
Traditional Retrieval-Augmented Generation (RAG) systems work very effectively on plain text documents. However, they struggle significantly when dealing with documents that contain unstructured data, such as complex tables in financial reports, charts in research papers, or CAD drawings. This is because such systems often fail to capture the essential structure and context of the data.
In this article, we take a deep dive into two core challenges of unstructured data processing. First, extracting accurate information from complex tables spanning multiple rows and columns. Second, correctly interpreting the geometric and semantic information embedded in CAD drawings and blueprints.
We will explore the latest technological approaches designed to address these persistent challenges, examining how each method works along with its strengths and limitations.
Part 1: The Evolution of RAG for Handling Complex Tables
The Limits of Traditional RAG: Why Table Data Loses Its Integrity
To understand why traditional RAG pipelines fail at handling complex tables, it is important to examine two key bottlenecks:
- Structural Breakdown: Simple text splitters do not consider the structural integrity of tables. As a result, tables are fragmented into meaningless chunks, breaking relationships between rows and columns and ultimately destroying the underlying meaning of the data.
- Noisy Embeddings: When large and complex tables are embedded as raw text, too much information gets mixed into a single vector. This results in “noisy” embeddings that are inefficient for semantic search, significantly reducing retrieval accuracy.
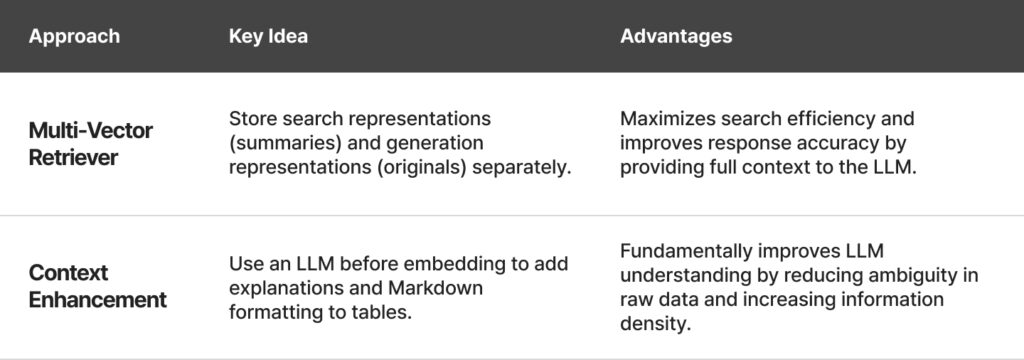
Approach 1: Separation Strategy with Multi-Vector Retrievers
Traditional RAG embeds text chunks and stores them in a vector database, passing retrieved chunks directly to the LLM. However, this approach fails for complex tables and images because numerical and structured information becomes diluted when embedded directly.
Multi-vector retrievers break this limitation by separating representations:
- Vector Store (for retrieval): Stores summarized versions of the data as embeddings
Example: “This table shows Samsung Electronics’ revenue by division in Q4 2025, highlighting a 30% growth in the semiconductor segment.” - Document Store(for generation): Stores the original raw content
The key idea is to strategically separate representations for retrieval and generation. Using tools like the Unstructured library and multi-vector retrievers, this approach enables more efficient and accurate processing.
Process
- Step 1: Intelligent Parsing
Using tools such as the Unstructured library’s partition_pdf, the system analyzes the visual layout of a document. This enables it to intelligently distinguish between plain text and tables, while segmenting text based on headings and subheadings to preserve the document’s logical structure. As a result, tables are extracted as intact tables, and text is cleanly organized into coherent chunks. - Summarization and Raw Content Storage
During the retrieval stage, concise summaries of both tables and text chunks are generated and embedded. These summaries maximize retrieval efficiency. When the system retrieves the summaries most relevant to a user’s query, it passes not the summaries, but the full original tables or text to the LLM during the answer generation stage. This ensures that the LLM has access to complete context, enabling it to generate accurate and detailed responses.
Expected Benefits
This approach enhances both retrieval efficiency and answer accuracy. By embedding concise summaries, it effectively reduces the issue of noisy embeddings. At the same time, providing the original data during the generation stage enables the LLM to produce accurate and detailed responses.
This method is particularly well-suited for handling large and complex tables such as those found in financial reports or scientific research where embedding the entire dataset would otherwise introduce significant noise.
Approach 2: Improving Accuracy through Context Enrichment and Standardization
The second approach focuses on enhancing and standardizing table data using an LLM before embedding. The goal is to maximize both readability and information density, enabling the LLM to better understand the data.
Process
- Step 1: Context Enrichment
The LLM analyzes not only the extracted table but also the surrounding text from the entire document. Based on this, it generates a rich and detailed contextual description that explains how the table is used within the document.
- Step 2: Format Standardization
The LLM converts the extracted table into a consistent Markdown format. Markdown provides a clear structure that improves the LLM’s understanding, which in turn enhances embedding efficiency.
- Step 3: Unified Embedding
The contextual description and the Markdown-formatted table are combined into a single, information-dense “table chunk.” This chunk is then embedded and stored in the vector database.
Expected Benefits
This approach reduces ambiguity that may exist in the original table. By incorporating rich context and a standardized format, it enables the LLM to understand and utilize table data far more accurately during both retrieval and generation stages.
It is particularly effective for documents where the meaning of a table is not self-contained and relies on context distributed across the document such as legal contracts or regulatory materials.
Summary and Comparison of Table Processing Techniques
Part 2: CAD Drawing Processing Techniques
Beyond Pixels to Vectors: The Nature of CAD Data
Complex technical drawings used in architecture and mechanical design consist of dense layers of lines and symbols. Traditional pixel-based image analysis methods (e.g., CNNs) have clear limitations when it comes to interpreting such fine-grained structural information.
To address this challenge, a paradigm shift is required. Instead of treating drawings as collections of pixels, they must be handled as vector data that inherently contains geometric information.
Approach 1: Structural Analysis with Graph Neural Networks (GNNs)
One of the most challenging types of data in RAG systems is engineering drawings from construction and manufacturing. Traditional AI approaches based on CNNs interpret drawings as images, making it extremely difficult to extract the underlying structural meaning.
VectorGraphNet addresses this limitation by interpreting drawings not as images, but as graphs of connected lines. This enables precise identification of elements such as walls, doors, and windows, even in highly complex blueprints.
In this approach, CAD drawings are transformed into graphs that represent relationships between vector elements, and these graphs are analyzed using Graph Neural Networks (GNNs) to capture structural meaning. As a result, we gain the following advantages:
- Accuracy: By directly analyzing design data rather than visual approximations, objects such as walls, windows, and pipes can be identified with much higher precision.
- Efficiency: Processing coordinate data is significantly more computationally efficient than handling large images.
- Applications: Enables use cases such as automatic 3D model generation from drawing PDFs or counting specific components within a design.
Process
- Step 1: PDF to SVG Conversion
To directly access vector data, CAD drawings are converted from PDF into SVG (Scalable Vector Graphics), an open standard format. A key step in this process is standardizing all elements—such as lines, rectangles, and circles—into basic commands for consistent processing.
- Step 2: Graph Construction
The drawing is represented as a graph:
Nodes: Each SVG element (e.g., lines, curves) becomes a node. Each node contains geometric features such as length and curvature, as well as style attributes like color and thickness.
Edges: Spatial relationships between nodes (e.g., proximity) are computed using algorithms such as K-Nearest Neighbors (KNN). Edges encode features such as angles, intersections, and containment relationships between elements.
- Step 3: Semantic Segmentation with GNN
The constructed graph is analyzed using GNN models such as Graph Attention Networks. The model performs semantic segmentation by assigning functional roles to each node (e.g., wall, door, dimension line), enabling a structured understanding of the drawing.
This approach is particularly well-suited for scenarios where geometric relationships between elements are critical, and where the meaning of each individual line contributes to the overall structure such as architectural blueprints or complex mechanical components.
Approach 2: Visual Understanding with Vision-Language Models (VLMs)
CAD drawings combine text (dimensions, annotations) and visual elements (shapes) in highly complex ways, making them difficult to process with traditional OCR methods. However, VLM-based approaches, such as ColPali, address this challenge by enabling a more holistic, vision-driven understanding.
Centered around the ColPali framework, this approach is based on the idea that “what you see is what you search.” Instead of treating a drawing as a collection of text or vector elements, the entire page is handled as a single image and directly interpreted by a Vision-Language Model (VLM).
This makes the approach highly effective for retrieval and contextual understanding of CAD drawings. However, it has limitations in performing highly precise structural analysis, and remains an active area of ongoing research.
Process
Step 1: Image Conversion
PDF pages are converted into image formats such as PNG.
Step 2: VLM Embedding
A VLM, such as PaliGemma, takes the page image as input and generates contextualized embeddings. These embeddings capture not only textual information but also layout, shapes, tables, and other visual elements as a grid of image patches.
Step 3: Late Interaction Retrieval
Using a mechanism known as Late Interaction (or MaxSim), each token of the user query is compared against all image patches individually. The system then aggregates the highest similarity scores to compute overall relevance, enabling efficient retrieval of the most relevant pages.
Expected Benefits
This approach significantly simplifies the pipeline by eliminating the need for complex vector extraction or graph construction processes. It is particularly powerful for documents where visual structure—such as diagrams, layouts, and mixed content—is critical.
It is especially effective in scenarios where large volumes of diverse document formats (e.g., invoices, technical manuals, presentation slides) must be processed, and where rapid deployment is prioritized over the complexity of building vector- or graph-based pipelines.
Summary and Comparison of CAD Processing Techniques

The Future: Toward an Integrated Approach
So far, we have explored two major challenges in unstructured data processing—tables and CAD drawings and the latest approaches to solving them.
- Table processing techniques can be broadly categorized into two approaches: one that improves efficiency and accuracy by separating retrieval and generation contexts, and another that enhances LLM understanding through pre-processing and data enrichment.
- CAD processing techniques, on the other hand, involve a trade-off between deep structural analysis using GNNs and simplified visual understanding using VLMs.
Future systems will go beyond simply choosing one method over another. Instead, they will dynamically balance the trade-offs between the precision of GNN-based structural analysis and the simplicity and scalability of VLM-based approaches.
For example, in aerospace design drawings—where precise relationships between components carry legal and engineering significance—GNN-based analysis is essential. In contrast, for diagrams in marketing materials, where quick visual reference is more important, VLM-based processing may be far more efficient.
Ultimately, the ability to intelligently select and combine the most appropriate techniques based on the purpose and nature of the document will become a key competitive advantage for next-generation document understanding systems.



