
Since the publication of the paper “Attention is All You Need” in 2017, the Transformer architecture has reigned as the absolute ruler of the artificial intelligence world. However, this powerful architecture carried an inherent limitation: the “Quadratic Wall,” where computational requirements grow exponentially ($O(L^2)$) as the sequence length increases. The modern AI’s insatiable appetite for long contexts has pushed this architecture to its breaking point.
To tear down this massive wall, an innovative architecture called Mamba (Linear-Time Sequence Modeling with Selective State Spaces) emerged in late 2023. It was introduced through the collaborative research of Albert Gu from Carnegie Mellon University and Tri Dao from Princeton University, who also led the development of Flash-Attention. Mamba presents a new paradigm in AI by reducing computational complexity to linear time ($O(L)$) while maintaining the high performance of Transformers.

In this article, we will explore how Mamba is reshaping the future of AI through four of its most surprising and significant truths.
The First Truth: Mamba’s Real Innovation Lies in ‘Selectivity,’ Not Just ‘Speed’
To view the emergence of Mamba simply as a “faster model” is to miss the core of its brilliance. The true innovation of Mamba lies in Selectivity, implemented through a mechanism called the Selective State Space Model.
Traditional State Space Models (SSMs) were Linear Time-Invariant (LTI) systems, meaning their information processing methods remained fixed regardless of the input data. While this made them computationally efficient, they lacked the ability to discern which information was more important based on the specific context.
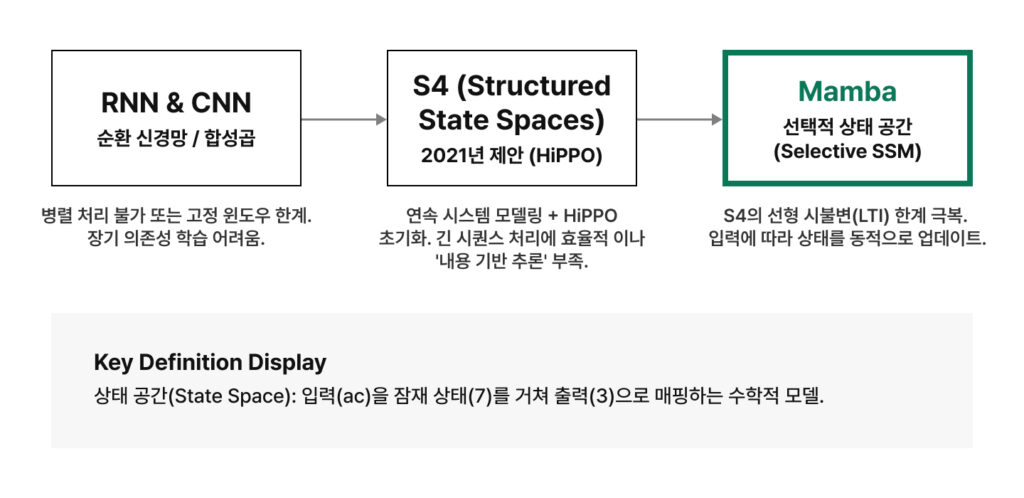
In contrast, Mamba is designed to “select” which information to remember or forget in real-time based on the input data. This is achieved by dynamically changing the core parameters for updating memory ($\mathbf{B, C, \Delta}$) according to the input tokens themselves. In other words, it possesses the ability to understand the flow of context and focus on significant information. Thanks to this selectivity, Mamba has secured complex reasoning capabilities on par with Transformers.
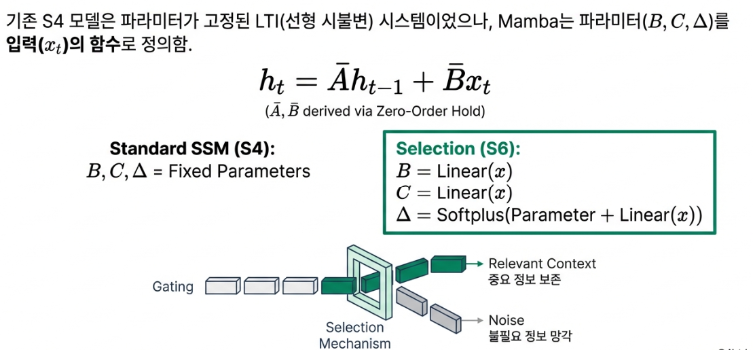
While Transformer’s attention mechanism looks at (and remembers) the relationships between all parts of the input data—causing computational costs to increase quadratically—Mamba is highly efficient because it discards parts deemed unimportant. However, it is also true that this makes Mamba slightly less capable than Transformers at recalling every minute detail with the same level of precision.
The Second Truth: The End of the Memory-Hogging ‘KV Cache’
The biggest headache for Transformer models during text generation (inference) has been the KV Cache. To predict the next word, the model must store information from all previous words in the form of Keys and Values. As the context grows longer, this cache consumes GPU memory exponentially, creating a massive bottleneck.
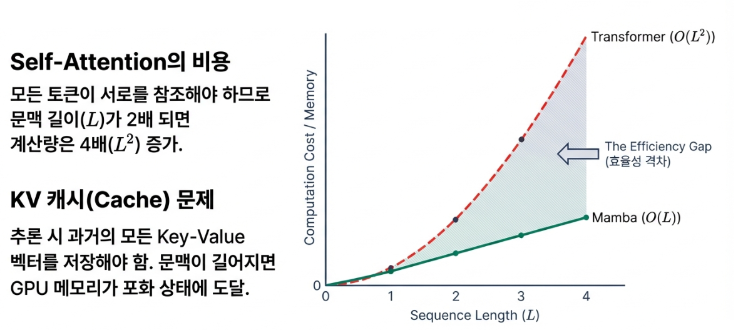
Mamba fundamentally resolves this issue. Instead of storing every single piece of past information individually, it compresses and stores essential data into a single, fixed-size State Vector. Consequently, the amount of memory Mamba uses remains nearly constant, no matter how long the context becomes.
The advantages of this difference are immense. The same hardware can handle significantly more concurrent users, and inference throughput can increase by up to five times. This directly translates into a strategic advantage by dramatically lowering the operational costs of AI services, while also opening the possibility of running powerful large-scale models on low-spec devices like smartphones or laptops.
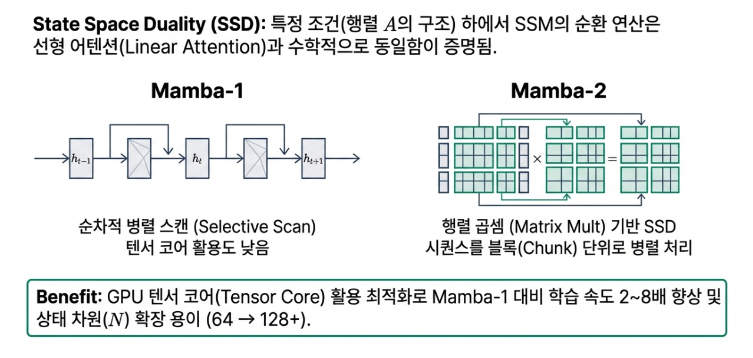
The Third Truth: The Most Surprising Twist—Mamba and Attention Share the Same Principle
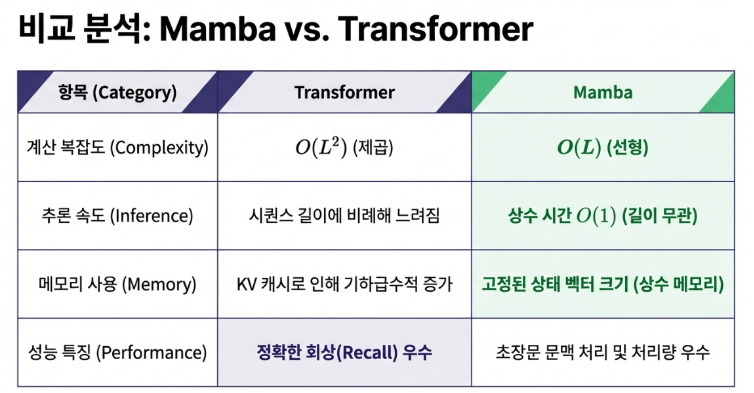
For a long time, Mamba and Transformers were viewed as rivals with different philosophies. However, the Mamba-2 research released in 2024 (Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality) completely overturned this conventional wisdom. Through the remarkable concept of State Space Duality (SSD), it proved that both architectures are based on the same mathematical principles.
This means that Mamba’s recurrent state update method and the Transformer’s attention mechanism are essentially solving the same computation in different ways. It is like traveling to the same destination where one person takes a circular route and the other takes a straight road connecting every point directly.
Essentially, Transformers and Mamba are not entirely different architectures; rather, they both compute the same linear transformation—one through direct interaction between positions (Attention) and the other through recursive state updates (SSM). This discovery has laid the theoretical foundation for hybrid models that combine the strengths of both architectures and is suggesting new directions for AI hardware design.
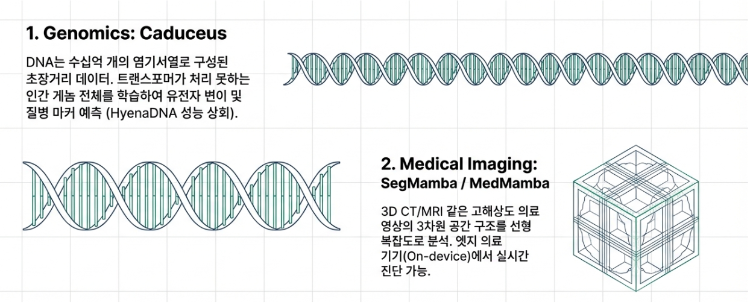
The Fourth Truth: Beyond Language to Genomics and Medical Imaging: Mamba’s New Horizons
Mamba’s linear scaling ($O(L)$) characteristic does more than just improve the efficiency of language models. It is sparking a true revolution in fields involving “ultra-long sequence data” that traditional Transformers could not handle due to memory constraints.
- Genomics: Mamba-based models like Caduceus treat the entire 3-billion base pair human genome as one continuous book rather than fragmented pieces. This allows for the discovery of subtle, long-range genetic narratives that were previously computationally impossible.
- Medical Image Analysis: Mamba efficiently processes massive 3D datasets such as CT or MRI scans consisting of hundreds of slices, performing precise organ segmentation and diagnosis. This opens the possibility for real-time diagnostic support tools on local hospital hardware.
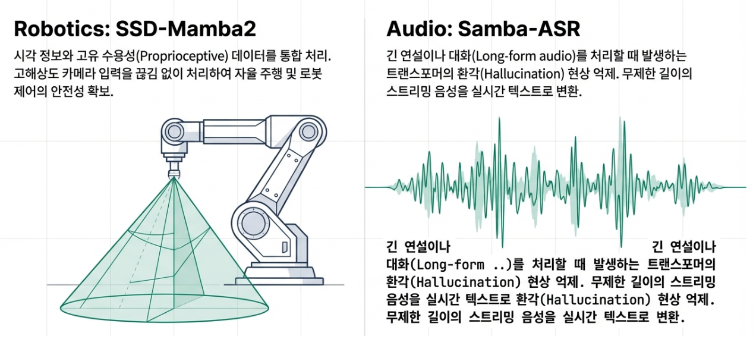
- Audio Processing: The Samba-ASR model converts extremely long speeches or meeting transcripts into text in real-time with fewer errors, significantly improving upon the latency and hallucination issues of conventional models.
Conclusion: From Quadratic to Linear—A New Paradigm for AI
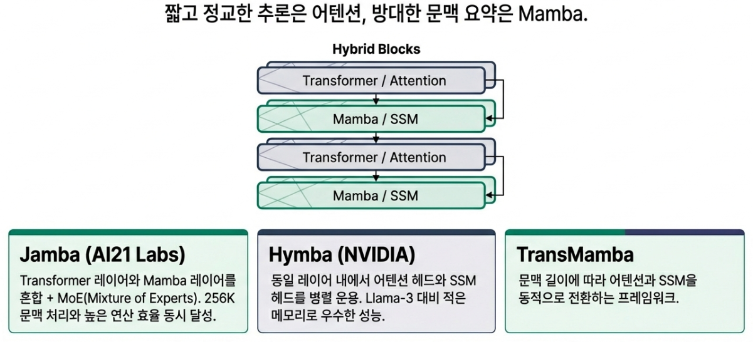
Mamba is not merely a replacement for the Transformer. It is the most compelling evidence that the paradigm of AI architecture is shifting from inefficient quadratic complexity to efficient linear complexity. While Mamba is not perfect in every aspect—Transformers still hold an edge in precisely pinpointing specific, minute details—the future likely belongs to hybrid models like Jamba or Hymba that combine Mamba’s efficiency with the Transformer’s sophistication.

Furthermore, in an era where the massive power consumption of large-scale models has become a social concern, Mamba’s efficiency carries significant weight. With its overwhelming energy efficiency during the inference stage, Mamba is gaining attention as a core technology for “Green AI.” This is more than just a technical victory; it is a vital step toward sustainable AI.

As AI moves beyond massive data centers and into the devices in our hands, will Mamba’s radical efficiency become the new standard for “smart”? The great shift in the AI paradigm has already begun.



