
상상해 보십시오. 당신의 회사에 서울대를 수석 졸업한 천재적인 직원이 입사했습니다. 그런데 치명적인 문제가 하나 있습니다. 매일 아침 출근할 때마다 어제까지 치열하게 논의했던 프로젝트 내용을 하얗게 잊어버린다는 것입니다. 질문을 던질 때마다 그는 서류 더미를 미친 듯이 뒤져서 그럴싸한 답을 내놓지만, 모든 맥락과 통찰은 다시 ‘백지상태’가 됩니다.
놀랍게도 이것이 2025년까지 전 세계 기업들이 열광하며 도입했던 ‘검색 증강 생성(RAG, Retrieval-Augmented Generation)’ 기반 AI의 현실이었습니다. 기존의 RAG 시스템은 철저히 수동적입니다. 사용자가 프롬프트를 입력하는 그 순간에만 깨어나, 데이터베이스를 뒤지고, 세션이 끝나면 방금 전까지의 추론과 판단은 아무 일 없었다는 듯 사라집니다. 대규모 문서와 맥락이 얽힌 엔터프라이즈 환경에서, 이 방식은 정보를 ‘연결’하지 못한 채 파편만 주워 붙이는 데 그쳤습니다. AI는 결코 스스로 똑똑해지지 않았고, 조직의 지식도 쌓이지 않았습니다.
하지만 2026년의 기술 현장에서는 전혀 다른 질문이 던져지고 있습니다.
“AI가 답을 잘하느냐”가 아니라,
“AI가 배운 것을 내일도 기억하게 만들 수는 없는가?”
질문할 때만 반응하는 도구가 아니라, 사람이 보지 않는 시간에도 스스로 읽고, 정리하고, 연결하며 어제보다 오늘 더 똑똑해지는 ‘살아있는 지식 구조’는 가능하지 않을까요?
이 질문에서, 지금 우리가 서 있는 새로운 AI 패러다임이 시작됩니다.

“당신의 전임 사서가 밤새 도서관을 정리합니다”:
안드레아 카파시의 ‘LLM 위키(LLM Wiki)’가 만드는 지식의 무한 복리
매일 기억을 잃어버리는 AI의 답답함을 해결하기 위해, 테슬라의 전 AI 디렉터이자 인공지능 분야의 권위자인 Andrej Karpathy는 아주 기발하고 직관적인 해결책을 내놓았습니다. 바로 ‘LLM 위키(LLM Wiki)’라는 개념입니다.
그의 핵심 아이디어는 이렇습니다. “AI를 우리가 질문할 때만 허둥지둥 책을 찾아오는 ‘검색 창’으로 쓰지 말자. 대신, 내 서재를 통째로 관리하는 ‘전임 사서(Research Librarian)’로 고용하자!”.

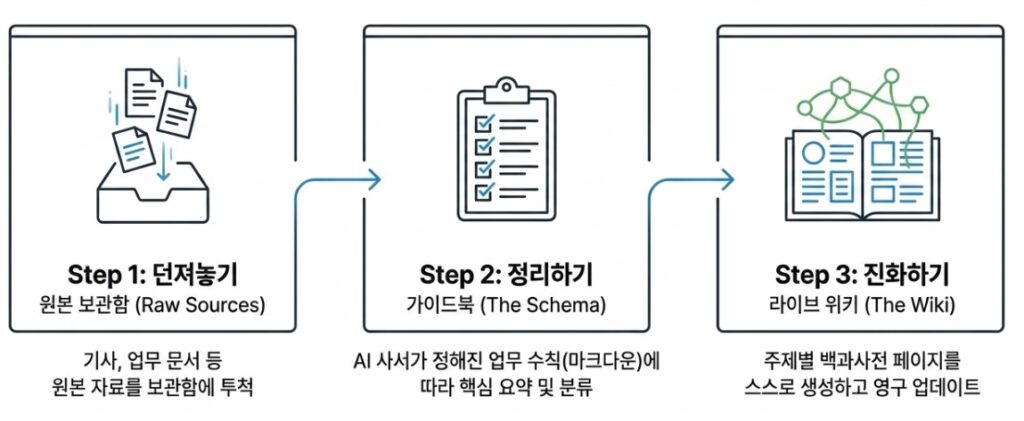
이 마법은 우리가 모니터 앞을 떠나 있는 ‘백그라운드’에서 조용히 일어납니다. 시스템의 구조는 생각보다 단순합니다. 건드리지 않는 원본 자료들을 모아두는 ‘원본 보관함(Raw Sources)’, AI가 이 자료들을 읽고 정리해 두는 나만의 백과사전인 ‘위키(The Wiki)’, 그리고 AI 사서가 지켜야 할 업무 수칙을 적어둔 ‘가이드북(The Schema)’으로 나뉩니다.
당신이 흥미로운 기사나 복잡한 업무 문서를 원본 보관함에 툭 던져놓고 퇴근하면, 자리를 비운 사이 AI 사서는 즉각 움직입니다. 문서를 꼼꼼히 읽고 핵심을 요약한 뒤, 관련 있는 인물이나 주제별로 10~15개의 백과사전(위키) 페이지를 스스로 만들고 업데이트합니다. 당신이 다음 날 출근해 검색 창을 열기도 전에, 지식의 연결망은 이미 한 단계 진화해 있는 것입니다.
이 시스템이 진정한 ‘살아있는 생태계’가 되는 비결이자 지식이 복리로 불어나는 핵심 엔진은 바로 ‘린팅(Linting)’이라는 과정에 있습니다. AI가 주기적으로 위키를 훑어보며 “어라? A 문서에서는 이렇다고 했는데 B 문서랑 말이 안 맞네?”라며 모순점을 찾거나, 너무 오래된 정보, 혹은 연결이 끊긴 페이지들을 찾아내 스스로 뜯어고칩니다. 지식이 자동으로 자가 치유(Self Healing) 되는 구조입니다.
더욱 매력적인 부분은 당신이 AI에게 질문을 던질 때 나타납니다. 기존 AI는 대답을 하고 나면 그 대화 내용을 까맣게 잊어버렸습니다. 하지만 LLM 위키의 사서는 다릅니다. 당신과 대화하며 나눈 훌륭한 통찰이나 멋진 결론이 나오면, “이 내용은 정말 중요하니까 백과사전에 새 페이지로 박제해 둬야겠어!”라며 스스로 기록합니다. 한 번의 질문과 답변이 휘발되지 않고 영구적인 지식으로 굳어지며, 이것이 다음 생각의 밑거름이 되어 마치 예금에 이자가 붙듯 지식이 ‘복리(Compound)’로 불어나는 것입니다.
이 거대하고 똑똑한 도서관을 굴러가게 하는 언어는 복잡한 프로그래밍 코드가 아닙니다. 우리에게도 친숙한 가장 단순한 텍스트 형식인 ‘마크다운(Markdown)’입니다. 카파시는 마크다운이 글씨만 있는 가벼운 형태라 AI가 읽고 쓰기에 부하가 적고, 동시에 인간이 눈으로 보고 직접 수정하기도 가장 완벽한 형식임을 간파했습니다. 이 구조 속에서 인간과 AI의 역할은 완벽하게 나뉩니다. 인간은 호기심을 가지고 정보를 던져주며 질문하는 ‘탐험가’가 되고, 수많은 문서를 읽고 요약하고 분류하는 귀찮은 작업은 꼼꼼한 AI ‘사서’가 전담합니다.
최근에는 이 아이디어가 발전하여 AI의 치명적인 단점인 ‘환각(거짓말)’을 원천 차단하는 기능까지 생겼습니다. 예를 들어, 어떤 시스템은 AI가 글을 쓸 때 “정확히 몇 페이지의 어떤 문서를 보고 쓴 것인지” 영수증(인용구)을 첨부하지 않으면 그 문장을 아예 등록조차 못 하게 기계적으로 막아버립니다.
LLM 위키는 중요한 사실을 증명했습니다. AI는 단순히 답변하는 존재가 아니라, 사람이 없는 시간에도 묵묵히 지식을 정리하는 지식 노동자가 될 수 있다는 점입니다.
그렇다면 질문은 자연스럽게 확장됩니다.
“AI가 정리를 넘어서
스스로 생각의 회로를 연결할 수는 없을까?”
이 질문에 가장 과감한 실험으로 답한 인물이 있습니다.
“당신이 잠든 사이, 뇌의 신경망이 연결된다”:
개리 탄(Garry Tan)의 ‘GBrain’
앞서 ‘LLM 위키’가 꼼꼼한 사서를 고용해 도서관을 정리하는 느낌이었다면, 이번에는 AI 스스로 생각의 회로를 잇고 행동 지침을 만드는 ‘진화하는 두뇌’에 관한 이야기입니다. 바로 세계 최고의 스타트업 육성 기관인 와이 콤비네이터(Y Combinator)의 CEO 개리 탄(Garry Tan)이 직접 개발한 ‘GBrain(지브레인)’입니다.
놀랍게도 개리 탄은 단 12일 만에 자신만의 개인 AI 비서들을 움직이는 이 ‘두뇌’를 완성했습니다. 그리고 이 시스템은 현재 1만 7천 개가 넘는 페이지와 수천 명의 인물 데이터를 스스로 관리하는 거대한 신경망으로 성장했습니다. 과연 무엇이 달랐던 걸까요?
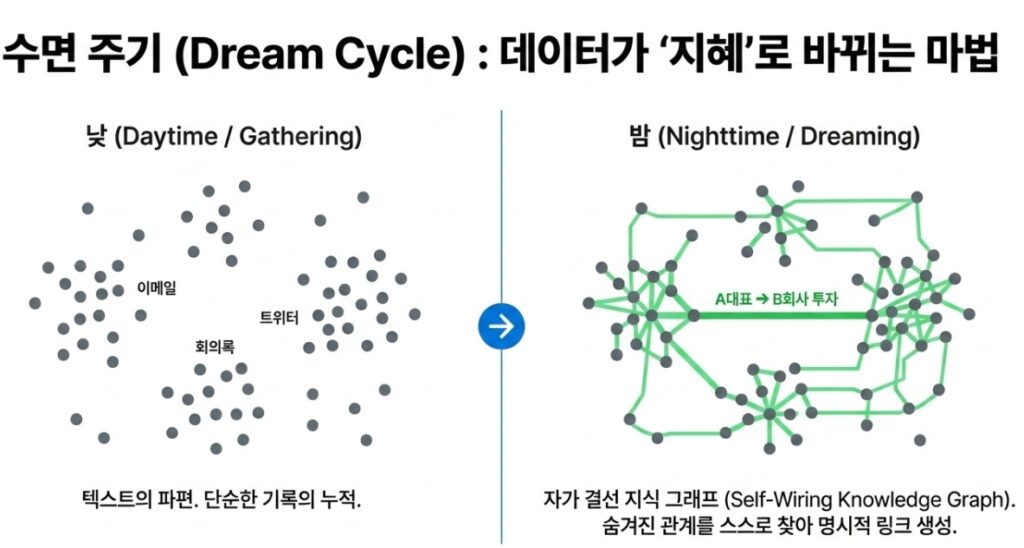
GBrain의 가장 소름 돋는 기능은 바로 당신이 잠든 새벽에 일어납니다. 이를 ‘수면 주기(Dream Cycle)’ 최적화라고 부릅니다. 당신이 하루 종일 업무를 보며 쏟아낸 수많은 이메일, 회의 녹음 파일, SNS의 글들을 상상해 보세요. 일반적인 AI라면 그저 텍스트 덩어리로 어딘가에 저장해 두고 끝낼 것입니다. 하지만 당신이 컴퓨터를 끄고 잠자리에 들면, GBrain은 조용히 깨어납니다.
AI는 수집된 메모들을 스스로 샅샅이 읽어 내려가며 흩어진 조각들을 꿰맞추기 시작합니다. “아, 오늘 회의록을 보니 A 대표가 B 회사에 투자했구나”, “이 이메일을 보니 C가 예전에 D 회사에서 일했네?”라며 텍스트 속의 숨은 관계를 파악합니다. 그리고 추가적인 명령이 없어도 스스로 ‘A는 B에 투자함’, ‘C는 D에서 근무함’이라는 명시적인 연결 고리를 척척 만들어냅니다. 이것이 바로 GBrain의 핵심인 ‘자가 결선 지식 그래프(Self-Wiring Knowledge Graph)’입니다.
마치 인간의 뇌가 밤에 잠을 자는 동안 낮에 겪은 기억을 정리하고 장기 기억으로 저장하듯이, 시스템이 스스로 깨진 링크를 고치고 정보의 신경망을 촘촘하게 연결하는 것입니다. 덕분에 다음 날 아침 당신이 눈을 뜨면, 당신의 AI 비서는 어제저녁보다 말 그대로 ‘물리적으로 훨씬 더 똑똑해져’ 있습니다. “이번 분기에 A 대표가 어떤 회사들에 투자했지?”라고 물으면, 단순 검색으로는 찾기 힘든 복잡한 관계망 속의 정답을 1초 만에 완벽하게 뽑아냅니다.
그렇다면 GBrain은 어떻게 AI가 엉뚱한 거짓말(환각)을 하지 않고 정확하게 일하도록 통제할까요? 여기서 개리 탄의 유명한 철학인 “얇은 줄(Harness)과 두꺼운 기술(Skills)”이 등장합니다.
쉽게 비유하자면, AI에게 너무 복잡하고 무거운 ‘지침서(줄)’를 한 번에 주지 않는다는 뜻입니다. 대신, “정보를 수집할 때”, “두뇌를 정리할 때”처럼 아주 세분화된 상황마다 어떻게 행동해야 하는지를 적어둔 작고 명확한 행동 수칙인 ‘스킬 파일(Skill File)’ 29개를 만들어 AI에게 쥐여주었습니다.
이 스킬 파일 역시 단순한 텍스트(마크다운) 형식입니다. AI는 막연하게 생각하지 않고, 주어진 스킬 파일의 절차대로만 움직입니다. 상상력과 추론이 필요한 영역과, 데이터베이스 검색처럼 기계적으로 딱 떨어져야 하는 영역을 완벽하게 분리하여 AI가 엉뚱한 행동을 할 가능성을 원천적으로 차단한 것입니다.
더욱 흥미로운 것은 이 AI가 스스로 학습(Self-Learning Loop)한다는 점입니다. AI가 실수를해서 주인이 피드백을 주면, AI는 그 피드백을 분석해 스스로의 ‘스킬 파일(행동 수칙)’을 수정해 버립니다. 복잡하게 프로그래밍 코드를 고치거나 비싼 돈을 들여 모델을 재학습시킬 필요 없이, 규칙 자체를 수정하며 경험을 쌓아가는 완벽한 시스템을 구축한 것입니다.
GBrain이 증명한 미래는 명확합니다. 진정한 AI 비서는 내가 부를 때만 튀어나와 대답하는 요술 램프의 지니가 아닙니다. 그것은 내 삶의 데이터를 자양분 삼아 보이지 않는 곳에서 스스로 뇌의 주름을 늘리고, 매일 아침 전날보다 더 똑똑한 상태로 나를 기다리는 완벽한 동반자입니다.

“똑똑한 AI 한 명보다 위대한 것은 ‘조직의 기억’이다”
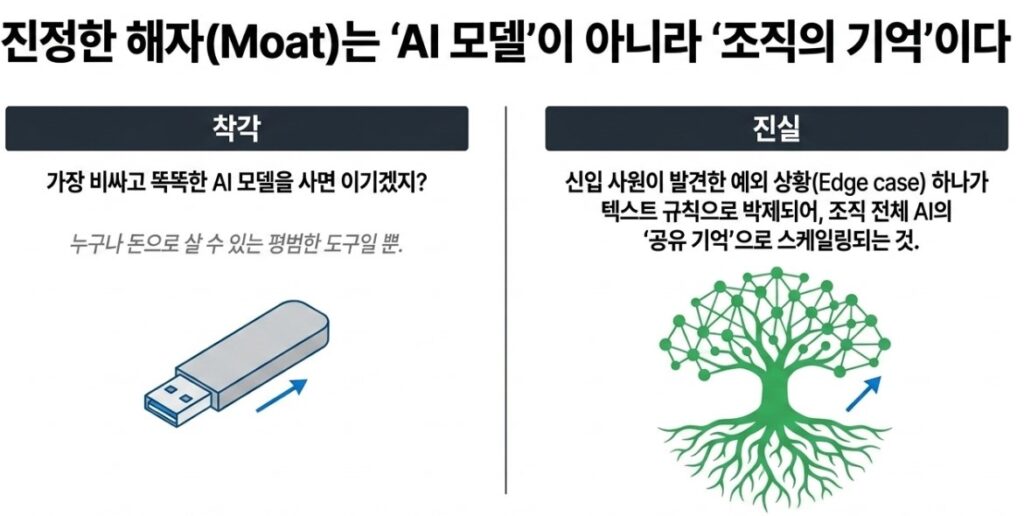
수많은 기업들이 최신 AI를 도입하며 이렇게 착각합니다. “우리가 세계에서 가장 똑똑한 AI 모델을 도입했으니, 이제 경쟁사들을 압도할 수 있겠지?” 하지만 앞서 살펴본 안드레아 카파시와 개리 탄의 결론은 단호합니다. 어차피 뛰어난 AI 모델 자체는 누구나 돈을 주면 쓸 수 있는 평범한 도구(범용화)가 될 것이라는 점입니다.
그렇다면 남들이 쉽게 따라올 수 없는 기업의 진짜 무기, 이른바 ‘해자(Moat)’는 어디에서 나올까요? 정답은 AI 모델 자체가 아니라, 직원들이 AI와 함께 일하며 쌓아 올린 ‘컴파일된 조직의 지식 계층(Compiled Organizational Knowledge Layer)’에 있습니다.
쉽게 비유해 보겠습니다. 아무리 요리를 잘하는 천재 셰프(최신 AI)를 스카우트하더라도, 그 셰프가 매일 퇴근할 때마다 레시피를 머릿속에서 지워버린다면 그 식당은 성장할 수 없습니다. 진짜 자산은 요리 과정에서 있었던 실수와 새로운 아이디어를 차곡차곡 적어둔 ‘비법 레시피 노트(지식 계층)’입니다.
지금의 기업 환경을 떠올려 보십시오. 어떤 직원이 AI와 채팅을 하며 오류를 발견하고 이를 수정하더라도, 그 소중한 피드백은 그 직원의 ‘개인 채팅 로그’ 속에 일회성으로 남았다가 허무하게 사라집니다. 하지만 ‘LLM 위키’나 ‘GBrain’ 같은 새로운 아키텍처에서는 다릅니다. 누군가 AI의 엣지 케이스를 발견하고 바로잡으면, 시스템은 이 경험을 읽고 쓰기 쉬운 텍스트(마크다운) 규칙으로 만들어 영구적으로 박제합니다.
즉, 신입 사원 한 명이 수정한 오류가 단숨에 조직 전체 AI의 ‘살아 숨 쉬는 공유 기억’으로 스케일링되는 것입니다. 이 폭발적인 복리 효과가 쌓인 기업의 AI와, 매일 아침 빈 백지상태로 출근하는 다른 기업의 AI는 불과 1년만 지나도 도저히 좁힐 수 없는 격차를 벌리게 됩니다.
하지만 여기서 아주 중요한 문제가 하나 생깁니다. 만약 이 거대한 ‘조직의 뇌’에 누군가 거짓말이나 잘못된 정보를 집어넣으면 어떻게 될까요? 거대한 지식 기반은 정보가 오염되는 순간 재앙을 맞이합니다.
그래서 최신의 AI 시스템들은 이른바 ‘인식론적 무결성(Epistemic Integrity)’, 즉 절대 거짓말에 속지 않고 진실만을 지켜내는 강력한 방어막을 내장하고 있습니다. 이들은 단순히 문서를 모아두는 창고가 아니라, 끊임없이 스스로의 건강을 검진하는 의사와 같습니다.
이 과정에서 등장하는 아주 흥미로운 개념이 바로 ‘실패의 무덤(Graveyard of failures)’입니다. 시스템을 쓰다가 AI가 헛소리를 하거나 치명적인 오류를 내어 사용자가 이를 신고(Flag)하면, 이 부끄러운 실수는 숨겨지는 것이 아니라 ‘실패의 무덤’이라는 테스트 케이스에 엄격하게 기록됩니다. 단 몇 주 만에 수백 개의 실패 사례가 누적되고, 앞으로 AI 시스템이나 버전을 업데이트할 때는 반드시 이 ‘실패의 무덤’에 있는 시험 문제들을 모두 통과해야만 실무에 투입될 수 있습니다.
아무도 관리하지 않는 단순한 백과사전은 몇 달 만에 낡은 정보의 쓰레기장으로 부패해 버립니다. 하지만 투명하게 기록되고, 오답에 대한 철저한 수정과 평가를 스스로 반복하는 지식 시스템은 그 어떤 경쟁사도 뚫을 수 없는 철벽같은 ‘진정한 기술적 해자’로 굳어지게 되는 것입니다.
거품이 걷힌 2026년, 세상은 이미 ‘AI 팀’과 ‘안전한 개인 두뇌’로 갈아타고 있다
안드레아 카파시와 개리 탄의 혁신적인 아이디어는 결코 천재들의 별난 발명품이 아닙니다. 이들이 증명한 ‘살아있는 지식’과 ‘복리형 시스템’의 철학은 2026년 현재, 전 세계 AI 생태계의 판도를 뒤엎는 거대한 해일이 되었습니다. 왜 이런 급격한 변화가 일어났을까요? 그것은 맹목적인 기대감으로 팽창했던 AI 거품이 걷히고, 시장이 냉혹한 현실의 벽, 이른바 ‘죽음의 계곡(Valley of death)’과 마주했기 때문입니다.
최근 조사에 따르면 AI 요원을 도입한 수많은 기업 중 실제 현장에서 의미 있는 수익을 낸 파일럿 프로젝트는 고작 5%에 불과했습니다. AI가 멍청해서가 아닙니다. 너무 예측 불가능했기 때문입니다. AI가 금융이나 의료 현장에서 치명적인 실수를 저질러도, 그 원인을 추적하거나 즉각 멈출 수 있는 ‘브레이크(거버넌스)’가 없었기 때문이죠.
그래서 2026년의 시장은 무작정 몸집만 큰 거대 모델을 맹신하는 것을 멈추었습니다. 대신 AI의 행동을 투명하게 기록하고 실시간으로 통제하는 ‘안전 인프라’ 구축에 사활을 걸기 시작했습니다. 이와 동시에 기업들은 수동적인 검색(RAG)을 과감히 버리고 있습니다. 단순한 단어 맞추기가 아니라, 문서 간의 복잡한 인과관계를 명확한 지도로 그려주는 ‘지식 그래프(GraphRAG)’ 기술로 대이동을 시작한 것입니다.
또 하나 재미있는 변화는 ‘슈퍼맨 AI’에 대한 환상이 깨졌다는 점입니다. 모든 것을 다 아는 만능 AI 한 명에게 일을 몽땅 맡기는 대신, 이제는 각자의 특기가 다른 AI 요원들이 한 팀을 이뤄 협력하는 ‘다중 에이전트 시스템(MAS)’이 대세가 되었습니다. 예를 들어 소프트웨어 개발 분야에서는 코드를 짜는 요원, 버그를 잡는 요원, 설명서를 쓰는 요원이 마치 실제 사람들의 개발팀처럼 자율적으로 토론하며 결과물을 냅니다. 실제로 내 캘린더를 확인하고 데이터베이스와 직접 소통하며 물리적인 행동을 취하는 ‘OpenClaw’ 같은 실행형 요원들이 폭발적인 인기를 끌며 시장을 장악하고 있습니다. 바야흐로 ‘에이전틱 엔지니어링(Agentic Engineering)’의 시대가 활짝 열린 것입니다.
마지막으로 우리의 피부에 가장 크게 와닿는 트렌드는 바로 ‘프라이버시’입니다. AI가 내 삶의 패턴과 회사의 비밀을 낱낱이 파악하며 똑똑한 ‘제2의 뇌’로 진화할수록, 이 모든 민감한 정보를 외부 클라우드 서버에 넘겨야 한다는 공포감 역시 극에 달했습니다.
그래서 2026년의 지식 시스템은 완벽한 ‘로컬 퍼스트(Local-First)’로 빠르게 재편되고 있습니다. 굳이 비싼 외부 인터넷 API에 의존할 필요 없이, 내 스마트폰이나 노트북에 내장된 ‘소형 언어 모델(SLM)’이 내 데이터를 안전하게 읽고 지식으로 엮어냅니다. 최신 소형 모델들은 거대 모델보다 훨씬 저렴하면서도 놀라운 추론 능력을 발휘합니다. 덕분에 우리는 정보 유출의 찜찜함은 완전히 날려버리고, 오직 나만을 위해 내 기기 안에서 안전하게 진화하는 ‘개인화된 자율 두뇌’를 온전히 소유하게 된 것입니다.

지능을 소유하는 시대는 끝났다. 이제는 ‘지능이 자라날 토양’을 설계하라
우리는 오랫동안 “누가 더 똑똑한 AI 모델을 가졌는가”를 경쟁해 왔습니다.그러나 2026년의 질문은 완전히 달라졌습니다. “이 AI는 어제 배운 것을, 오늘도 기억하는가?” 안드레아 카파시의 LLM 위키와 개리 탄의 GBrain은 분명히 말합니다. “진짜 경쟁력은 모델의 크기가 아니라, 기억이 남는 구조, 규칙이 축적되는 시스템, 실패가 자산이 되는 토양에 있다고.”
매일 기억을 잃는 천재에게 일을 맡길 것인가, 아니면 매일 밤 스스로 똑똑해지는 조직의 두뇌를 키울 것인가? 미래의 승자는 지능을 ‘가진’ 기업이 아니라, 지능이 자라날 구조를 만든 기업이 될 것입니다.




