
When Vision Meets Language: Definition and Status of VLM
Vision-Language Models (VLM) were born at the intersection of Computer Vision (CV) and Natural Language Processing (NLP). Moving beyond simple image captioning, VLMs are evolving into “Multimodal Agents” capable of complex logical reasoning and autonomous action, allowing machines to perceive the visual world and infer meaning through language.
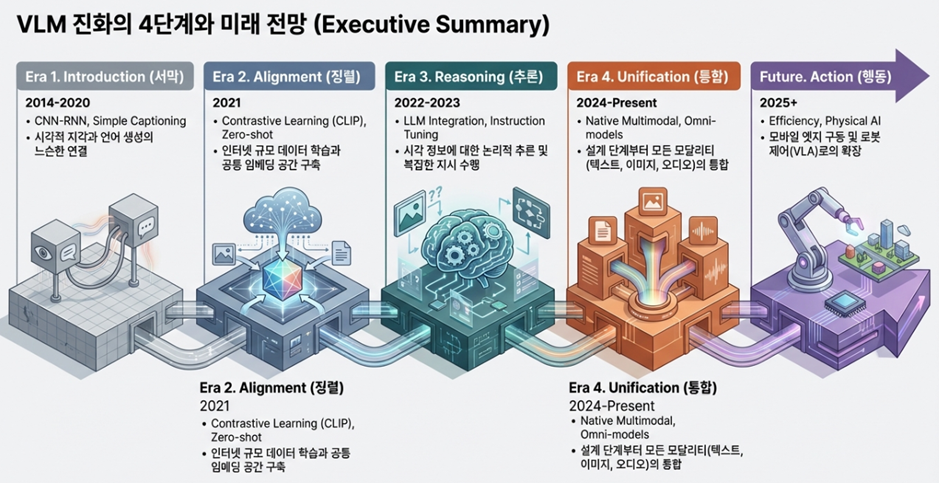
This article analyzes the technological leaps of the past decade, focusing on key eras: the CNN-RNN pipeline, the contrastive learning revolution, integration with Large Language Models (LLM), and native multimodality, while looking forward to the future of Physical AI.
[2014-2020] The Prelude to Integration: The CNN-RNN Pipeline
Early VLM research was dominated by modular architectures optimized for specific tasks. The focus was on physically connecting visual perception with linguistic generation.
- Technical Mechanism: The representative structure combined a Convolutional Neural Network (CNN) as the visual encoder with a Recurrent Neural Network (RNN) as the language decoder. Models like m-RNN (Multimodal Recurrent Neural Network) laid the foundation for interaction by directly inserting visual features from the CNN into the intermediate layers of the RNN.
- Key Tasks: Image Captioning and Visual Question Answering (VQA) were the core research goals. Around 2015, techniques to align sentence fragments with specific image regions were introduced.
Note: The m-RNN (Multimodal Recurrent Neural Network)
The m-RNN is a deep learning architecture designed to combine visual information from images with linguistic information from natural language. Its primary goals are to generate image descriptions (Image Captioning) or measure the similarity between images and text.
Proposed around 2014–2015 by the Baidu Research team (Junhua Mao et al.), this model was evaluated at the time as an innovative structure that successfully bridged the gap between computer vision and natural language processing (NLP).
Technical Characteristics and Limitations of Early VLMs

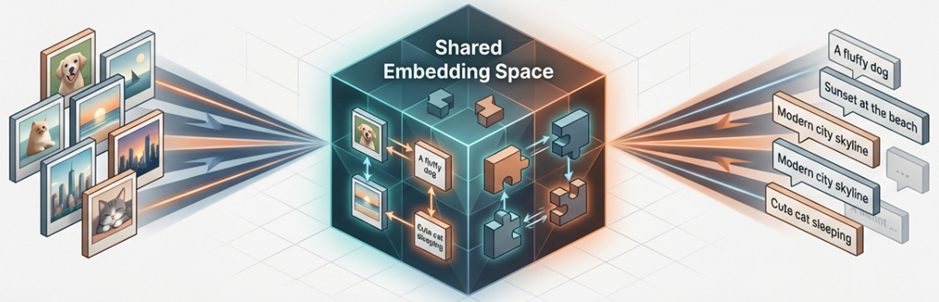
[2021] The Contrastive Learning Revolution: CLIP and Common Embedding Spaces
The emergence of OpenAI’s CLIP (Contrastive Language-Image Pre-training) in 2021 was a landmark event that shifted the paradigm from supervised learning to internet-scale, data-driven Contrastive Learning.
- Paradigm Shift: Moving beyond fixed category labels, models began learning universal representations using 400 million image-text pairs from the web.
- CLIP’s Innovation: It projects both text and visual encoders (ViT) into the same high-dimensional vector space. By using a Symmetric Cross-entropy Loss to increase the similarity of matching pairs, it secured Zero-shot transfer capabilities, allowing it to understand new concepts without additional fine-tuning.
- Data Engineering Trends: Google’s SigLIP improved this by introducing a Sigmoid loss to overcome batch size limitations. This momentum led to the creation of massive open datasets like LAION-5B, which became the bedrock for generative AI like Stable Diffusion.
Note: LAION-5B Dataset
LAION-5B is the largest and most representative open-source multimodal dataset in the world. Produced by the German non-profit organization LAION (Large-scale Artificial Intelligence Open Network), it has served as the essential foundation that enabled the explosive development of modern generative AI, including models like Stable Diffusion.
[2022-2023] Integration with LLMs and Instruction Tuning
During this period, VLMs evolved by coupling powerful LLMs with multimodal interfaces. Models gained the ability to follow complex user instructions and reason based on visual information.
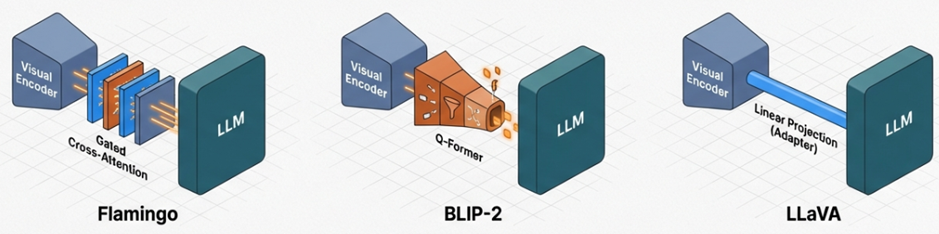
Gated Cross-attention (Flamingo)
DeepMind’s Flamingo inserted new cross-attention layers between fixed LLM layers. It used a “tanh gating” mechanism to gradually introduce visual information, ensuring stable training without disrupting the existing language model weights.
Query Transformer (BLIP-2)
BLIP-2 introduced the Q-Former module, which selectively extracts and delivers information between the visual encoder and the LLM. The Q-Former uses a small number of learnable query tokens to extract only the most useful information for text generation from the image encoder. This information is then projected into the LLM’s embedding space. This approach resolved the bottleneck in visual information and gained significant attention for its efficiency, enabling vision-language alignment with a very small number of trainable parameters.
Linear Projection and MLP Adapters (LLaVA)
LLaVA popularized the Linear Projection method, which is both simple and powerful. In the LLaVA architecture, visual feature vectors from CLIP are mapped directly into the LLM’s input token embedding space through a simple linear layer or a two-layer MLP. These converted visual tokens are arranged alongside text tokens and fed into the LLM, which processes them as a standard text sequence. LLaVA 1.5 and LLaVA-NeXT further improved performance by introducing techniques to divide high-resolution images into multiple tiles, drastically enhancing OCR and precise visual reasoning capabilities.
Comparative Analysis of Vision-Language Connection Architectures

- Learning Strategies: Beyond simple image captioning, Synthetic Data generated by powerful models like GPT-4 has become the core of modern training strategies. In particular, datasets such as ShareGPT4V provide highly detailed visual descriptions, training models to reason about precise spatial relationships that were previously difficult to capture.
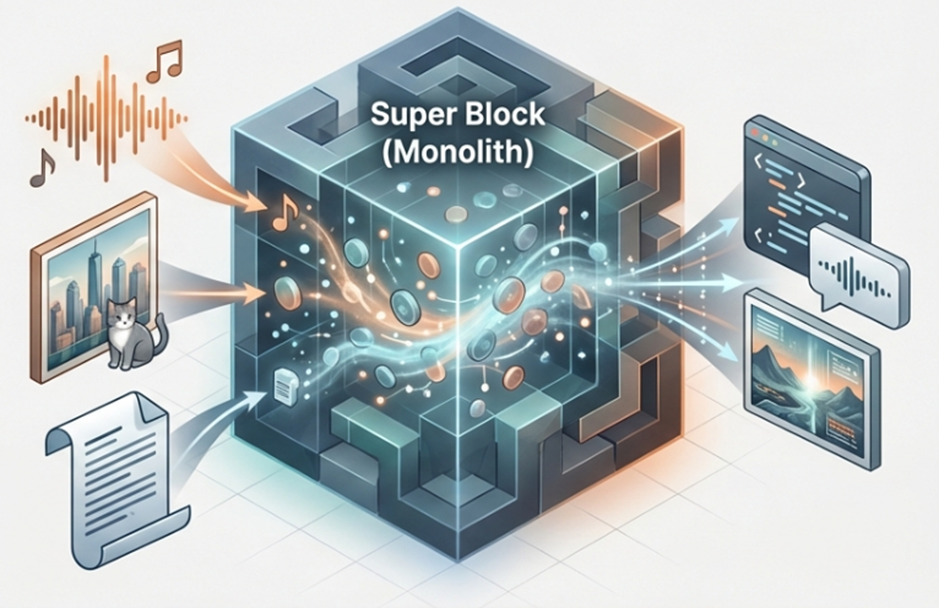
[2024] The Era of Native Multimodality and Frontier Models
The year 2024 marked the beginning of the Native Multimodal era, where all modalities are processed collectively starting from the initial model design phase. Through Omni-modal Tokenization, text, images, and audio are handled within a single unified space without the need for separate adapters.
Inherent Architectural Integration: Omni-modal Tokenization
The core of native multimodal models is that they no longer rely on attaching a separate visual encoder via an adapter. For example, Google’s Gemini 1.5 Pro is designed based on a Sparse Mixture-of-Experts (MoE) Transformer architecture. It was trained from the earliest stages of learning to simultaneously process text, images, audio, and video within a unified high-dimensional embedding space.
Analysis of 2024 Frontier VLM Models

- Core Technologies: Technologies for Dynamic Resolution Management, which generates tiles according to the aspect ratio of the input image, and processing video as Parallel Streams with interleaved audio-video tokens, have reached maturity.
[2025-2026] Practicality and Reliability: Edge AI and Hallucination Mitigation
The latest VLM research is moving beyond simply increasing model size to focus on efficient operation on mobile devices and securing the reliability (grounding) of responses.
- On-Device VLM: To overcome memory bandwidth limitations, 4-bit Quantization has become the standard, and extreme lightweight technologies such as BitNet (1.58-bit) have emerged. Additionally, Speculative Decoding, where a small model generates and a large model verifies, and lightweight Mixture-of-Experts (MoE) technologies are being actively utilized.
- Reliability Metrics: To measure visual hallucinations, the following three metrics have become increasingly important
- CPS (Conditional Prompt Sensitivity): Measures the impact of differences in prompt structure on hallucinations.
- CMV (Conditional Model Variability): Measures the vulnerability of the model architecture within the same prompt.
- JAS (Joint Attribution Score): Measures the interaction where the prompt and architecture combine to amplify errors.
- CPS (Conditional Prompt Sensitivity): Measures the impact of differences in prompt structure on hallucinations.
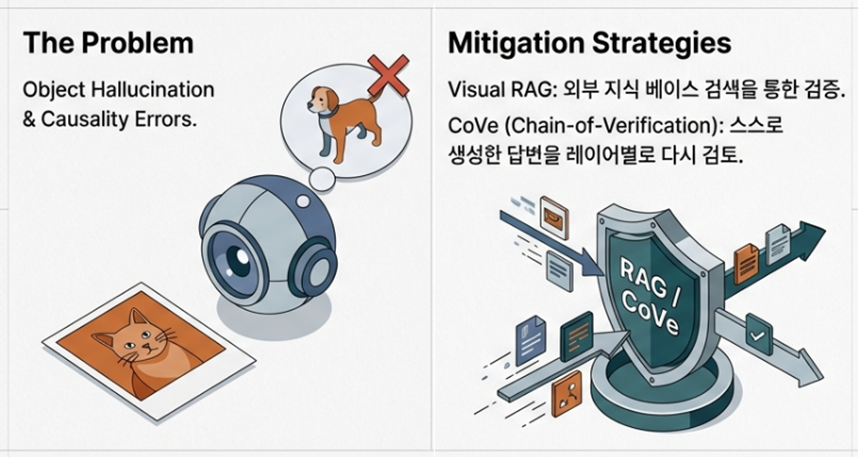
- Mitigation Strategies: To suppress visual hallucinations, RAG (Retrieval-Augmented Generation), which retrieves external knowledge, and CoVe (Chain-of-Verification), a technique where the model self-verifies its answers, are being actively implemented.
[Beyond 2026] Future Outlook: Physical AI and Autonomous Agents
VLMs are now expanding beyond the digital realm and into the physical world, evolving into AI that can take action.
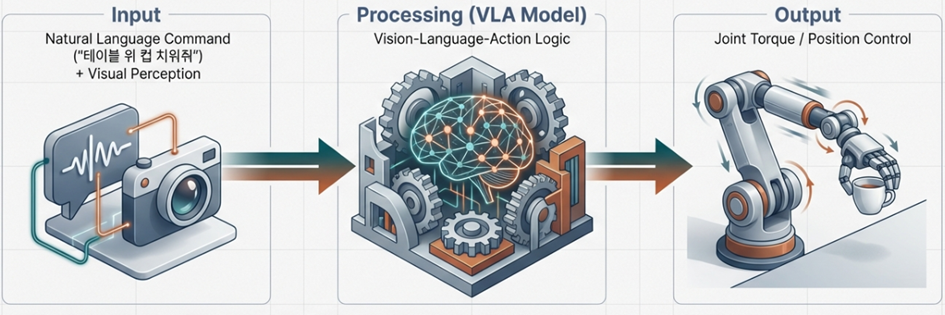
- The Rise of VLA Models: Vision-Language-Action (VLA) models translate visual feedback into robotic control torques in real-time. Models such as NVIDIA’s GR00T and Physical Intelligence’s π₀ are learning the laws of physics by training on trillions of video frames.
- Scaling Laws in Robotics: It is expected that as large-scale models exceeding 100B parameters are introduced to robotics, the “emergent abilities“ previously seen in language models will manifest in the domain of physical control.
Summary of Key Future Trends
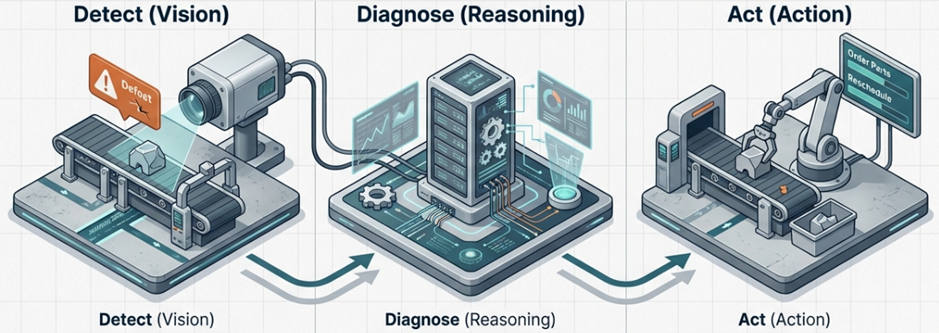
- Agentic AI: Execution of complex, unsupervised workflows and the implementation of self-correcting autonomous factories.
- Physical AI: Achieving human-level robotic dexterity through the seamless integration of vision, language, and action.
- World Models: Simulation capabilities that predict visual causality to prevent accidents before they happen.
- Sovereign AI: Specialized VLMs for medical or legal sectors that comply with local data and security regulations.
Conclusion: VLMs as True Human Companions
Over the past decade, VLMs have evolved from a combination of fragmented technologies into a fully integrated intelligence. Moving beyond the early stages of simply describing images, they now utilize native multimodal designs to merge senses like humans and derive insights from vast contexts.
VLMs are fundamentally changing the way machines understand the world. In the future, they will become true companions to humanity, serving as personal assistants embedded in every device we use and as the brains of robots assisting with physical labor.




