
AI 기술 도입과 연구를 계획하는 이들에게 최근 메모리 및 저장장치의 가격 급등은 적지 않은 충격으로 다가오고 있습니다. 더욱이 고성능 GPU의 수급난까지 겹치며 AI 하드웨어 인프라 구축의 문턱은 나날이 높아지는 있죠. 이러한 ‘하드웨어 보릿고개’ 속에서, 과연 우리는 어떠한 전략적 선택을 통해 비용 대비 효율을 극대화해야 할까요? 단순히 “가장 비싼 GPU”를 구매하는 것이 정답이던 시대는 지난 것 같습니다. 이제는 구동하려는 모델의 파라미터 크기, 메모리 대역폭, 전력 효율(TCO), 그리고 다중 사용자 처리를 위한 배치(Batch) 성능까지 종합적으로 고려해야 합니다.
최근 공개된 벤치마크 데이터와 스펙을 바탕으로, 현재 시장에서 주목받는 4가지 선택지(NVIDIA DGX Spark, RTX Pro 6000, RTX 5090, Mac Mini M4 Pro)를 실제 LLM 밴치마크를 기반으로 비교 분석해보겠습니다.
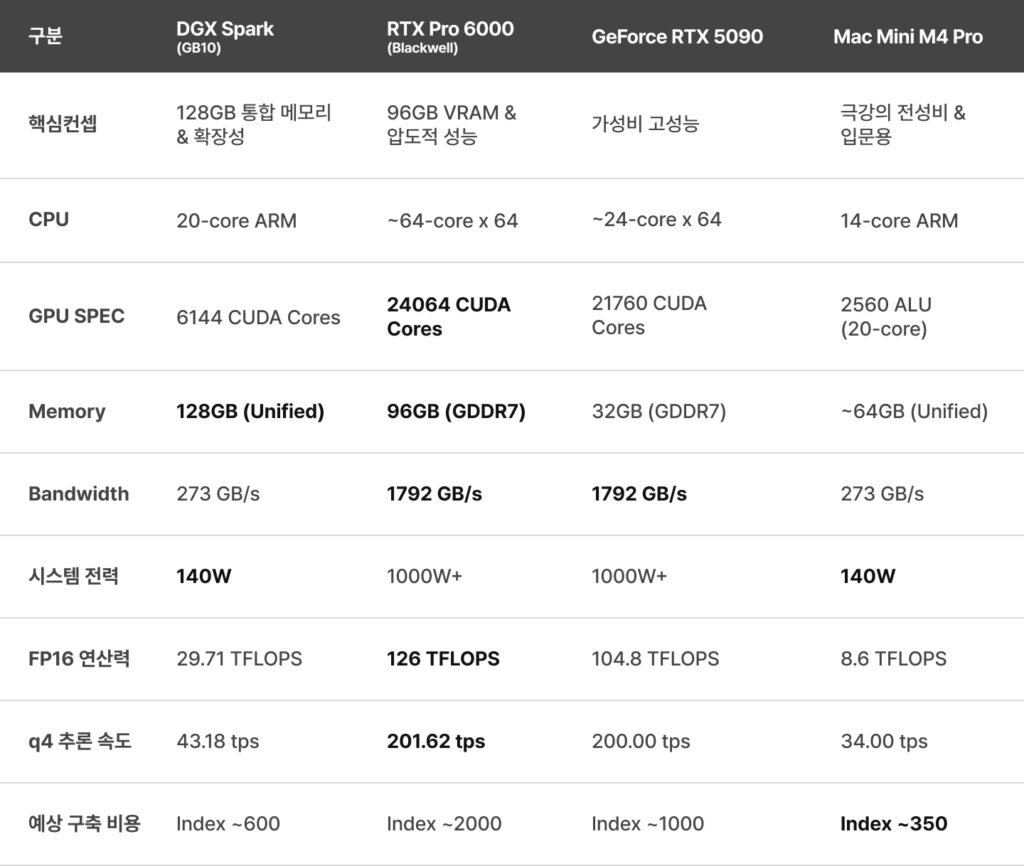
각 기기 스펙 및 성능 요약

확보된 비교 데이터를 통해 각 시스템의 체급과 성격을 한눈에 확인해 보겠습니다.
1. NVIDIA DGX Spark (GB10): “소규모 검증을 위한 책상 위의 AI 연구소”
⭕ 장점: 메모리 용량과 배치 효율성 128GB 통합
- 128GB 통합 메모리: 70B, 100B 이상의 거대 모델을 양자화 없이 로컬 환경에 올릴 수 있는 유일한 소형 폼팩터로 RTX 5090(32GB)의 4배에 달하는 메모리를 제공함.
- 140W의 저전력: 전력 소모가 적어 24시간 가동되는 개인용 서버로 최적
- X2확장 가능: 2대를 구비하여 커넥터를 통하여 최대 2배의 처리 속도와 메모리 확보 가능
❌ 단점: 단일 작업 속도
- 대역폭 한계: 273 GB/s의 대역폭으로 인해, 단일 사용자의 쿼리 응답 속도(Latency)는 RTX 시리즈 대비 많이 느린 편
- ARM아키텍쳐: 최신 모델을 원없이 돌리고 싶다면, ARM아키텍쳐로 인하여 aarch호환 라이브러리를 처리하는 작업에 추가로 시간이 소요됨.
2. RTX Pro 6000 Workstation: “엔터프라이즈급 모델 처리 능력”
⭕ 장점: 타협 없는 성능
- 96GB GDDR7 VRAM: DGX Spark의 용량에 근접하면서도 속도는 RTX 5090급을 유지함. 1792 GB/s의 광대역폭은 거대 모델도 순식간에 처리해냄.
- 4000 TOPS급 AI 연산: 상업용 서비스 백엔드에 적합한 강력한 연산 능력을 보유함.
❌ 단점: 비용과 인프라
- 높은 비용과 전력: 초기 구축 비용이 가장 높으며, 1000W급 전력 공급과 별도의 쿨링 설비가 요구됨.
3. GeForce RTX 5090 PC: “빠른 검증, 개인용 고속 추론”
⭕ 장점: 최고의 반응 속도(Latency)
- 압도적 속도: q4 양자화 기준 200 tps를 기록하며, 가격 대비 개인 사용자가 체감하는 반응 속도가 가장 빠름.
- 접근성: 부품 수급이 비교적 용이하고, 게이밍 등 다용도 활용이 가능함.
❌ 단점: 32GB의 벽
- 모델 크기 제한: 32GB VRAM은 70B 모델 구동 시 4bit 양자화가 필수적이며, 배치 처리를 위한 메모리 여유 공간(Headroom)이 부족함.
4. Mac Mini M4 Pro: “가장 효율적인 입문기, 단 유명한 모델 PoC만 가능”
⭕ 장점: 가성비와 접근성
- Index ~350의 경제성: DGX Spark의 절반 수준 비용으로 64GB 통합 메모리 환경을 경험할 수 있음.
- 준수한 성능: 273 GB/s 대역폭과 140W 저전력으로, q4 기준 34 tps의 실사용 가능한 속도 구현, 입문자나 PoC용으로 최적
❌ 단점: CUDA 부재와 확장성
- 소프트웨어 호환성: NVIDIA의 CUDA 생태계를 100% 활용하기 어려워 다수의 AI 라이브러리 호환성 이슈 발생 가능
🚀심층 분석: 서비스 확장을 위한 ‘배치(Batch) 처리’ 성능
단순히 “내가 쓸 때 얼마나 빠른가(Latency)”를 넘어, “동시에 몇 명의 사용자에게 답할 수 있는가(Throughput)”를 고려한다면 선택의 기준은 완전히 달라지게 됩니다.
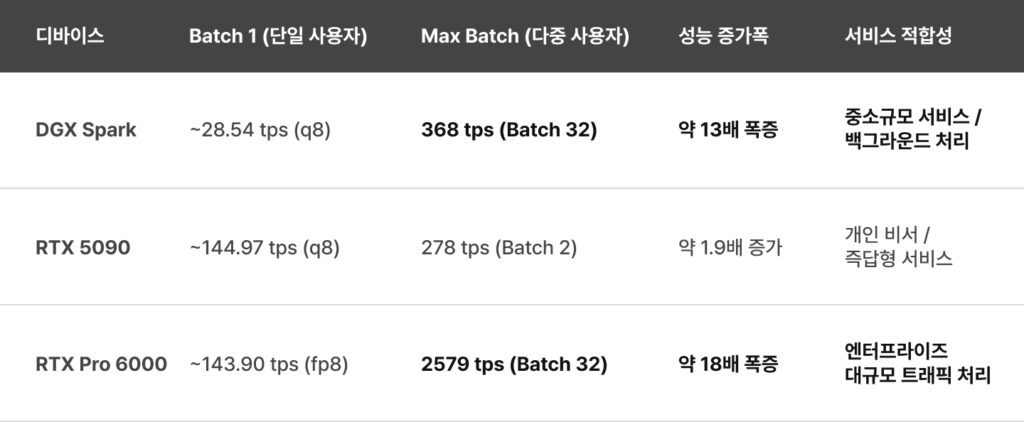
💡 분석 인사이트
- DGX Spark의 반전
단일 사용자 속도는 28 tps로 느린 편이나, 배치를 늘렸을 때 처리량은 368 tps까지 올라갑니다. 이는 다수의 사용자가 동시에 접속하거나, 대량의 데이터를 병렬로 처리(Batch Job)해야 하는 서버 용도로 RTX 5090보다 더 효율적일 수 있음을 시사합니다. - RTX Pro 6000의 위엄
배치 32에서 초당 2579 토큰이라는 경이적인 처리량을 보여줍니다. 이는 수십 명의 사용자가 동시에 질문해도 지연(Latency) 없이 답변을 생성해낼 수 있는 수준으로, 상용 서비스에는 필수적인 장비라 할 수 있습니다. - RTX 5090의 한계
배치 2에서 278 tps를 기록했지만, VRAM 용량 부족으로 인해 배치 사이즈를 크게 늘리기 어렵습니다. (배치를 늘리려면 KV Cache를 위한 막대한 VRAM이 추가로 필요하기 때문). 따라서 1~2인용 고성능 비서 또는 소규모 작업 역할에 국한됩니다.
🎯 결론: 최적의 선택은 무엇인가?
“예산은 제한적이나 64GB 이상의 메모리가 필수적이다, 모델은 유명한 모델을 돌리기만 하면 된다 ”
👉 Mac Mini M4 Pro (가성비 입문)
“예산은 제한적이나 무조건 큰 모델을 돌려야 하거나 테스트 하여야 한다. 100GB 이상의 GPU 메모리가 필수적이다” “24시간 서버를 저전력으로 운영하며 다중 접속 처리가 필요하다”
👉 DGX Spark (고효율 서버)
“단일 사용자로서 무조건 빠른 응답 속도가 중요하다”
👉 RTX 5090 (개인용 하이엔드)
“준상용 서비스를 위한 대규모 트래픽 처리가 요구된다”
👉 RTX Pro 6000 (엔터프라이즈)
목표가 ‘빠른 모델 테스트 및 PoC (Latency)’인지, ‘다수를 위한 서비스(Throughput)’인지에 따라 최적의 장비를 선택하기를 제안합니다.




댓글
운영 정책에 반하는 글은 사전 고지 없이 삭제될 수 있습니다.