
Solving AI’s “Amnesia”
If you’ve ever used an AI chatbot, you’ve likely experienced it completely forgetting what you said just moments ago. It feels like the AI has “short-term amnesia,” losing the thread of the conversation and giving irrelevant answers. This isn’t because the AI lacks intelligence; it’s due to a structural limitation of the Transformer architecture that has dominated the last decade.
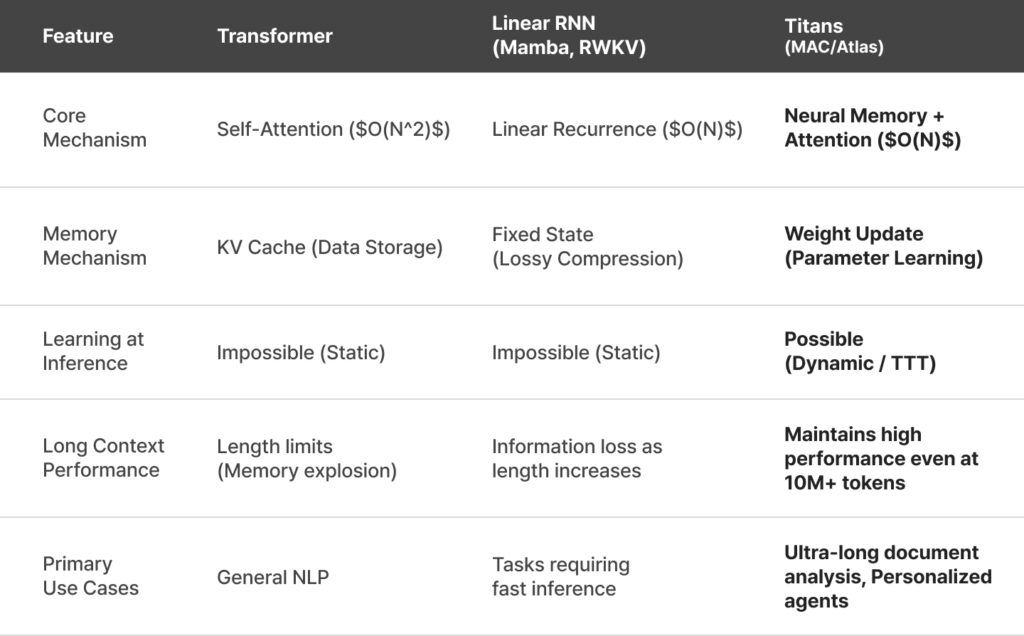
Transformers have a limited context window (the amount of information they can process at once) and operate on a complexity of $O(N^2)$, meaning they ruthlessly discard information once that window is exceeded. This chronic “forgetting” issue has prevented AI from having true, long-term memory.
However, Google’s new AI architecture, ‘Titans’ (Learning to Memorize at Test Time), is a total game-changer. AI has finally overcome its amnesia, gaining “true memory” that allows it to remember every interaction with us indefinitely.
🧠 A Paradigm Shift: Memory is “Optimization,” Not “Storage”
The most innovative aspect of the Titans architecture is how it flips the conventional concept of memory on its head. It is based on a new theoretical framework called MIRAS (Memorization, Information Retrieval, and Associative Systems). MIRAS redefines memory not as “stored data,” but as an “optimization problem.”
“Titans follows the philosophy that ‘Memorization is Learning.”
This strikingly resembles how the human brain works. When we experience something new, our brain doesn’t create a data file in a specific folder; instead, the strength of the connections (synapses) between neurons changes. Titans works similarly. Every time new information enters, the model subtly re-trains its internal neural network in real-time, “embodying” the information itself. In other words, memory is the process of optimizing the neural network’s parameters to best reproduce that information.
While traditional Transformers stack previous conversations in a temporary buffer (KV cache) and dump them when full, Titans dissolves all information into its neural weights, turning it into permanent knowledge. Memory is no longer a stored file; it is the model itself, constantly seeking an optimal state.

Unlike other models that are “frozen” after training, Titans uses Neural Long-term Memory to update its memory even at test-time, making the concept of “optimization-based memory” a reality.
🚀Proving the Impossible: Remembering 10 Million Tokens with 1B Parameters
The emergence of Titans is a fundamental leap in AI memory systems. To categorize existing systems: Transformers use non-parametric memory (perfectly preserved but extremely costly), while RNN-based models like Mamba use lossy memory (compressing info into fixed vectors with data loss). Titans introduces an innovative parametric memory approach, where information is learned directly into the neural network’s parameters.
The magnitude of this achievement is summarized by one experiment. Using an architecture variant called MAC (Memory as Context)—which treats “memory tokens” generated by the memory module as regular text—a small model with fewer than 1 billion (1B) parameters was able to find specific information within a massive 10-million-token dataset (the size of dozens of books) with over 80% accuracy.
This was verified through the grueling “Needle-in-a-Haystack” benchmark. The result was shocking: it proved that “Intelligence (Capacity)” and “Memory” can finally be decoupled.

We are entering an era of “Small but Polymathic AI”—models that are compact in size but can remember every book in the world. Even more impressive is that this runs efficiently on a single consumer-grade GPU like the A100 or H100.
Google researchers didn’t stop at 80% accuracy. To push past the point where parameters become saturated, they developed ‘Atlas’. By mapping memories into a high-dimensional space, Atlas solved parameter interference, achieving “near-lossless” memory even beyond 10 million tokens. If Titans broke the wall, Atlas perfected the craftsmanship.
💡 The Secret of Efficiency: AI Only Remembers the “Surprising”
How does Titans remember 10 million words with such a small model? The secret lies in Selective Memory, focusing on “important and surprising events,” much like humans do.
Titans doesn’t learn everything indiscriminately. Instead, it uses a metric called “Surprise”—based on information theory within the MIRAS framework—to prioritize what to remember. Here, “Surprise” refers to the model’s “prediction error.”
- Expected Info: If a sentence starts with “I am going to…”, the AI can easily predict the word “school.” Since the prediction error is low, it’s deemed “not surprising” and isn’t heavily recorded.
- Surprising Info: If a cat suddenly starts dancing in the middle of a serious legal document, the model’s prediction fails completely. Titans identifies this as “high-information/surprising” and carves it deeply into its Neural Long-term Memory (LMM).
This strategy allows Titans to allocate limited memory resources to the most valuable data, filtering out noise and efficiently storing the core essence of vast amounts of information.
🌊 Real-world Impact: The End of the RAG Era?
Currently, many AI services rely on RAG (Retrieval-Augmented Generation). This involves “searching” for relevant info in an external database and “copy-pasting” it into the prompt. However, this method struggles with search inaccuracies and fails to grasp organic connections between information scattered across different documents.
Titans changes this paradigm. A Titan-based model doesn’t “search” for documents; it reads and learns thousands of papers and books, internalizing the knowledge itself.
A prime example is the integration of Titan/MIRAS into services like Google’s NotebookLM. When a user uploads dozens of research papers, the AI answers like an expert who has completely memorized them. It doesn’t dig through a database; it pulls answers from its internalized memory, showing insights into hidden links between documents and significantly reducing hallucinations. We are moving from an era of “searching” documents for AI to “teaching” documents directly to AI.
📱 AI in Your Hand: The Birth of the Personal Assistant That Knows Everything
The innovation of Titans isn’t confined to massive data centers. The development of ultra-lightweight models (like the Gemini 3 Flash or its counterparts) means this powerful memory is coming to our personal devices.
The biggest advantage of On-device AI is privacy. These models can safely learn and remember highly personal data—like text messages, emails, schedules, and photos—directly on the device without sending it to an external server.
Once commercialized, your AI assistant will never forget a conversation you had yesterday. It will remember your speaking style, habits, important anniversaries, and plans with friends. It will become a “True Personal Assistant” that understands you better the more you use it.
Closing Thoughts
The arrival of Titans is more than just a new model release. It marks the era of “Organic Software”—AI that is no longer a static product, but a growing entity that evolves with every user interaction. The competition in AI performance is moving beyond hardware specs and parameter counts into a new age defined by the efficiency of learning algorithms.



