
Imagine hiring a brilliant employee who graduated top of their class from the best university in the country. Their analytical ability is extraordinary, their answers sound intelligent, and they can process enormous amounts of information in seconds.
But there is one devastating flaw.
Every morning when they arrive at work, they have completely forgotten everything discussed the day before. The intense project debates, architectural decisions, and operational insights all vanish overnight as if they never existed.
Whenever you ask a question, they frantically search through piles of documents to reconstruct an answer. Sometimes the response is impressive. Sometimes even insightful. But the moment the session ends, the reasoning disappears back into blankness.
Surprisingly, this was the reality of most Retrieval-Augmented Generation (RAG) systems deployed across enterprises through 2025.
Traditional RAG architectures were fundamentally reactive. They only “woke up” when a user submitted a prompt, searched through databases for relevant fragments, generated a response, and then discarded the entire reasoning process once the interaction ended.
In complex enterprise environments filled with massive documentation and interconnected operational context, these systems could retrieve information, but they could not truly accumulate knowledge. They stitched together fragments without building continuity. The AI never became genuinely smarter over time, and organizational knowledge itself remained scattered and static.
But by 2026, the conversation inside AI architecture began to shift dramatically.
The critical question was no longer:
“Can the AI answer correctly?”
Instead, the industry began asking something far more profound:
“Can the AI remember what it learned tomorrow?”
Could AI evolve beyond a tool that only reacts when prompted? Could it become a living knowledge system that continues reading, organizing, refining, and connecting information even while humans are away?
A system that wakes up slightly smarter today than it was yesterday.
That question marks the beginning of an entirely new AI paradigm.

“Your Personal Librarian Organizes the Library Overnight”:
How Andrej Karpathy’s ‘LLM Wiki’ Turns Knowledge into Compound Interest
To solve the frustrating limitation of AI systems that forget everything after each session, Andrej Karpathy proposed an idea that was both remarkably intuitive and surprisingly powerful: the LLM Wiki.
At the core of the concept is a simple shift in perspective:
Stop treating AI like a search box that desperately scrambles for answers only when asked.
Instead, hire it as a full-time research librarian managing your entire knowledge library.

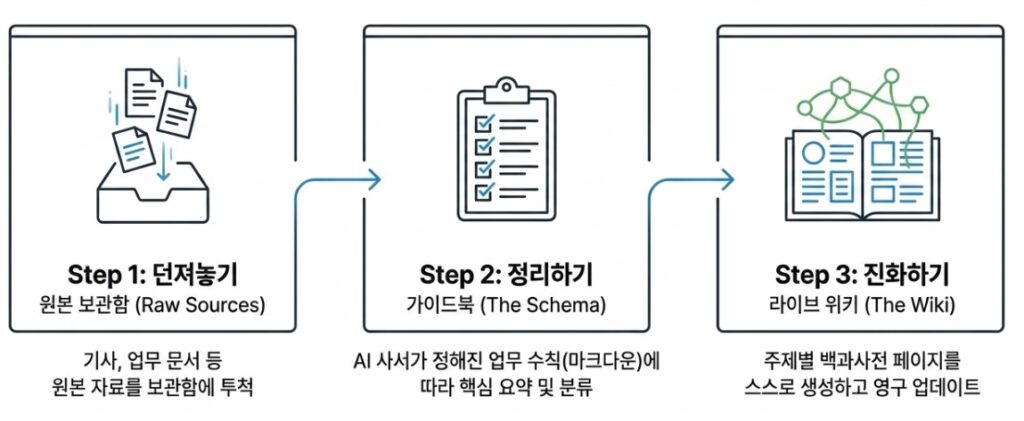
Imagine casually dropping technical reports, research papers, or internal documents into the Raw Sources folder before leaving work for the day. While nobody is watching, the AI librarian immediately gets to work. It reads the documents, extracts key concepts, summarizes important ideas, and automatically creates or updates interconnected wiki pages organized around related people, topics, projects, or technical domains.
By the time you return the next morning, the knowledge network has already evolved before you even type a single query.
But the real magic, and the reason this system behaves more like a living ecosystem than a static database, lies in a process called linting. At regular intervals, the AI revisits its own wiki and audits the knowledge structure itself:
“Wait, this document contradicts another source.”
“This information looks outdated.”
“These pages are no longer connected properly.”
The system then reorganizes, repairs, and refines its own internal knowledge graph autonomously. In effect, the wiki becomes self-healing.
Perhaps the most powerful aspect emerges during conversations with the user. Traditional AI systems generate answers and immediately forget the interaction afterward. But the LLM Wiki behaves differently. When meaningful insights, important conclusions, or valuable reasoning emerge during discussion, the AI recognizes that the conversation itself contains reusable knowledge.
Instead of letting that reasoning disappear, it promotes the insight into permanent wiki memory:
“This idea deserves to become part of the encyclopedia.”
A single interaction no longer evaporates after the session ends. It becomes a persistent intellectual asset contributing to future reasoning. Knowledge begins compounding like interest inside a bank account.
Remarkably, the entire system is powered not by complicated infrastructure or obscure programming languages, but largely through something deceptively simple: Markdown. Karpathy recognized that Markdown strikes an ideal balance between machine efficiency and human readability. It is lightweight enough for AI systems to process at scale while remaining simple enough for humans to inspect, edit, and maintain directly.
Within this architecture, the division of labor between humans and AI becomes beautifully clear. Humans become explorers who ask questions, introduce ideas, and provide curiosity. The AI becomes the meticulous librarian handling the exhausting labor of reading, summarizing, organizing, connecting, and maintaining knowledge structures continuously in the background.
More recently, this idea has evolved even further with mechanisms designed to suppress one of AI’s most dangerous weaknesses: hallucination. Some systems now require every AI-generated statement to include explicit citations identifying exactly which source documents and passages support the claim. If the AI cannot provide evidence, the statement is rejected entirely before entering the wiki.
In many ways, the LLM Wiki demonstrated something profoundly important: AI is no longer just a machine that answers questions.
It can become a persistent knowledge worker that continues organizing and refining information even while humans sleep.
And naturally, this leads to an even bigger question: If AI can organize knowledge autonomously, could it eventually begin connecting chains of thought on its own?
One researcher, more than anyone else, attempted to answer that question head-on.
“While You Sleep, the Neural Network Rewires Itself”: Garry Tan’s ‘GBrain’
If the LLM Wiki felt like hiring an extraordinarily meticulous librarian to organize an ever-growing library, the next idea goes one step further: an evolving AI brain capable of autonomously connecting thoughts, relationships, and operational intelligence on its own.
That system is GBrain, developed by Garry Tan, the CEO of Y Combinator.
What makes the story even more remarkable is that Garry Tan reportedly built the initial version of GBrain in just twelve days. Since then, the system has evolved into a massive knowledge network managing over 17,000 pages of information and thousands of interconnected entities autonomously.
So what made it fundamentally different?
The most fascinating behavior inside GBrain happens while the user is asleep. The system refers to this process as a Dream Cycle optimization phase.
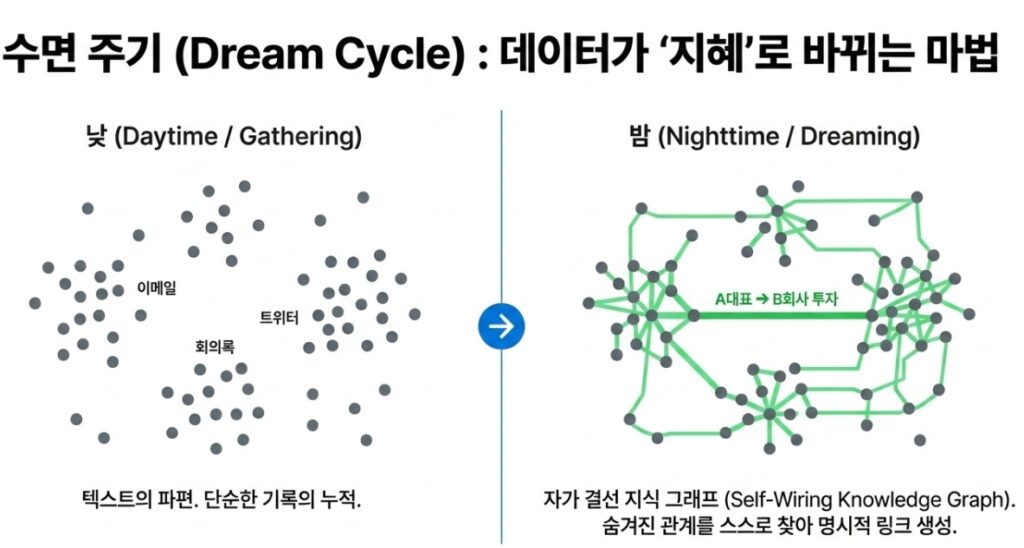
Imagine everything generated throughout a normal workday: emails, meeting transcripts, Slack conversations, social posts, research notes, and scattered operational memos. Traditional AI systems would simply store these artifacts as disconnected blocks of text.
But once the user closes the laptop and leaves for the night, GBrain quietly begins working in the background.
The AI rereads accumulated information autonomously and starts stitching together hidden relationships across documents.
“This meeting note suggests that executive A invested in company B.”
“This email implies that person C previously worked at company D.”
Without requiring explicit instructions, the system continuously converts fragmented textual clues into structured relational knowledge such as:
- A invested in B
- C worked at D
This forms the foundation of what GBrain calls a Self-Wiring Knowledge Graph.
The comparison to human cognition is difficult to ignore. Just as the human brain consolidates short-term experiences into long-term memory during sleep, GBrain spends idle hours reorganizing fragmented knowledge, repairing disconnected links, and strengthening relationships across its internal information network.
As a result, by the next morning, the AI assistant is not merely “updated.”
It has become structurally smarter.
When the user later asks:
“Which companies did executive A invest in this quarter?”
the system no longer relies on brute-force keyword search alone. Instead, it traverses a deeply interconnected network of relationships and retrieves answers that would otherwise remain hidden inside fragmented documents.
In effect, the AI begins behaving less like a chatbot and more like a continuously evolving cognitive system.
So how does GBrain prevent the AI from drifting into hallucinations or generating unreliable conclusions while continuously evolving its own knowledge system?
This is where Garry Tan introduces one of his most well-known design philosophies:
“Thin Harness, Thick Skills.”
The idea is surprisingly elegant.
Instead of overwhelming the AI with a massive, complicated instruction system all at once, GBrain provides the model with small, highly specialized behavioral rule sets for specific situations.
For example:
- how the AI should collect information
- how it should reorganize memory
- how it should update knowledge relationships
- how it should validate newly inferred facts
Rather than relying on one gigantic prompt, the system distributes intelligence across dozens of modular Skill Files. In GBrain’s case, approximately 29 independent skill modules govern the system’s behavior.
Remarkably, these Skill Files are not written in complicated programming languages. They are simple Markdown documents.
The AI does not “improvise” blindly. Instead, it follows procedural behavioral guidance defined inside these modular skill instructions.
This creates a crucial separation between two fundamentally different domains:
- areas requiring flexible reasoning and creativity
- areas requiring strict deterministic behavior such as database operations or retrieval logic
By isolating these responsibilities carefully, the system dramatically reduces the likelihood of chaotic or unpredictable agent behavior.
But perhaps the most fascinating capability is what happens when the AI makes mistakes.
GBrain introduces a genuine Self-Learning Loop.
When the user provides corrective feedback, the AI does not simply store the correction temporarily. Instead, it analyzes the feedback and updates its own Skill Files autonomously.
In other words, the system improves not by retraining the foundation model itself, but by refining the behavioral rules governing how the model operates.
No expensive retraining pipeline.
No massive parameter updates.
No rewriting large codebases.
The AI accumulates experience by evolving its own operational playbook.
What GBrain ultimately demonstrated is a radically different vision of the future.
A true AI assistant is not a magical genie that appears only when summoned to answer questions.
It is a persistent cognitive companion quietly reorganizing knowledge in the background, continuously strengthening its internal neural pathways using the raw material of everyday life itself.
And every morning, it wakes up slightly smarter than the day before, already waiting for you.

“A Brilliant AI Matters Less Than an Organization That Remembers”
Many companies adopting the latest AI systems still operate under the same assumption:
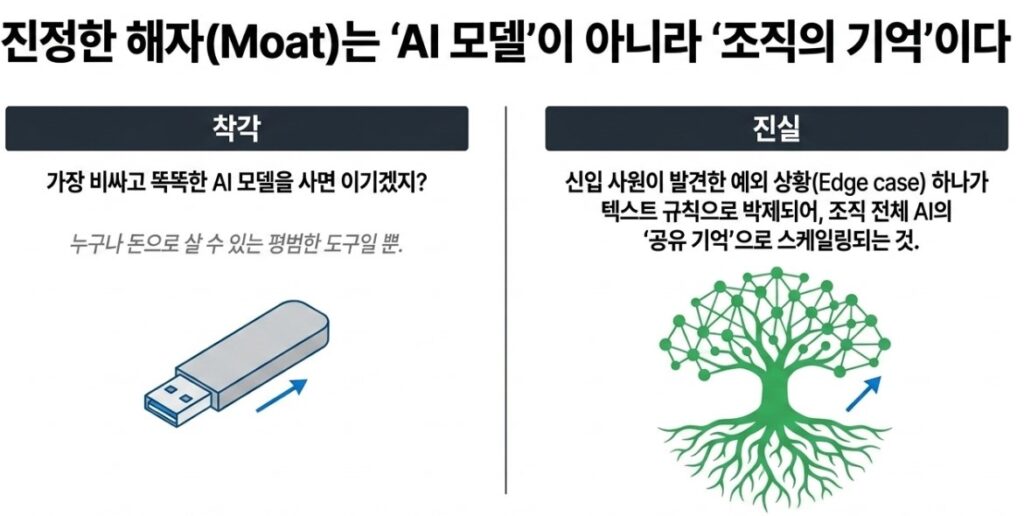
“If we deploy the smartest AI model in the world, we’ll automatically outperform our competitors.”
But the conclusions reached by Andrej Karpathy and Garry Tan point in a very different direction. Powerful foundation models themselves are rapidly becoming commodities. Eventually, anyone with sufficient budget will gain access to roughly the same underlying intelligence.
So where does a company’s true competitive moat come from?
Not from the model itself, but from what could be described as a Compiled Organizational Knowledge Layer built collaboratively between humans and AI over time.
Imagine hiring a world-class chef capable of creating extraordinary dishes. If that chef forgot every recipe, mistake, experiment, and breakthrough at the end of each workday, the restaurant would never truly evolve. The real asset is not the chef alone. It is the continuously accumulated recipe notebook containing refinements, failures, discoveries, and operational wisdom gathered over years of experience.
The same principle now applies to AI systems.
Inside most organizations today, employees interact with AI, discover edge cases, correct hallucinations, refine workflows, and uncover operational insights. But almost all of that knowledge remains trapped inside isolated chat histories before disappearing forever.
Architectures like LLM Wiki and GBrain fundamentally change this dynamic. When someone corrects an AI failure or discovers a better operational pattern, the system converts that experience into structured, reusable knowledge, often stored in lightweight human-readable formats such as Markdown.
In effect, a single employee’s correction instantly scales into shared institutional memory for the organization’s entire AI ecosystem.
And this creates an extraordinary compounding effect.
An AI system continuously accumulating organizational memory for even one year becomes dramatically more capable than a competing system that starts each day from cognitive blankness.
But this immediately introduces a far more dangerous problem:
What happens if false information contaminates the organization’s memory itself?
A large-scale knowledge system becomes incredibly powerful, but also incredibly fragile if corrupted information enters the loop unchecked.
This is why modern AI architectures increasingly emphasize something known as Epistemic Integrity, the ability to preserve trustworthy knowledge while resisting contamination from false or low-confidence information.
These systems are no longer passive document repositories. They behave more like continuously self-monitoring cognitive immune systems.
One particularly fascinating concept emerging from this philosophy is the idea of a Graveyard of Failures.
Whenever the AI produces a hallucination, operational mistake, or dangerous reasoning error, the failure is not hidden or discarded. Instead, it is permanently logged into a growing collection of regression test cases. Over time, hundreds or even thousands of failure examples accumulate.
Before any new AI model, workflow update, or system revision can be deployed into production, it must successfully pass every historical failure scenario stored inside this graveyard.
The organization effectively builds an evolving institutional memory of its own mistakes.
Without this process, even the most sophisticated AI knowledge base eventually decays into a landfill of outdated or contradictory information. But systems capable of continuously auditing themselves, correcting errors transparently, and learning structurally from failure evolve into something far more valuable:
a genuine technological moat that competitors cannot easily replicate.
2026 After the AI Hype: The World Is Moving Toward “AI Teams” and Safe Personal Brains
The ideas proposed by Andrej Karpathy and Garry Tan are no longer viewed as experimental curiosities from a handful of brilliant technologists. By 2026, their philosophy of “living knowledge” and continuously compounding AI systems has evolved into one of the dominant forces reshaping the global AI ecosystem.
Why did this shift happen so quickly?
Because the AI bubble built on blind optimism finally collided with reality.
Across industries, companies discovered that deploying powerful AI models was not enough. According to recent industry reports, only a small percentage of enterprise AI agent pilot programs generated meaningful production-level value. The problem was not that the models lacked intelligence. The problem was that they remained unpredictable.
When an AI system made a dangerous mistake inside finance, healthcare, manufacturing, or infrastructure environments, organizations often had no reliable way to trace the reasoning process, interrupt execution safely, or enforce operational governance in real time.
As a result, the AI industry in 2026 has begun shifting its focus away from blind faith in ever-larger foundation models. Instead, the real competitive battleground has become the construction of reliable safety infrastructure capable of monitoring, controlling, validating, and governing AI behavior continuously.
At the same time, enterprises are rapidly moving beyond traditional RAG systems. Rather than relying on passive keyword retrieval alone, organizations are increasingly adopting knowledge graph architectures such as GraphRAG, which can model explicit relationships and causal structures across documents, entities, and operational workflows.
Another major shift is the collapse of the “superhuman universal AI” fantasy.
Instead of assigning every task to one gigantic all-knowing model, modern systems increasingly resemble collaborative AI teams composed of specialized agents. One agent writes code. Another reviews for bugs. Another handles documentation. Together, they operate more like autonomous engineering teams than isolated chatbots.
This multi-agent paradigm, commonly referred to as MAS (Multi-Agent Systems), is rapidly becoming one of the defining architectural trends of the industry.
Meanwhile, execution-oriented agents capable of interacting directly with real-world systems are gaining enormous momentum. Systems such as OpenClaw Github demonstrate how AI agents can autonomously interact with calendars, databases, operating systems, and external applications to perform concrete operational tasks rather than simply generating text responses.
In many ways, this marks the true beginning of the Agentic Engineering era.
But perhaps the most emotionally significant shift for ordinary users revolves around one increasingly unavoidable issue:
privacy.
As AI systems evolve into deeply personalized cognitive companions capable of understanding individual habits, corporate workflows, and sensitive behavioral patterns, public anxiety surrounding centralized cloud infrastructure has intensified dramatically.
This is why 2026 is rapidly becoming the era of Local-First AI.
Instead of constantly sending sensitive information to expensive external cloud APIs, lightweight Small Language Models (SLMs) running directly on personal devices are becoming powerful enough to organize, reason over, and connect private knowledge locally.
Modern SLMs are dramatically cheaper, increasingly efficient, and surprisingly capable in specialized reasoning tasks. More importantly, they allow users to retain full ownership of their personal cognitive infrastructure.
The result is something profoundly different from the cloud-centric AI systems of previous years:
not merely an assistant rented temporarily from a tech company,
but a private, continuously evolving second brain that lives safely inside your own devices.

The Era of Simply Owning Intelligence Is Ending. The Future Belongs to Those Who Build the Soil Where Intelligence Can Grow.
For years, the AI industry focused on a single competition:
Who possesses the smartest model?
But by 2026, the question has fundamentally changed:
Can this AI still remember tomorrow what it learned yesterday?
The systems envisioned by Andrej Karpathy through the LLM Wiki and by Garry Tan through GBrain point toward the same conclusion.
True competitive advantage no longer comes from model size alone.
It comes from building systems where memory persists, operational rules accumulate, failures become reusable assets, and organizational knowledge continuously compounds over time.
The real choice facing organizations is no longer whether to adopt AI.
It is whether they will continue relying on brilliant systems that forget everything after each interaction, or begin cultivating cognitive infrastructures that quietly become smarter every night.
In the years ahead, the winners will not simply be the companies that possess intelligence.
They will be the companies that design the environments where intelligence itself can evolve.




