
인간은 컵을 집으려 손을 뻗기 전에 이미 다양한 가능성을 자연스럽게 고려합니다. 손이 미끄러지지는 않을지, 컵이 비어 있는지, 물이 들어 있다면 쏟아지지는 않을 지와 같은 상황을 별도의 의식적인 계산 없이도 직관적으로 판단합니다. 심지어 테이블이 흔들린다면 어떤 일이 일어날지도 무의식적으로 예측합니다. 다시 말해, 인간은 행동에 앞서 그 결과를 어느 정도 가늠한 상태에서 움직이게 됩니다.
그러나 지금까지의 로봇은 아직 이러한 방식으로 동작하지 않았습니다. 카메라를 통해 장면을 인식하고 학습된 정책에 따라 팔을 움직이기는 했지만, 그 행동이 만들어낼 결과를 미리 떠올리거나 검토하는 과정은 거의 존재하지 않았습니다. 로봇은 “보는 것”과 “행동하는 것”을 연결하는 데에는 성공했지만, 그 사이에 필요한 “행동의 결과를 예측하는 단계”는 충분히 구현되지 않은 상태입니다.
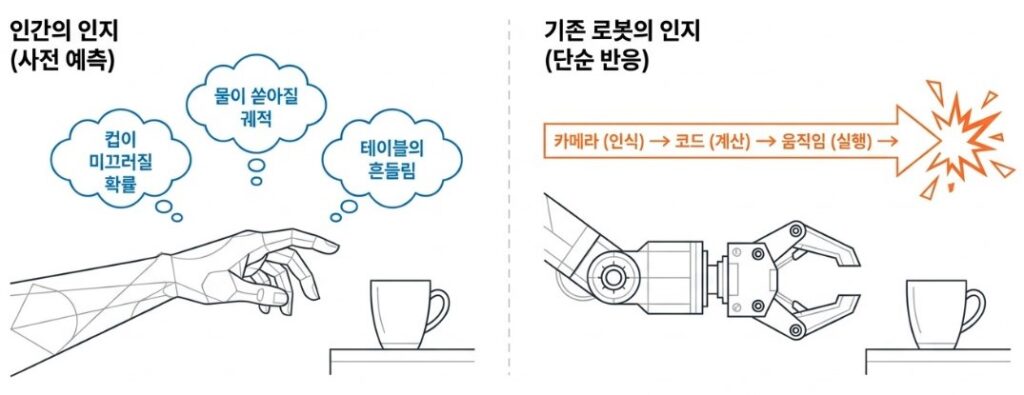
이 차이는 단순한 기능의 부족이 아니라 지능의 본질적인 차이를 드러냅니다. 인간의 행동이 안정적이고 유연한 이유는 단순히 피드백에 빠르게 반응하기 때문이 아니라, 애초에 발생할 수 있는 다양한 상황을 미리 감안하고 행동하기 때문입니다. 반면 로봇은 시행착오를 통해 학습된 정책을 기반으로 움직였기 때문에, 예상하지 못한 환경 변화나 상황에 쉽게 무너지는 모습을 보였습니다. 이러한 구조는 결국 ‘사고 없는 행동’에 가까운 방식으로 볼 수 있습니다.
결국 로보틱스 분야가 직면했던 핵심 질문은 다음과 같습니다. 로봇은 언제부터 ‘행동하기 전에 생각하는 존재’로 전환될 것 인가라는 질문이었습니다.
기존 로보틱스의 구조적 한계
지난 몇 년간 로보틱스는 빠르게 발전해 왔습니다. RT-1, RT-2와 같은 모델, 그리고 비전-언어-행동을 통합하는 VLA(Vision-Language-Action) 모델들은 시각과 언어 정보를 직접 행동으로 연결하는 데 성공했습니다. 이를 통해 로봇은 더 다양한 작업을 수행할 수 있는 가능성을 보여주었고, 단순한 반복 기계에서 벗어나 점차 범용적인 행동 생성 시스템으로 진화해 왔습니다.
그러나 이러한 발전에도 불구하고 구조적인 한계는 여전히 존재했습니다. 대부분의 현대 로봇 시스템은 “현재 상태 → 즉각적인 행동”이라는 반응형 구조에 기반하고 있었습니다. 입력이 주어지면 그에 대응하는 출력을 생성하는 방식으로 동작했으며, 행동의 결과가 시간에 따라 어떻게 전개될 것인지에 대한 깊은 고려는 부족한 상태였습니다.
이러한 한계는 특히 장기적인 작업에서 뚜렷하게 드러났습니다. 겉보기에는 단순해 보이는 물 따르기와 같은 작업조차 실제로는 시간에 따라 변하는 복잡한 물리 상호작용의 연속이었습니다. 그러나 로봇은 각 순간의 행동만을 최적화하는 경향이 있었기 때문에, 작은 오차가 누적되면서 결국 전체 작업이 실패로 이어지는 경우가 많았습니다. 이는 흔히 ‘compounding error’ 문제로 이어졌습니다.
또한 학습 방식 자체에서도 근본적인 제약이 존재했습니다. 로봇은 여전히 대규모 실세계 데이터를 기반으로 학습해야 했으며, 이러한 데이터 수집 과정은 비용이 높고 위험했으며 속도 또한 매우 느렸습니다. 이를 보완하기 위해 시뮬레이션 기반 학습이 활용되었지만, 시뮬레이션에서 학습된 정책이 실제 환경에서 제대로 작동하지 않는 ‘Sim-to-Real Gap’ 문제가 발생했습니다.
이 문제의 본질은 명확합니다. 로봇은 세상을 ‘이해’하고 있는 것이 아니라, 특정 환경에서 잘 작동하는 행동 패턴을 ‘기억’하고 있는 수준에 머물러 있었습니다. 그러나 현실 세계는 이러한 분포를 끊임없이 벗어나기 때문에, 모델이 대응하지 못하는 상황이 계속해서 발생할 수밖에 없었습니다.
결국 기존 로보틱스는 강력한 행동 생성 능력을 확보했음에도 불구하고, 가장 중요한 능력 하나를 결여하고 있었습니다. 바로 “이 행동을 하면 어떤 일이 일어날 것인가”를 미리 판단하는 능력이었습니다.
그리고 이 지점에서 로봇이 세상을 바라보는 방식 자체를 바꾸는 새로운 접근이 필요해졌습니다.
World Model이란? “내 머릿속의 시뮬레이터”
이러한 문제를 해결하기 위한 핵심 개념으로 등장한 것이 바로 World Model입니다.
World Model은 단순한 인식 모델도, 단순한 행동 생성 모델도 아닙니다. 이는 현재의 상태와 특정 행동이 주어졌을 때, 미래 상태의 변화를 예측하는 모델입니다. 다시 말해, 로봇 내부에 하나의 ‘가상 세계’를 구축하여 그 안에서 다양한 시나리오를 미리 실행해보는 방식에 가깝습니다.
이 모델의 본질은 ‘예측’에 있습니다. 특정 물체를 밀었을 때 어떤 방향으로 움직일지, 컵을 기울였을 때 물이 어떻게 흐를지, 문을 잡아당겼을 때 열릴지 아니면 막혀 있을지를 사전에 계산하는 능력입니다. 이러한 예측은 단순한 시각적 상상이 아니라, 물리적 인과관계를 기반으로 한 시뮬레이션이어야 합니다.
여기서 중요한 점은 World Model이 단순한 비디오 생성 모델과는 본질적으로 다르다는 점입니다. World Model은 반드시 행동(Action)에 조건화된 예측을 수행해야 하며, 단순히 미래 장면을 생성하는 것이 아니라, “특정 행동을 했을 때 세계가 어떻게 반응하는가”를 계산하는 구조가 핵심입니다.
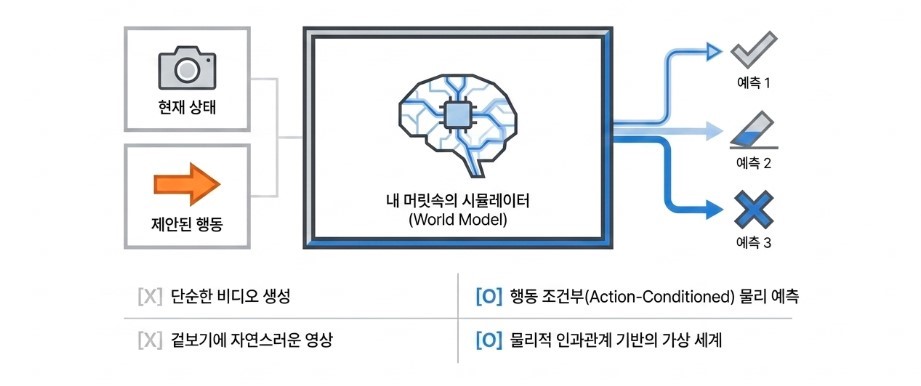
이러한 개념은 인간의 인지 방식과 매우 유사합니다. 인간은 실제로 행동하기 전에 다양한 결과를 머릿속에서 시뮬레이션하고, 그 결과를 바탕으로 행동을 선택합니다. World Model은 바로 이러한 ‘내적 시뮬레이션’ 능력을 기계 안에 구현하려는 시도라고 볼 수 있습니다.
기존의 로보틱스에서 perception이 세상을 인식하는 ‘눈’이었다면, policy는 몸을 움직이는 ‘근육’에 해당합니다. 그리고 World Model은 그 사이에서 작동하는 ‘상상력’ 혹은 ‘예측 능력’에 해당하는 요소입니다. 이 세 요소가 결합될 때 비로소 로봇은 단순히 반응하는 시스템을 넘어, 스스로 판단하고 선택하는 주체로 나아갈 수 있습니다.
이제 질문은 더 이상 “로봇이 무엇을 할 수 있는가”에 머물지 않으며, 그보다 더 근본적인 질문으로 확장되었습니다. 로봇은 세상을 얼마나 ‘미리 살아볼(예측해볼) 수 있는가’라는 질문으로 바뀌기 시작했습니다.
World Model이 다시 주목 받는 이유
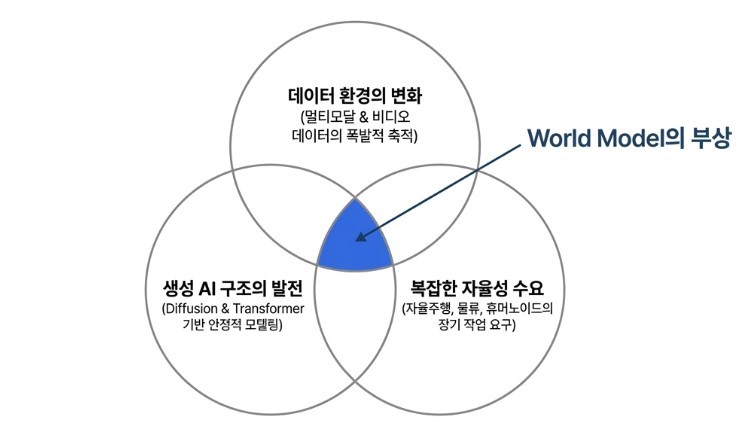
World Model이라는 개념 자체는 새로운 것이 아닙니다. 로보틱스와 강화학습 분야에서는 이미 오래 전부터 환경의 동역학을 모델링하고, 이를 기반으로 계획을 수행하려는 시도가 존재해 왔습니다. 그럼에도 불구하고 최근 들어 이 개념이 다시 강하게 부상하게 된 데에는 분명한 이유가 있습니다.
첫 번째 배경은 데이터 환경의 변화입니다.
과거의 로봇 학습은 대부분 제한된 실세계 데이터에 의존해야 했지만, 최근에는 대규모 비디오 데이터와 멀티모달 데이터가 폭발적으로 축적되기 시작했습니다. 이러한 데이터는 단순한 이미지 인식을 넘어, 시간에 따른 변화와 물리적 상호작용의 패턴까지 학습할 수 있는 기반을 제공하게 되었습니다. 즉, ‘세상이 어떻게 변하는가’를 학습할 수 있는 조건이 갖춰졌습니다.
두 번째는 모델 구조의 발전입니다.
디퓨전 모델과 트랜스포머 기반의 생성 모델은 복잡한 분포를 안정적으로 모델링 할 수 있는 능력을 보여주었습니다. 이러한 구조는 단순한 정적 데이터가 아니라, 시간에 따라 변화하는 시계열 데이터와 물리적 상호작용을 다루는 데에도 점차 활용되기 시작했고, 결과적으로, 이전에는 구현이 어려웠던 “현실적인 미래 상태 예측”이 기술적으로 가능해지는 단계에 도달하게 되었습니다.
세 번째, 그리고 가장 중요한 배경은 문제 자체의 변화입니다.
이제 로보틱스는 더 이상 단순한 반복 작업 자동화를 목표로 하지 않습니다. 자율주행, 물류 로봇, 휴머노이드와 같은 시스템에서는 복잡한 환경 속에서 상황을 이해하고, 장기적인 결과를 고려하며, 안전하게 행동하는 능력이 요구됩니다. 이러한 문제는 단순한 반응형 정책만으로는 해결이 어려운 영역입니다.
결국 World Model은 새로운 방향이기 때문에 등장한 것이 아니라, 지금의 로보틱스가 요구하는 문제를 해결하기 위해 자연스럽게 다시 중심으로 올라오게 된 개념이라고 볼 수 있습니다. 기술적 가능성과 문제의 요구가 맞물리면서, 비로소 현실적인 대안으로 자리 잡기 시작한 것입니다.
World Model은 어떻게 구현되고 있는가?
현재 World Model은 하나의 정형화된 구조로 수렴된 상태가 아니라, 서로 다른 접근이 경쟁하고 공존하는 있는 기술 영역입니다. “미래를 예측한다”는 공통된 목표를 공유하고 있지만, 이를 어떤 방식으로 구현할 것인가에 대해서는 뚜렷한 흐름들이 나뉘어 발전하고 있습니다. 그리고 주목할 점은, 이러한 흐름들이 특정 기업이나 연구 그룹을 중심으로 비교적 명확하게 형성되고 있다는 점입니다.
그 중 가장 직관적인 접근은 비디오 기반 World Model(Video World Model)입니다. 이 흐름은 과거의 관측과 행동을 기반으로 미래의 장면을 비디오 형태로 직접 생성하는 방식입니다. 최근에는 로봇 조작 상황에서의 정밀한 상호작용을 반영하려는 연구들이 등장하고 있으며, 대표적으로 2025년 ICCV에서 발표된 IRASim은 행동 조건(action-conditioned)을 프레임 수준까지 정밀하게 결합하여 로봇과 물체 사이의 상호작용을 보다 정확하게 모델링하려는 시도를 보여주었습니다. 또한 이 분야에서는 ByteDance, 여러 대학 연구팀, 그리고 자율주행 및 로보틱스 기업들이 비디오 기반 예측 모델을 중심으로 경쟁하고 있으며, 최근 NVIDIA 역시 Cosmos 플랫폼을 통해 video prediction 기반 world modeling을 핵심 축으로 밀고 있는 상황입니다. 이 접근의 특징은 직관적이고 해석이 쉬운 반면, 여전히 물리적 정확성보다는 시각적 일관성에 치우치기 쉽다는 한계를 함께 갖고 있습니다.
두 번째 흐름은 디퓨전 기반 World Model(Diffusion World Model)입니다. 이 접근은 diffusion 모델이 가진 “복잡한 분포를 안정적으로 생성하는 능력”을 활용하여, 환경 자체를 하나의 생성 모델로 다루려는 시도입니다. 2023년 이후 diffusion policy가 로보틱스 제어 영역에서 성과를 보이기 시작한 것을 계기로, 2025년 이후에는 이를 환경 예측까지 확장하려는 연구들이 본격화되었습니다. 대표적으로 2025년 발표된 World4RL은 diffusion 기반 world model을 고정된 환경으로 활용하여 실제 로봇을 사용하지 않고 정책을 개선하는 접근을 제안했습니다. 또한 University of Washington과 Toyota Research Institute가 공동으로 제안한 Unified World Model (2025)은 비디오와 행동을 모두 diffusion 구조로 통합 학습하는 방식을 통해, 정책, forward dynamics, inverse dynamics를 하나의 모델에서 동시에 처리할 수 있음을 보여주었습니다. 이 흐름은 특히 “실제 로봇 없이도 정책을 개선할 수 있다”는 점에서 산업적으로 큰 의미를 가지며, 정책 학습 비용을 낮추는 방향으로 주목받고 있습니다.
세 번째는 정책과 World Model의 통합(Unified / Joint Model)입니다. 이 접근은 기존처럼 “예측 모델 → 정책 모델”로 분리된 구조가 아니라, 하나의 모델 안에서 미래 예측과 행동 생성을 동시에 수행하려는 시도입니다. 이러한 방향은 최근 로보틱스 파운데이션 모델들의 흐름과 맞닿아 있습니다. 예를 들어, Physical Intelligence의 π0 (2024)는 비전-언어-행동 모델에 flow matching 기반의 연속 제어를 결합하여 정책 자체를 생성 모델로 바라보는 방향을 제시했으며, 여기에 world modeling적 요소를 결합하려는 후속 연구들이 빠르게 이어지고 있습니다. 또한 NVIDIA의 GR00T 계열이나 여러 foundation model 기반 로보틱스 프로젝트에서도 예측과 행동을 분리하는 대신 하나의 shared representation 안에서 다루려는 흐름이 확인되고 있습니다. 이 영역은 아직 명확한 표준이 정립되었다기보다는, “VLA 이후 구조가 어떻게 재편될 것인가”를 놓고 다양한 실험이 진행되는 단계라고 볼 수 있습니다.
마지막으로 점점 중요해지고 있는 접근은 잠재 공간 기반 World Model(Latent World Model / JEPA 계열)입니다. 이 흐름은 Yann LeCun이 지속적으로 강조해온 방향과도 연결되며, 픽셀 단위의 완전한 재구성이 아니라 행동과 예측에 필요한 핵심 정보만을 압축된 잠재 표현으로 예측하는 방식을 취합니다. 대표적으로 JEPA(Joint Embedding Predictive Architecture) 계열 모델은 “무엇이 변하는가”에 집중하여 불필요한 시각적 디테일을 제거하고, 모델이 중요한 구조적 변화에 집중하도록 유도합니다. 이는 실시간성, 계산 효율, 그리고 로봇 적용 가능성 측면에서 매우 중요한 방향으로 평가되고 있습니다.
이처럼 현재의 World Model 연구는 크게 “비디오 기반 예측, 디퓨전 기반 환경 생성, 정책과의 통합, 잠재 표현 기반 구조화”라는 네 가지 축을 중심으로 전개되고 있습니다.
중요한 점은 이 흐름들이 서로 완전히 경쟁적인 관계라기보다는, 서로 다른 문제를 해결하기 위한 상호보완적 접근일 가능성이 높다는 점입니다. 예를 들어, 비디오 기반 모델은 직관적인 예측을 제공하는 반면, 잠재 모델은 효율성을 제공하고, 디퓨전 모델은 안정적인 생성 능력을 제공하는 식입니다.
결국 향후 World Model의 표준은 이들 중 하나로 단순히 수렴되기보다는, “어떤 표현 방식으로 물리 세계를 가장 잘 압축하면서도, 행동과 연결할 수 있는가”라는 기준을 중심으로 재구성될 가능성이 높습니다. 그리고 이 과정 자체가 지금 로보틱스 분야에서 가장 중요한 경쟁의 한 축이 되고 있습니다.

로보틱스에서 World Model의 역할 변화
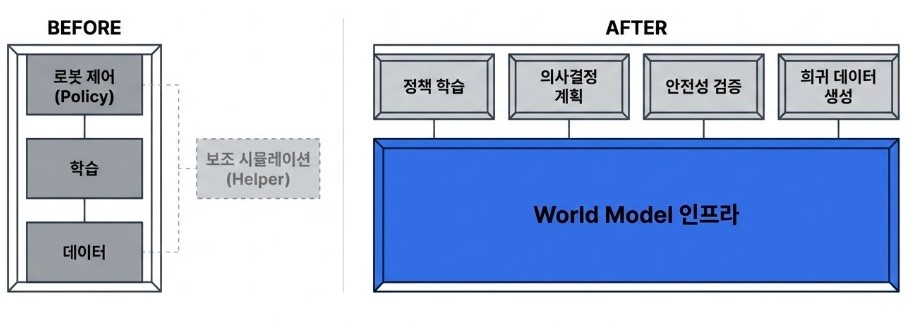
World Model은 단순히 기존 시스템에 추가되는 하나의 모듈로 이해하기에는 그 역할이 점차 확장되고 있습니다. 초기에는 계획이나 시뮬레이션을 보조하는 구성 요소로 도입되었지만, 최근에는 로봇 학습과 실행 전반을 재구성하는 핵심 인프라로 자리 잡아가고 있습니다.
우선 가장 직접적인 역할은 계획과 의사결정을 지원하는 것입니다. 로봇은 여러 가지 행동 후보를 실제로 수행하기 전에 내부 모델을 통해 각각의 결과를 예측하고, 그 중에서 가장 적절한 행동을 선택할 수 있습니다. 이는 단순한 정책 실행을 넘어, 선택과 판단의 과정을 포함하는 구조로의 전환을 의미합니다.
또한 World Model은 학습 환경으로서의 역할도 수행할 수 있습니다. 실제 로봇을 반복적으로 실험하지 않고도, 모델 내부에서 다양한 시나리오를 생성하고 정책을 학습하는 것이 가능해집니다. 이는 데이터 수집 비용과 시간 문제를 크게 완화할 수 있는 방향입니다.
이와 함께 검증과 평가의 기능도 중요해지고 있습니다. 예측 모델을 활용하여 위험한 행동이나 실패 가능성이 높은 시나리오를 사전에 걸러낼 수 있기 때문에, 실제 환경에서의 안전성을 높이는 데 기여할 수 있습니다. 특히 산업 현장이나 휴머노이드 로봇과 같이 안전성이 중요한 영역에서는 이러한 기능이 필수적으로 요구됩니다.
나아가 World Model은 데이터 생성의 역할까지 확장되고 있습니다. 현실에서 수집하기 어려운 극단적인 상황이나 희귀한 이벤트를 모델 내부에서 생성함으로써, 보다 다양한 상황에 대응할 수 있는 정책을 학습할 수 있게 됩니다.
이러한 변화는 World Model이 단순한 기능적 구성 요소를 넘어, 로봇 시스템 전체를 지탱하는 기반 역할로 이동하고 있음을 보여줍니다. 과거의 로보틱스가 센서-인식-제어로 구성된 파이프라인 구조였다면, 앞으로는 “예측을 중심으로 모든 요소가 연결되는 구조”로 재편될 가능성이 높아지고 있습니다.
결국 World Model은 로봇이 행동하는 방식을 바꾸는 기술이 아니라, 로봇이 세상을 이해하는 방식을 바꾸는 기술로 자리 잡아가고 있습니다.
World Model의 비즈니스적 가치
World Model의 의미는 연구실 안에만 머물러 있지 않습니다. 이 기술이 주목 받는 이유는 단지 로봇이 더 똑똑해질 수 있기 때문만이 아니라, 로봇 개발의 경제성과 산업적 구조 자체를 바꿀 가능성을 갖고 있기 때문입니다.
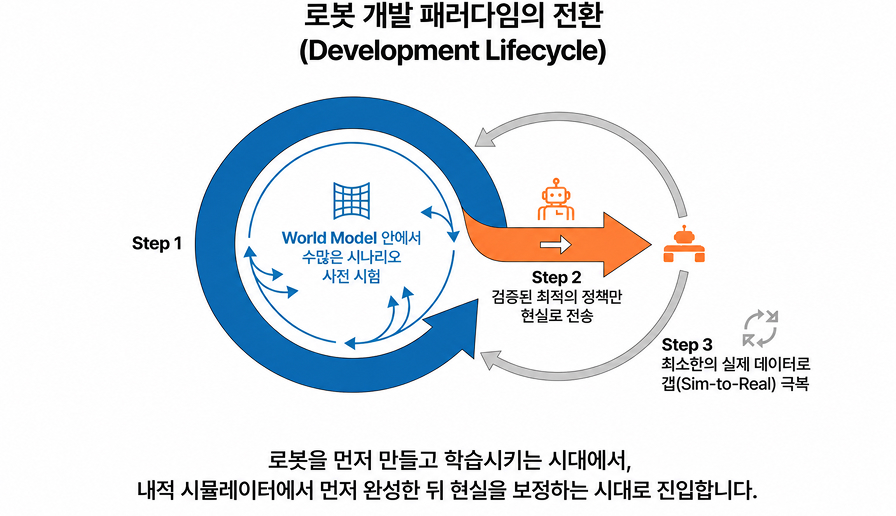
지금까지 로보틱스 산업의 가장 큰 병목 가운데 하나는 실세계 데이터 수집 비용이었습니다. 로봇이 새로운 작업을 익히기 위해서는 사람이 직접 시연하거나, 실제 장비를 반복적으로 움직이며 데이터를 쌓아야 했으며, 이 과정은 시간이 오래 걸릴 뿐 아니라 하드웨어 마모, 안전 문제, 인력 비용까지 동반했습니다. 특히 실패 데이터를 많이 모아야 하는 학습 방식에서는 이러한 부담이 더욱 커질 수밖에 없었습니다. 그래서 시뮬레이션은 오랫동안 유력한 대안으로 여겨졌지만, 기존 시뮬레이터는 현실의 복잡한 물리성과 불확실성을 충분히 담아내지 못한다는 한계를 안고 있었습니다. 이 지점에서 World Model은 단순한 ‘가상환경’이 아니라, 현실에서 수집하기 어려운 경험을 더 유연하게 생성하고 검토할 수 있는 새로운 학습 인프라로 주목 받고 있습니다.
산업 관점에서 보면 이는 단순한 성능 향상이 아니라 개발 방식의 전환을 의미합니다. 과거에는 실제 로봇을 먼저 만들고 데이터를 쌓은 뒤 정책을 학습하는 방식이 중심이었다면, 앞으로는 예측 모델 안에서 수많은 시나리오를 먼저 시험하고, 그 결과를 바탕으로 현실 시스템을 빠르게 보정하는 구조가 더 중요해질 수 있습니다. 특히 물류, 제조, 자율주행, 휴머노이드처럼 실환경 검증 비용이 큰 영역에서는 이 변화가 더욱 크게 작용할 가능성이 있습니다. NVIDIA가 Cosmos를 통해 물리 AI 개발을 위한 합성 데이터, 예측, 시뮬레이션 기반 파이프라인을 강조하고 있는 점이나, 여러 연구가 World Model을 정책 학습과 평가의 기반으로 보려는 흐름은 이러한 산업적 방향을 잘 보여줍니다.
또한 World Model은 단순히 “훈련 도구”로만 머무르지 않을 가능성이 있습니다. 실제 배포 단계에서도 위험한 행동을 사전에 걸러내는 검증 계층으로 활용될 수 있고, 희귀하지만 치명적인 상황을 미리 생성해 안전성을 높이는 데 활용될 수도 있습니다. 다시 말해, World Model은 로봇을 더 잘 움직이게 만드는 기술인 동시에, 로봇을 더 안전하게 개발하고 더 싸게 반복 학습시키는 기술이기도 합니다. 이 때문에 이 기술은 성능 경쟁의 수단을 넘어, 로보틱스 비즈니스의 비용 구조와 ROI를 바꾸는 핵심 변수로 점점 부상하고 있습니다.
World Model의 현실적인 한계
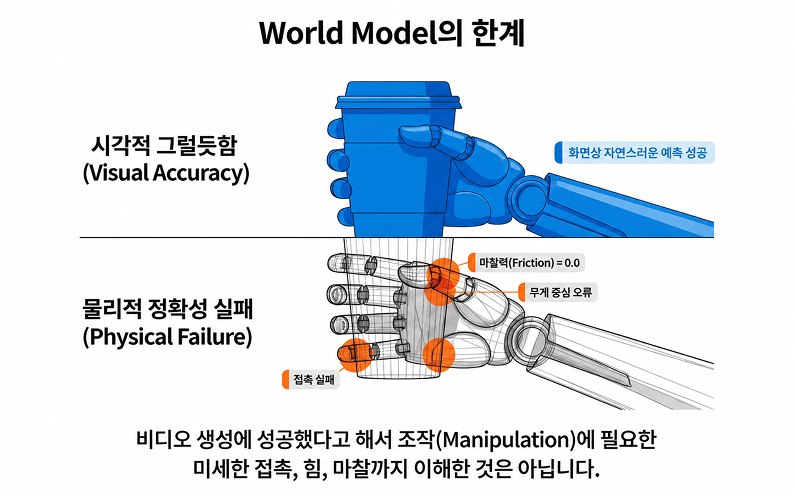
다만 World Model을 차세대 로보틱스의 해법으로만 보는 시각에는 분명한 주의도 필요합니다. 최근 들어 “world model”이라는 표현이 널리 사용되면서, 그 의미 자체가 다소 느슨해지고 있기 때문입니다. 실제로 여러 연구자들은 현재 world model이라 불리는 많은 시스템이 엄밀한 의미의 “세계 모델”이라기보다는, 여전히 비디오 예측 모델에 가까운 경우가 많다고 지적하고 있습니다. 즉, 겉으로 보기에는 그럴듯한 미래 장면을 생성할 수 있지만, 로봇에게 정말 중요한 접촉, 힘, 마찰, 무게 변화, 촉각과 같은 물리 신호를 충분히 다루지 못하는 경우가 많다는 것입니다.
이 문제는 특히 로봇 조작에서 더 민감하게 드러납니다. 화면상으로는 자연스러워 보이는 예측이 실제 물리 세계에서는 전혀 실행 가능하지 않을 수 있기 때문입니다. 예를 들어, 컵을 집는 장면을 잘 생성했다고 해서 실제 그립 안정성이나 미끄러짐, 힘 조절까지 정확히 예측했다고 볼 수는 없습니다. 그래서 최근에는 로봇 조작에 특화된 World Model 연구들이 단순 영상 생성이 아니라, 프레임 단위의 행동 정렬, 더 정밀한 상호작용 예측, 3D/4D 구조 반영 등으로 발전하고 있습니다. 그러나 이 역시 아직은 초기 단계이며, 실제 산업 환경에서 충분히 신뢰할 만한 수준의 일반 해법이 확립되었다고 보기는 어렵습니다.
또 하나의 큰 문제는 평가입니다. 언어 모델은 상대적으로 정형화된 벤치마크나 텍스트 기반 평가가 가능하지만, 로봇용 World Model은 그렇지 않습니다. 모델이 생성한 미래가 “그럴듯해 보이는가”와 “실제로 물리적으로 맞는가”는 전혀 다른 문제입니다. 그 결과, 어떤 World Model이 진짜로 더 좋은지, 실제 로봇 성능과 얼마나 강하게 연결되는지, 안전성에 어떤 기여를 하는지를 공통된 기준으로 판단하기가 어렵습니다. 로보틱스 분야에서 범용적인 측정 프레임워크가 부족하다는 지적이 계속 나오는 이유도 여기에 있습니다.
결국 현재의 World Model은 분명 유망한 기술이지만, 아직은 기대와 현실 사이에 차이가 존재합니다. 지금 필요한 것은 과도한 낙관이 아니라, 무엇이 진짜로 해결되었고 무엇은 아직 남아 있는지를 냉정하게 구분하는 태도입니다. 그래야만 이 기술이 단순한 유행어가 아니라, 실제 로보틱스의 기반 기술로 자리 잡을 수 있습니다.
World Model의 다음 단계
그렇다면 앞으로의 로보틱스에서 World Model은 어떤 방향으로 발전하게 될까요. 현재의 흐름을 보면, 이 기술은 단독 모듈로 남기보다는 로봇의 다른 핵심 구성 요소와 점점 더 깊게 결합되는 방향으로 발전할 가능성이 높습니다.
첫 번째 흐름은 VLA와의 통합입니다. 지금까지 VLA는 “무엇을 해야 하는가”를 이해하고 행동으로 연결하는 데 강점을 보여주었지만, 장기 예측과 물리적 결과 검토에는 한계가 있었습니다. 반대로 World Model은 미래를 예측하는 능력에 초점을 맞추고 있습니다. 앞으로는 이 둘이 분리된 체계로 존재하기보다, 의미 이해와 행동 생성, 미래 예측이 하나의 구조 안에서 보다 긴밀하게 얽히는 방향으로 진화할 가능성이 큽니다. 실제로 최근 연구들 가운데서는 비디오 확산과 행동 확산을 함께 다루거나, 정책과 환경 예측을 하나의 모델 안에서 유연하게 수행하려는 시도가 등장하고 있습니다.
두 번째는 멀티센서 기반 확장입니다. 지금의 많은 World Model은 시각 중심으로 설계되어 있지만, 실제 물리 세계를 다루기 위해서는 촉각, 힘, 토크, 접촉 타이밍과 같은 신호가 매우 중요합니다. 특히 정교한 조작이나 장기 작업에서는 이러한 정보가 시각보다 더 핵심적인 경우도 많습니다. 최근 산업 현장과 덱스터리티 중심 로보틱스에서 촉각과 힘 정보를 함께 통합하려는 움직임이 강해지는 것도 같은 맥락으로 볼 수 있습니다. 장기적으로는 “보는 것”만이 아니라 “느끼는 것”까지 포함한 예측 구조가 World Model의 중요한 진화 방향이 될 가능성이 높습니다.
세 번째는 3D/4D 구조화입니다. 앞으로의 World Model은 단순히 다음 프레임을 잘 그리는 방향에 머무르기보다, 시간 축을 포함한 공간 구조를 더 안정적으로 내재화하는 방향으로 발전할 가능성이 큽니다. 즉, 2D 비디오의 외형적 자연스러움에서 벗어나, 객체의 위치, 깊이, 움직임, 상호작용을 더 일관된 공간적 표상 안에서 다루는 방향입니다. 이는 장기 계획, 다중 시점 예측, 휴머노이드 조작과 같은 과제에서 특히 중요합니다. 최근 4D 장면 이해와 구조적 일관성을 강조하는 연구들이 등장하는 것도 이러한 흐름의 일부로 볼 수 있습니다.
마지막으로, World Model은 정책과 함께 공동 진화하는 방향으로 발전할 가능성이 있습니다. 즉, 모델은 정책이 실패한 사례를 통해 더 나은 예측 구조를 학습하고, 정책은 개선된 모델 안에서 더 높은 수준의 계획과 탐색을 수행하는 방식입니다. 이 경우 World Model은 단순한 보조 시뮬레이터가 아니라, 로봇 지능의 성장을 지속적으로 증폭시키는 내부 학습 환경이 될 수 있습니다. 최근 일부 발표와 분석에서 world model–policy co-evolution 또는 예측 기반 평가 구조가 강조되는 배경이 바로 여기에 있습니다.
요약하면, 앞으로의 World Model은 더 크고 더 화려한 생성 모델이 되는 방향보다, 의미 이해·물리 예측·멀티센서 통합·계획·검증이 결합된 예측 인프라로 발전할 가능성이 더 높습니다. 그리고 이 변화는 로봇이 단지 잘 움직이는 시스템을 넘어, 스스로 결과를 가늠하며 행동을 선택하는 시스템으로 나아가게 할 것입니다.
World Model이 바꾸는 로봇의 미래
지금까지의 로보틱스는 크게 두 단계로 발전해 왔다고 볼 수 있습니다.
첫 번째 단계는 로봇이 정해진 작업을 반복 수행하는 자동화 기계의 시대였습니다. 정해진 규칙 안에서는 뛰어난 성능을 발휘했지만, 새로운 상황에 대한 적응력은 제한적이었습니다.
두 번째 단계는 VLA(Vision-Language-Action) 모델의 등장과 함께 시작되었습니다. 로봇은 시각과 언어를 이해하고, 이를 바탕으로 보다 유연하게 행동할 수 있게 되었습니다. 단순히 명령을 수행하는 수준을 넘어, 상황을 해석하고 적절한 행동을 선택하는 방향으로 발전하기 시작한 것입니다.
그리고 이제 로보틱스는 세 번째 단계로 넘어가고 있습니다. 그것은 로봇이 행동만 하는 시스템이 아니라, 행동의 결과를 미리 예측하고 그 예측을 바탕으로 선택하는 시스템으로 진화하는 단계입니다.
이 변화가 중요한 이유는, 물리 세계에서는 단 한 번의 실수가 텍스트 생성의 오류보다 훨씬 더 큰 결과를 낳기 때문입니다. 언어 모델은 틀린 답을 다시 생성하면 되지만, 로봇의 잘못된 행동은 물체를 망가뜨리거나 사람을 다치게 하거나 시스템 전체의 신뢰를 무너뜨릴 수 있습니다. 그렇기 때문에 Physical AI의 핵심은 단순한 생성 능력이 아니라, 결과를 미리 가늠하고 위험을 줄이며 장기적인 맥락 속에서 행동을 조정하는 능력에 있습니다.
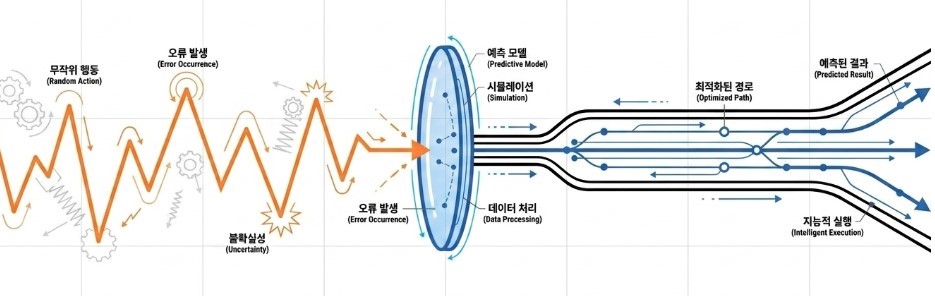
World Model이 중요한 이유도 바로 여기에 있습니다. 물론 아직 해결해야 할 과제는 많습니다. World Model이라는 이름 아래 서로 다른 방식들이 혼재되어 있고, 실제 물리 세계와 얼마나 정확히 연결되는가에 대한 검증도 더 필요합니다. 하지만 분명한 것은, 로보틱스가 이제 단순한 반응형 지능만으로는 다음 단계로 넘어가기 어렵다는 점입니다. 로봇이 더 복잡한 환경에서 더 긴 시간 동안 더 다양한 작업을 안전하게 수행하려면, 결국 내부에 어떤 형태로든 “세상의 변화를 예측하는 구조”를 가져야 합니다. 결국 World Model은 하나의 유행하는 키워드가 아니라, 로봇 지능이 다음 단계로 넘어가기 위해 반드시 거쳐야 할 전환점일 수 있습니다.
지금 이 분야에서 벌어지고 있는 변화는 단순히 더 정교한 비디오를 생성하는 기술 경쟁이 아닙니다. 그것은 로봇이 세상을 어떻게 이해할 것인가, 그리고 그 이해를 바탕으로 어떻게 행동할 것인가를 다시 정의하는 과정입니다.
이제 중요한 질문은 “로봇이 무엇을 할 수 있는가”만이 아닙니다. 그보다 더 본질적인 질문이 남아 있습니다.
“로봇은 행동하기 전에, 세상을 얼마나 정확하게 가늠할 수 있는가?”
World Model은 바로 그 질문에 대한 가장 본격적인 답변이 되기 시작했습니다.



