and the user’s text instructions simultaneously. It then interprets them as a single context and generates the most natural and accurate response through an auto-regressive process.
The design philosophy of LLaVA is rooted in minimalism and efficiency. Instead of complex architectures, it connects vision and language through Shallow Alignment, which means mapping the two modalities with minimal connections rather than deep and intricate integration. This approach provides powerful flexibility, allowing for the immediate porting of any new state of the art (SOTA) language model as soon as it emerges.
Compared to when OpenAI first released the CLIP model, language model performance has improved significantly. This means that instead of aligning vision and language through contrastive learning during integrated training, effective learning is now possible through the relatively simpler method of connecting a vision model to a well trained language model via a projection layer. This strategy offers the convenience and agility to swap in superior models whenever they become available.
This strategy also shines in terms of computational resource efficiency. LLaVA can complete its Stage 1 pre-training, which uses approximately 595,000 image-text pairs filtered from the CC3M (Conceptual Captions 3M) dataset, in less than six hours using eight A100 GPUs. Compared to “Deep Fusion” methods like CogVLM, which insert separate visual expert modules inside the model, LLaVA maintains a strategic advantage with lower implementation costs and a much faster pace of iterative technical improvement.
For reference, CC3M stands for the Conceptual Captions dataset released by Google, a vast collection consisting of approximately 3 million images and their corresponding captions collected from the web. Its defining characteristic is not just its volume but its design, which converts specific proper nouns in images into general concepts. This allows the AI to better learn the essential features of objects. By selecting approximately 600,000 high quality pairs from this massive dataset, LLaVA performs the alignment process, linking visual features to linguistic concepts, with extreme speed and efficiency.
The Secret to Performance: Visual Instruction Tuning and Data Generation
Recent advancements in multimodal models demonstrate that the essence of model performance lies more in the quality of data than in elaborate architectures. The LLaVA research team focused heavily on this point. To elevate AI’s visual intelligence, they utilized Knowledge Distillation from GPT-4, a text-only model at the time, to construct a high quality dataset of 158K visual instruction tuning pairs.

An interesting fact is that during the data generation phase in 2023, GPT-4 was a text-only model that could not directly see images. The researchers converted image captions and object bounding box coordinates into text metadata and fed them to GPT-4. Consequently, GPT-4 generated sophisticated and logical questions and answers based on this metadata as if it were visualizing the scene in its mind.
This approach was a highly clever choice both technically and economically. Directly inputting high resolution images into an AI to generate data is costly and slow. In contrast, LLaVA used existing metadata from datasets like COCO to prompt the model with instructions such as “A person and a bicycle are located at these specific coordinates in this photo. Generate a conversation based on this information.” By avoiding the direct processing of image tokens, they drastically lowered API costs while significantly increasing processing speed.
The resulting 158K dataset trains the model in three core capabilities that go beyond simple object description.

However, limitations exist. Since GPT-4 relied on text metadata, it sometimes used its imagination for fine details like color or texture not included in the text, leading to hallucinations. Despite this, successfully awakening the model’s brain by efficiently generating mass quantities of high quality data remains one of LLaVA’s greatest achievements.
With the release of the GPT-4V API in 2024, VLM training methodologies reached another turning point with the emergence of Teacher-Student Distillation. This method has rapidly become the de facto standard for the latest high performance VLMs, including LLaVA-NeXT and Qwen-VL-Plus.
While the early LLaVA method relied on text metadata, this new strategy directly utilizes top tier commercial models like GPT-4o or Gemini 1.5 Pro, which represent the pinnacle of visual intelligence. These Teacher models generate high quality training data for the Student models we aim to implement.
The principle is highly intuitive. First, researchers prepare original images from a specific domain such as CCTV frames, factory equipment photos, or medical imagery. Then, they provide these images to a Teacher model with precise missions. For example, they might ask the model to describe every detail of the image minutely or generate five Q&A pairs regarding potential safety issues in an industrial setting.
The resulting image and high quality text pairs become powerful training materials for local VLMs. The greatest appeal of this method lies in Data Density. Research from ShareGPT4V shows that training a model on 10,000 detailed long captions that deeply explore the context of each image is far more effective than training on 100,000 fragmented short captions like “A man is riding a bicycle.” Ultimately, the success of VLM training depends not on the simple quantity of data, but on the density of information contained within it.
Efficient Two-Stage Training Protocol
LLaVA adopts a strategic two-stage training process to ensure stable model convergence while using resources efficiently.
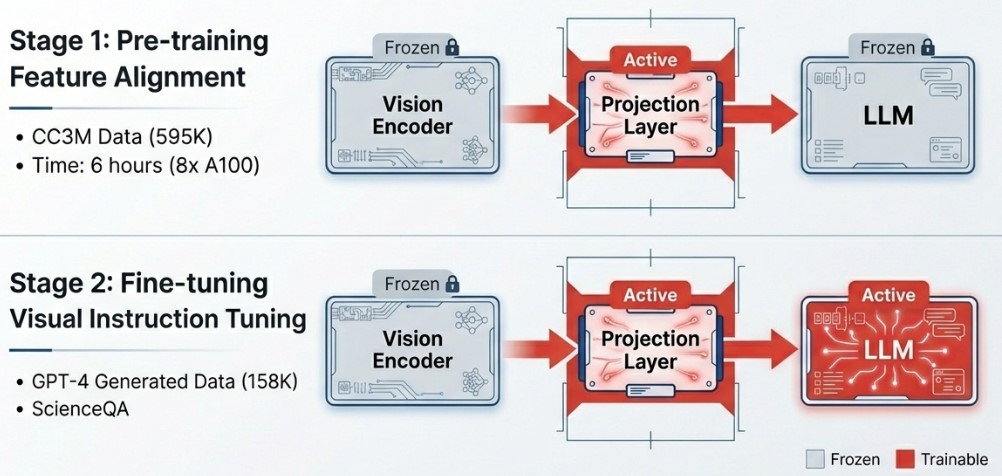
- Stage 1: Pre-training for Feature Alignment
Only the projection layer is trained while the vision encoder and language model remain frozen. Using the CC3M dataset (595K pairs), the model performs alignment between modalities. This stage is remarkably efficient, completing in just six hours using eight A100 GPUs. - Stage 2: End-to-End Fine-tuning
The vision encoder remains frozen, but the weights for both the projection layer and the entire language model are updated. Through 158K instruction tuning data points, the model acquires specialized task-solving capabilities to handle complex user requirements.
Establishing Efficiency and Performance Standards: LLaVA-1.5
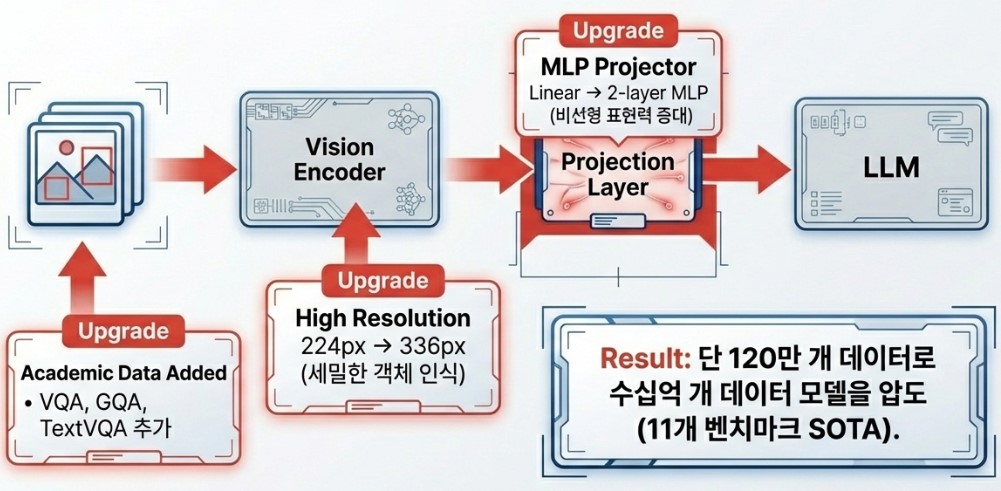
Released in 2023, LLaVA-1.5 went beyond a simple upgrade to become the de facto standard for open-source multimodal models. The core lies in structural improvements and enhanced data quality. It replaced the simple linear layer with a non-linear MLP connector and increased image resolution to 336px for more sophisticated visual understanding.
By strategically mixing high-quality data, such as academic VQA and shared datasets like ShareGPT4V, it achieved performance comparable to proprietary models with hundreds of billions of parameters using only a 13B scale model.
Evolution Beyond Limits: LLaVA-NeXT (v1.6)
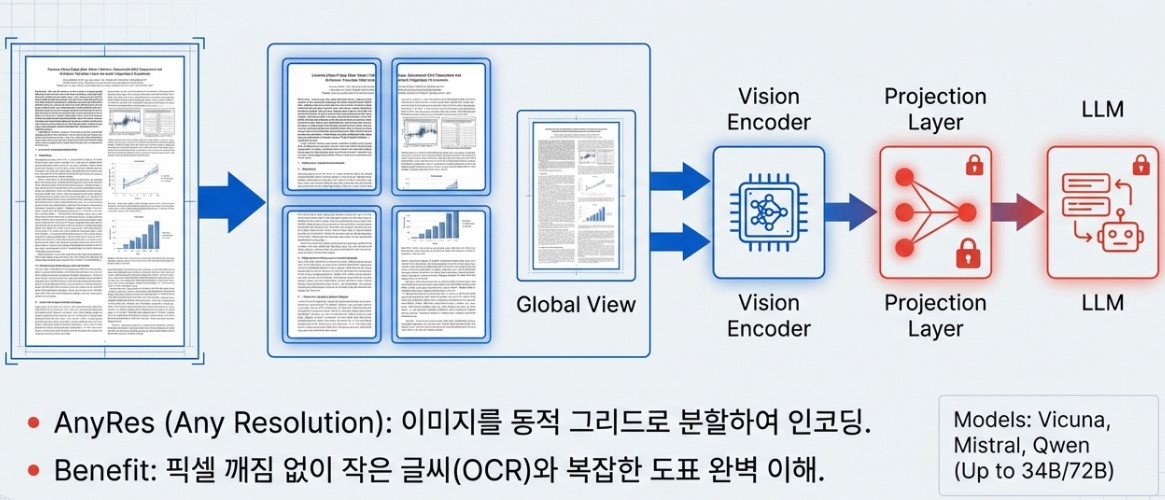
LLaVA-NeXT, released in 2024, achieved a powerful evolution comparable to commercial models like Gemini Pro. The most significant innovation is the introduction of the AnyRes algorithm. This technology flexibly processes high-resolution images by dividing them into dynamic grids such as 2×2, 1×2, or 4×1 instead of a fixed size. By combining a global view for overall composition and local views for detailed patches, it drastically improved OCR capabilities for small text and complex chart analysis.
Furthermore, it expanded its backbone options to include Mistral-7B, Llama-3 (8B), and Qwen-1.5 (72B/110B), gaining strong zero-shot capabilities in multiple languages and extending its reasoning to video understanding.
From Vision to Temporal Context: LLaVA-Video
LLaVA-Video (2024) shows innovative performance in the video domain, where understanding the flow of time is essential. The core of this model is the AnyRes-Video strategy, which extends AnyRes technology to video frames. Instead of simply downscaling high-resolution videos, it dynamically splits frames to analyze detailed patches, precisely capturing minute movements or text within the video.
Most interestingly, it demonstrates Zero-shot Transfer ability, where a model trained primarily on image data can immediately perform video tasks. By combining this with 178K high-quality video instruction tuning data points, it can reason about the overall context of a video and answer complex questions. Through linear scaling techniques, it overcomes the maximum token length of LLMs, showing length generalization that allows it to understand long-duration videos without interruption.
The Ultimate Multimodal: LLaVA-OneVision
LLaVA-OneVision (2024) opened a new horizon for open-source Large Multimodal Models (LMMs) by integrating three core scenarios—single image, multi-image, and video—into a single model. Its greatest innovations are the AnyRes-Max strategy, which maximizes high-resolution image processing, and its Task Transfer capability, which naturally transfers intelligence learned from images to video and multi-image scenarios.
Technically, it combines a SigLIP vision encoder with a Qwen2 language backbone. By refining the dynamic grid configuration, it shows performance rivaling GPT-4o and Gemini Pro 1.5 in complex chart analysis and multi-image comparison. It also introduced a pooling strategy to optimize token efficiency during video training, maintaining precision without wasting computational resources.

The most remarkable aspect is that all this performance was achieved through a fully transparent framework and an efficient training pipeline. Through a three-stage training process using a massive curated dataset of 85M points, LLaVA-OneVision proved its potential as an agent capable of solving complex real-world problems.

Rival Analysis: LLaVA vs. Other VLM Models
As of 2026, the open source VLM market is divided into three major lineages that rival proprietary models in performance, each following its own distinct design philosophy.
Positioning of Key Models
- Qwen-VL (2.5 Series): The Leader in Global Versatility
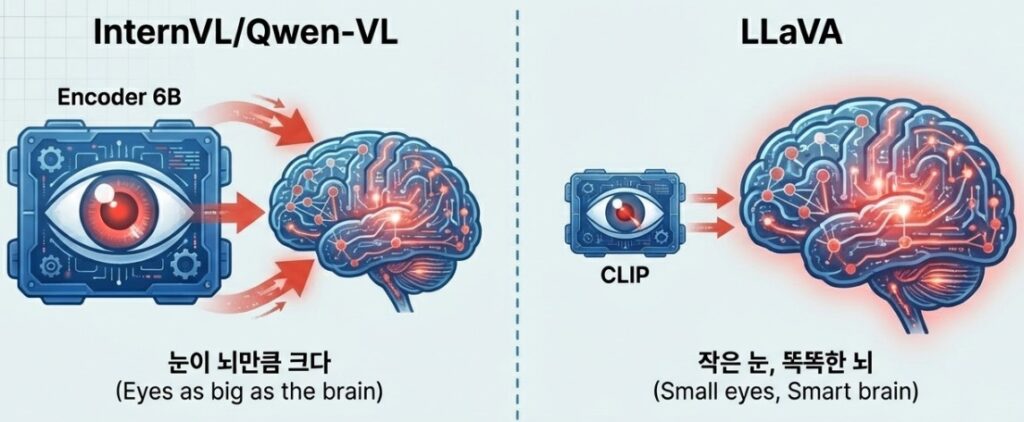
This model is a powerhouse of global versatility. It maximizes information density using a visual resampler with hundreds of millions of parameters and integrates video and audio. Thanks to its outstanding multilingual processing capabilities, it is primarily utilized for global agent services. - InternVL (2.5+): Aiming for Overwhelming Scale
InternVL focuses on massive scale. Equipped with a 6B class giant vision encoder, it performs deep learning level reasoning starting from the image extraction stage. It is ideal for industrial sites requiring alternatives to GPT 4o, such as ultra high resolution OCR or precise medical image analysis. - LLaVA (OneVision/Video): The Symbol of Efficiency and the Open Source Standard
LLaVA remains the symbol of efficiency and the standard for open source models. While maintaining structural simplicity, it achieves optimal performance with minimal resources through high quality data distillation technology. Because it is easy to customize, it is often the first choice for companies building on device models.
Architectural Differentiation
The unique position of LLaVA becomes even clearer when comparing its architecture to other models.
- vs CogVLM (Deep Fusion): While CogVLM adopts a Deep Fusion approach by inserting a separate visual expert module inside the model, LLaVA chooses Shallow Alignment, mixing information through a projection layer. This results in a drastic reduction of complex implementation costs.

- vs Qwen/InternVL (Scaling): While Qwen and InternVL compete through massive resamplers and encoder scaling, LLaVA uses a relatively smaller CLIP encoder. Instead, it maximizes the sophistication of data alignment, proving overwhelming efficiency in the small to medium scale model market of 8B parameters or less.
Summary: Which Model is Right for Your Project?
Ultimately, Qwen is the best choice for general purpose services, InternVL for precision analysis, and LLaVA for domain specific optimization and practical deployment. LLaVA continues to add value as the standard for practice oriented VLMs, proving that sophisticated data is more fundamental than complex design.
Practical Application and Future Outlook
To successfully implement and operate LLaVA in a professional environment, specific optimization strategies that go beyond a basic understanding of architecture are essential. For developers aiming to maximize performance within limited resources, several key tips can drastically reduce the difficulty of practical deployment.
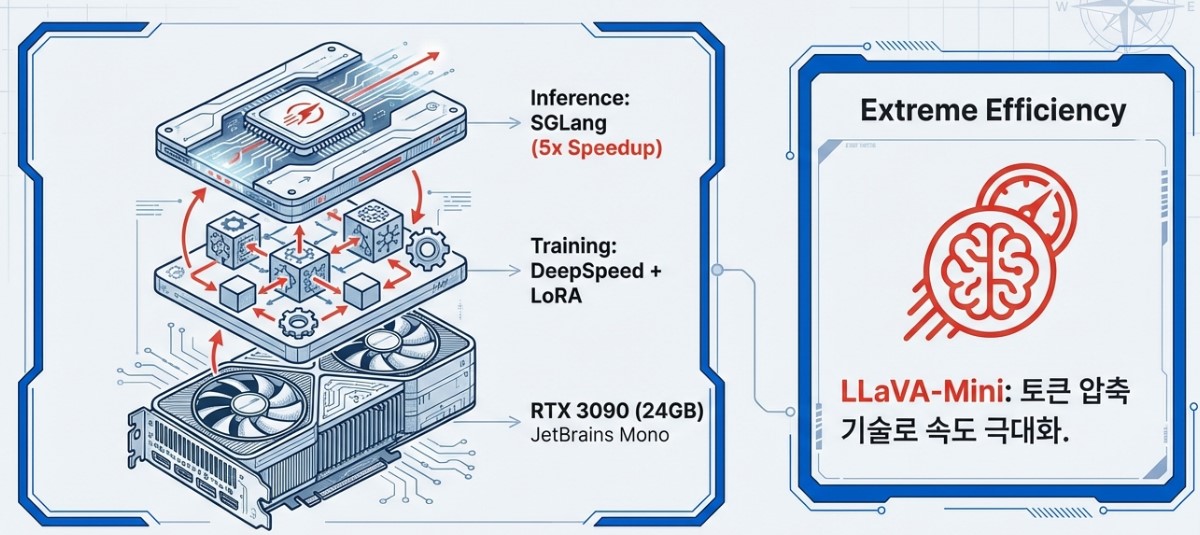
First, regarding hardware efficiency, combining DeepSpeed with LoRA (Low-Rank Adaptation) is highly recommended. This approach allows for the smooth operation of 7B scale models even on consumer GPUs like the RTX 3090 by minimizing memory usage without updating all parameters. This provides high accessibility, enabling the construction of high performance multimodal environments without expensive enterprise grade equipment.
In the inference stage, the introduction of the SGLang engine should be actively considered. SGLang optimizes complex prompt structures to achieve inference speeds up to five times faster than traditional methods. This leads to substantial productivity gains, especially in projects requiring rapid responsiveness such as large scale video captioning or real time monitoring.
For on device environments where extreme efficiency is required, LLaVA-Mini serves as an excellent alternative. Through compression technology that uses only a single visual token per image, it demonstrates incredible resource efficiency, capable of processing long videos of over three hours even in a 24GB VRAM environment.
Looking ahead, LLaVA is expected to evolve into forms such as LLaVA-Critic, which self corrects response errors, or autonomous agents integrated with reinforcement learning. LLaVA has now moved beyond being just an open source model to firmly establish itself as a core infrastructure in the AI ecosystem, bridging the visual world and language.




