
Genius AIs with a Case of Amnesia
Did you know that the “genius” AI models writing your poems and code actually suffer from profound amnesia? It’s a strange paradox. No matter how much information they can process at once, that “memory” is volatile—it evaporates the moment the conversation ends. This is the inherent limitation of today’s LLMs.
The answer to this problem didn’t come from pure computer science, but from the human brain. Google’s ‘Titans’ architecture, inspired by cognitive science, has produced shocking results. A tiny Titan model with only 170M parameters managed to outperform GPT-4 (with its trillions of parameters) in the BABILong benchmark, which tests long-term memory reasoning. It was a true “David vs. Goliath” moment. Titans is proposing a fundamental revolution in how AI remembers and learns.
In this post, we’ll dive into the core of this innovation:
- What is Test-Time Training?
- How does it differ from traditional memory?
- The mechanics of Neural Long-term Memory inspired by the brain
- How AI updates its memory through ‘Surprise.’
1. What is Test-Time Training?: The Era of AI That Grows as It Talks
Test-Time Training completely flips the traditional AI development paradigm of “Train → Freeze → Deploy.” Usually, an AI’s intelligence is fixed once it’s deployed. However, with Titans, the model continues to learn and evolve during the “inference (test) phase” as it interacts with the user.
The core philosophy of Titans can be summarized in one sentence: “Memory is a change in parameters, not just data storage.”
- Traditional Models: Like writing notes in a notebook. It’s accurate, but once the notebook is full (Context Window limit), you can’t record anything more.
- Titan Models: Like turning information into “knowledge in the brain.” Since the brain’s synaptic connections (weights) change with each piece of info, it can compress and accumulate knowledge without a strict capacity limit.
2. The Three Ways to Handle Memory: MIRAS Framework
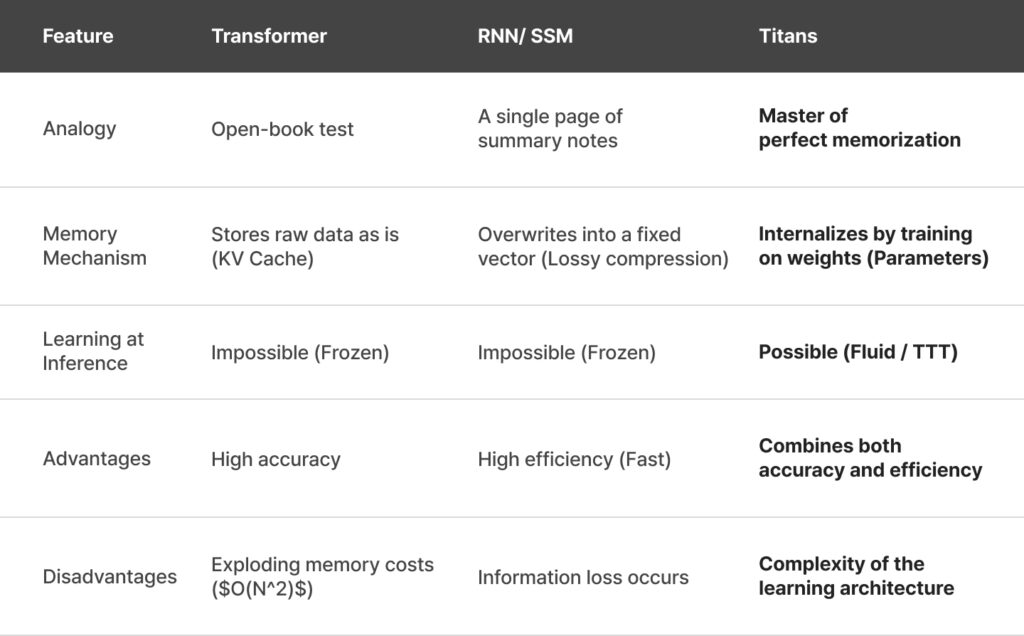
According to Google’s MIRAS (Memorization, Information Retrieval, and Associative Systems) framework, memory isn’t just about storing data; it’s an optimization problem aimed at minimizing loss. Let’s compare three types of models to students preparing for an exam:
- Transformer (“Open-book Test”): Finds answers by flipping through the entire textbook. This “textbook” is the KV Cache. It’s accurate, but as the book gets thicker, the desk gets cluttered (Memory Explosion) and finding answers takes longer. MIRAS calls this Non-parametric Associative Memory.
- RNN/SSM(“One-page Summary”): Constantly overwrites a tiny sticky note to summarize everything. This is a Fixed-size Hidden State. It’s fast and efficient, but older details get blurred and lost. This is Lossy Associative Memory.
- Titan(“The Master of Memorization”): Completely understands and memorizes the textbook. Answers come directly from the learnable parameters of the memory module. It’s accurate, lightweight, and efficient. This is Parametric Associative Memory.
3. The Heart of Titans: Neural Long-term Memory
3.1. Implementation: A Triple-Memory System Inspired by the Human Brain
The core of the Titan architecture lies in three distinct memory modules that mimic the human cognitive process:
- Core (Attention / Working Memory): Focuses immediately on the current task. This functions like our Working Memory, processing the words and sentences we just heard in a conversation.
- Neural Long-term Memory (LMM): Compresses and stores real-time experiences and conversation history directly into its parameters. This is analogous to the Hippocampus, which rapidly encodes new experiences.
- Persistent Memory: Contains pre-trained, static knowledge such as language rules and general common sense. This corresponds to the Semantic Memory stored in the Neocortex.
From an operational standpoint, this sophisticated triple-layered structure can be simplified into a collaborative partnership between a “Brilliant but Static Professor” and an “Evolving Teaching Assistant.”
- The Frozen Main Brain:
- Identity: A combination of the Core and Persistent Memory modules, similar to a standard Transformer model.
- Status: Frozen. The parameters remain unchanged after the initial pre-training.
- Role: Acts as the manager. It understands language, performs reasoning, and most importantly, gives orders to the LMM, saying, “Memorize this!”
- Fluid Memory Module:
- Identity: A small, simple MLP (Multi-Layer Perceptron) neural network that serves as the Neural Long-term Memory (LMM)
- Status: Fluid. Its parameters are updated in real-time even during the inference (testing) phase.
- Role: Acts as a “living memory,” compressing and storing past information within its own synaptic weights.
3.2. Operating Principles and Cognitive Parallels
The system operates in two main stages: ‘Recall’ and ‘Memorize’. When new information arrives, the Main Brain first “reads” past memories stored in the LMM, combining them with the current input to generate a response.
Next comes the ‘Writing’ stage. The Main Brain measures the degree of ‘Surprise’—how unexpected the new information was. If the surprise level is high, the Main Brain instructs the LMM to significantly update its parameters.
This mechanism is strikingly similar to how the human brain works: when we encounter a surprising or shocking event, the brain releases noradrenaline, which “hard-codes” that memory much more vividly into our minds.
4. Continuously updated parameters: Managing Memories Trained at Test-Time
As a result of Test-Time Training, ‘memory parameters’ are no longer static. Instead, they can branch out into various versions depending on the interaction with the user. Titan’s solution to managing this is a ‘Plug & Play’ approach. While the massive “Main Brain” model remains fixed on the server, the small, modular ‘Memory Weights’—categorized by user or topic—can be saved, loaded, and swapped just like files.
This represents a fundamental shift from the conventional RAG (Retrieval-Augmented Generation) approach:
- RAG: Like organizing PDF files into different folders on your hard drive to look up later.
- Titans: Like keeping a drawer full of ‘Topic-specific Brain Segments (Memory Chips)’ that you can snap onto your AI whenever needed.
5. How ‘Surprise’ Creates Memory
The secret lies in the principle of Self-Supervised Learning. In the world of language models, “the next word” acts as the ground truth or the answer key.
Technically, the ‘Surprise Metric’ refers to the Gradient of Loss, which represents the gap between the model’s prediction and the actual input. Parameter updates are split into two scenarios based on the intensity of this “surprise.”
- Case A (common knowledge): The model’s prediction (“I am going to…”) closely matches the actual input (“school”). In this case, the surprise (error) is near zero, so the parameters remain unchanged. This is an efficient memory management strategy: “No need to waste space on what I already know.”
- Case B (New Information): The model encounters something completely unexpected (“I am going to… a cat suddenly dancing”). Since the prediction differs wildly from reality, the surprise (error) spikes, and the parameters undergo a significant update. This implements the principle: “Engrave unknown information deeply into the mind.”
You might worry that useless “gibberish” could enter and pollute the memory. However, Titan has built-in defense mechanisms. If the input doesn’t fit the context, the Main Brain “closes the gate” to block the update. Furthermore, pure noise that lacks a mathematical pattern is naturally difficult for the neural network to learn, meaning it gets filtered out organically.
Despite its brilliance, Titan has its limits. According to the Complementary Learning Systems (CLS) theory in cognitive science, true human learning occurs through the interaction between the hippocampus (responsible for rapid, short-term memory) and the neocortex (which slowly structures knowledge).
In Titan’s current state, only the memory module (hippocampus) changes while the Main Brain (neocortex) remains fixed. This means there may be limitations in achieving true “deep understanding” or “generalization of knowledge”—a fascinating challenge for future research to tackle.
Toward a True ‘Learning Machine’
The paradigm presented by Titan heralds a future where AI is no longer a “static, factory-made product,” but “Organic Software” that grows and evolves alongside the user. Every single conversation subtly reshapes the model’s “brain” structure, giving birth to a true ‘Learning Machine’ that becomes smarter the more you use it.
This technology is already evolving at a rapid pace. Follow-up research, such as ‘Atlas’, has addressed memory saturation through high-dimensional feature mapping. This is more than just a technical fix to expand a context window; it is a revolution that fundamentally changes how AI remembers, learns, and evolves.
We are standing at the threshold of a new era—one where we finally move forward with an AI that has cured its amnesia.



