
텍스트를 넘어 시각의 시대로 (LMM의 등장 배경)
인공지능 연구의 패러다임이 대규모 언어 모델(LLM)의 성공을 넘어, 시각 정보를 통합적으로 처리하는 멀티모달 대규모 모델(LMM, Large Multimodal Models)로 빠르게 이동하고 있습니다. 초기 멀티모달 연구가 단순히 이미지 캡셔닝이나 단답형 질의응답(VQA)에 국한되었다면, 이제는 복잡한 인간의 지시어를 시각적 맥락 속에서 파악하고 논리적으로 추론하는 능력이 핵심이 되었습니다.
이러한 흐름 속에서 등장한 LLaVA(Large Language-and-Vision Assistant)는 독점적인 거대 모델에 대항하여 오픈 소스 생태계를 선도하는 상징적인 모델입니다. LLaVA는 단순한 이미지 설명 도구가 아닌, 인간의 의도를 시각적 맥락에서 파악하는 ‘범용 시각 보조 모델’의 기틀을 마련했으며, 투명한 데이터와 가중치 공개를 통해 기술 민주화를 이끌고 있습니다.
LLaVA의 뼈대: 미니멀리즘 아키텍처 이해하기
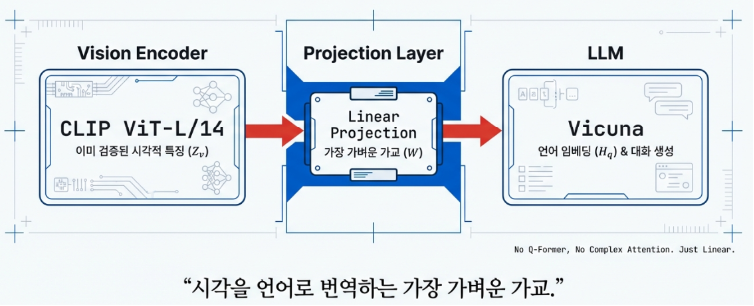
LLaVA의 설계 철학은 복잡한 시스템을 구축하기보다 ‘구조적 단순함’과 ‘결합의 효율성’에 집중하는 데 있습니다. 이를 위해 서로 다른 역할을 수행하는 세 가지 핵심 요소를 유기적으로 연결하여, 가볍고도 강력한 멀티모달 성능을 구현했습니다.
가장 먼저 이미지를 받아들이는 시각 인코더(Vision Encoder)로는 OpenAI의 CLIP(ViT-L/14) 모델을 채택했습니다. CLIP은 이미 방대한 이미지-텍스트 쌍을 학습하여 시각적 개념을 언어적 표현으로 연결하는 능력이 매우 뛰어난데, LLaVA는 특히 마지막 레이어의 그리드 특징(Grid Features)을 활용해 이미지 내 객체들의 공간적 구조를 정교하게 보존합니다.
이렇게 추출된 시각 정보는 투사 레이어(Projection Layer)라는 가교를 거치게 됩니다. 이 레이어의 역할은 시각 특징 벡터를 언어 모델이 이해할 수 있는 임베딩 공간으로 매핑하는 것입니다. 초기 모델에서는 단순한 선형 행렬(Linear Layer)을 사용했으나, 모델이 진화함에 따라 현재는 시각 정보와 언어 정보 사이의 복잡한 비선형 관계를 더욱 잘 포착할 수 있는 MLP(Multi-Layer Perceptron) 구조로 발전했습니다.
마지막으로 시스템의 두뇌 역할을 담당하는 언어 모델(LLM)은 Meta의 LLaMA를 기반으로 대화 성능을 최적화한 Vicuna 모델이 맡습니다. 투사 레이어를 통과한 ‘시각 토큰’과 사용자의 ‘텍스트 지시어’를 동시에 입력받은 LLM은, 이를 하나의 문맥으로 파악하여 자동회귀(Auto-regressive) 방식으로 가장 자연스럽고 정확한 응답을 생성해냅니다.
“LLaVA의 설계 철학은 미니멀리즘과 효율성에 기반합니다. 복잡한 설계 대신 ‘얕고 간결한 정렬(Shallow Alignment, 깊고 복잡한 통합 대신 최소한의 연결만으로 시각과 언어를 매핑한다는 의미)’을 통해 시각과 언어를 연결한 것은, 새로운 SOTA 언어 모델이 등장할 때마다 이를 즉각적으로 이식할 수 있는 강력한 유연성을 제공합니다.”
이는 초창기 OpenAI에서 CLIP 모델이 발표될 때에 비해, 이미 언어 모델 성능이 크게 향상되었기 때문에, 언어와 비전을 통합하여 대조학습을 통해 정렬시키는 대신에, 이미 잘 학습된 언어 모델에 비전 모델을 투사 레이어를 통해 연결시키는 비교적 쉬운 방법으로 학습이 가능하며, 좋은 모델이 나올 때마다 교환할 수 있는 유연함과 편리함을 얻을 수 있다는 의미입니다.
이러한 전략은 컴퓨팅 자원 효율성에서도 빛을 발합니다. LLaVA는 CC3M(Conceptual Captions 3M) 데이터셋 에서 필터링된 약 595K개의 이미지-텍스트 쌍을 사용하는 1단계 사전 학습을 8장의 A100 GPU로 6시간 이내에 완료할 수 있습니다. 이는 CogVLM과 같이 모델 내부에 별도의 ‘시각 전문가’ 모듈을 삽입하는 ‘깊은 융합(Deep Fusion)’ 방식과 비교했을 때, 구현 비용이 낮으면서도 반복적인 기술 개선 속도가 월등히 빠르다는 전략적 우위를 점하게 합니다.
참고로, CC3M이란 구글(Google)에서 공개한 ‘Conceptual Captions’ 데이터셋의 약자로, 웹상에서 수집한 약 300만 개(3M)의 이미지와 그에 대응하는 설명(Caption)으로 구성된 방대한 데이터 묶음을 말합니다. 단순히 양만 많은 것이 아니라, 이미지 내의 구체적인 고유 명사를 일반적인 개념(Conceptual)으로 변환하여 AI가 사물의 본질적인 특징을 더 잘 학습하도록 설계된 것이 특징입니다. LLaVA는 이 방대한 데이터 중 품질이 좋은 약 60만 개를 선별해 사용함으로써, 시각적 특징과 언어적 개념을 연결하는 ‘정렬(Alignment)’ 과정을 매우 빠르고 효율적으로 수행해 냅니다.
성능의 비밀: 시각적 지시어 튜닝과 데이터 생성
최근 멀티모달 모델의 발전 과정을 지켜보면, 모델의 성능을 결정짓는 본질은 화려한 아키텍처보다 결국 ‘데이터의 품질’에 있다는 점을 실감하게 됩니다. LLaVA 연구진 역시 이 지점에 주목했습니다. 이들은 AI의 시각적 지능을 한 단계 끌어올리기 위해, 텍스트 전용 모델인 GPT-4로부터 지식을 추출하는 ‘지식 증류(Knowledge Distillation)’ 기법을 활용하여 158K개의 고품질 시각적 지시어 튜닝 데이터를 구축했습니다.

흥미로운 점은 데이터 생성 당시(2023년) GPT-4가 이미지를 직접 볼 수 없는 텍스트 전용 모델이었다는 사실입니다. 연구진은 이미지 파일 대신, 이미지의 캡션과 객체 위치 정보(Bounding Boxes)를 텍스트로 가공해 GPT-4에게 전달했습니다. 그러자 GPT-4는 마치 머릿속으로 이미지를 그려내듯, 주어진 텍스트 메타데이터를 바탕으로 매우 정교하고 논리적인 질문과 답변을 생성해냈습니다.
이러한 방식은 기술적으로나 비용적으로 매우 영리한 선택이었습니다. 고해상도 이미지를 AI에게 직접 입력해 데이터를 생성하는 과정은 비용이 많이 들고 속도도 느립니다.
반면 LLaVA는 기존 COCO 데이터셋 등의 메타데이터를 활용해 “이 사진에는 [사람, 자전거]가 이런 좌표에 위치해 있어. 이 정보를 바탕으로 사진을 보고 나누는 대화를 생성해 줘”라는 식의 프롬프트를 던지는 방식을 취했습니다. 이미지 토큰을 직접 처리하지 않으므로 API 비용을 획기적으로 낮추면서도 처리 속도를 비약적으로 높인 것이죠.
이렇게 탄생한 158K개의 데이터셋은 단순히 눈앞의 사물을 묘사하는 수준을 넘어, 모델에게 다음 세 가지 핵심 역량을 학습시킵니다.
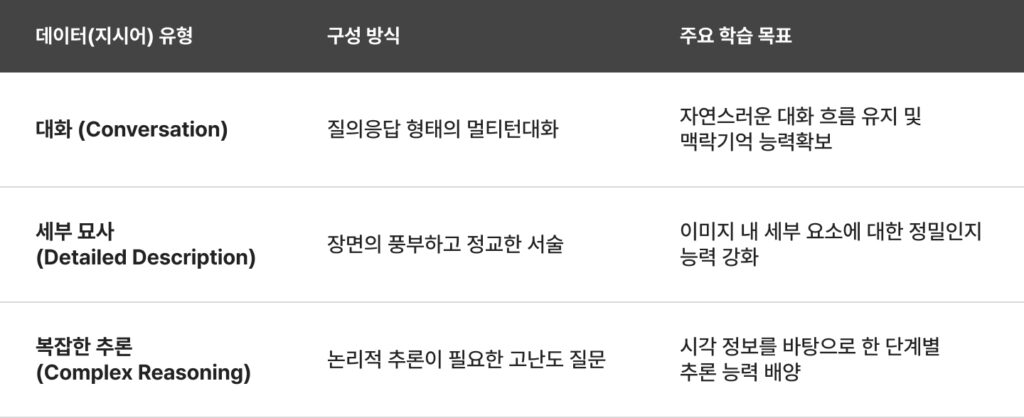
물론 한계도 존재합니다. 텍스트 메타데이터에 포함되지 않은 미세한 색상이나 질감 등에 대해서는 GPT-4가 ‘상상력’을 발휘하다 보니, 실제 이미지와 다른 답변을 내놓는 환각(Hallucination) 현상이 발생할 수 있습니다. 하지만 이러한 한계에도 불구하고, 고품질 데이터를 효율적으로 대량 생성하여 모델의 ‘두뇌’를 깨웠다는 점은 LLaVA가 거둔 가장 큰 성과 중 하나입니다.
이후 GPT-4V API가 공개되면서(2024년) VLM의 학습 방법론은 또 한 번의 획기적인 전환점을 맞이합니다. 바로 ‘Teacher-Student 증류(Distillation)’ 방식의 등장입니다. 이 방식은 LLaVA-NeXT를 비롯해 Qwen-VL-Plus 등 최신 고성능 VLM들의 실질적인 표준(De facto Standard)으로 빠르게 자리 잡았습니다.
앞서 언급한 초기 방식(LLaVA)이 텍스트 메타데이터에 의존했다면, 이 전략은 GPT-4o나 Gemini 1.5 Pro와 같이 시각 지능이 정점에 도달한 최상위 상용 모델(Teacher)을 직접 활용합니다. 우리가 구현하고자 하는 로컬 모델(Student)을 위해, 선생 격인 모델이 고품질의 학습 데이터를 ‘찍어내듯’ 생성해주는 것이 핵심입니다.
작동 원리는 매우 직관적입니다. 먼저 기업이나 연구실에서 실제 해결하고자 하는 도메인의 원본 이미지(예: CCTV 프레임, 공장 설비 사진, 의료 영상 등)를 준비합니다. 그 다음, 이미지 이해도가 뛰어난 Teacher 모델에게 이 이미지를 직접 입력하며 정교한 미션을 부여합니다. 예를 들어 “이 이미지의 모든 디테일을 아주 상세하게 묘사해줘”라고 요청하거나, 산업 현장에 맞춰 “이 상황에서 발생할 수 있는 안전 문제에 대한 Q&A를 5개 생성해줘”와 같은 구체적인 지시를 내리는 식입니다.
이렇게 생성된 [이미지-고품질 텍스트] 쌍은 그대로 로컬 VLM의 강력한 학습 자료가 됩니다. 이 방식이 가진 가장 큰 매력은 바로 ‘데이터의 밀도(Density)’에 있습니다.
실제로 ShareGPT4V 연구 결과에 따르면, 단순히 “남자가 자전거를 타고 있다”와 같은 파편화된 짧은 캡션 10만 개를 학습시키는 것보다, 이미지 하나하나의 맥락을 집요하게 파고드는 상세한 긴 캡션(Dense Caption) 1만 개를 학습시키는 것이 모델의 성능 향상에 훨씬 효과적이었습니다. 결국 VLM 학습의 성패를 가르는 것은 데이터의 단순한 ‘양’이 아니라, 그 안에 담긴 정보의 ‘밀도’라는 점을 명확히 보여주는 사례라고 할 수 있습니다.
2단계 학습 프로토콜: 효율적인 학습 전략
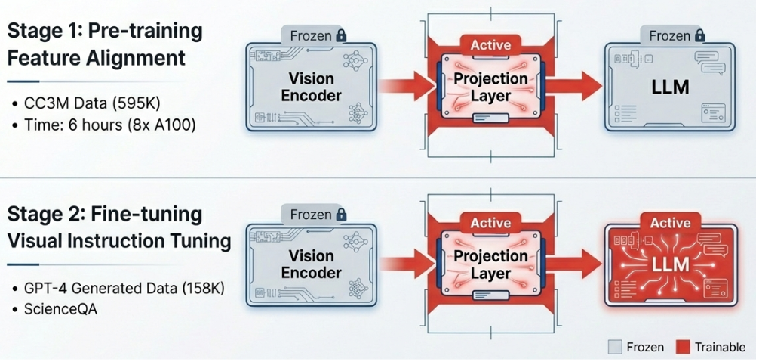
LLaVA는 자원을 효율적으로 사용하면서 모델을 안정적으로 수렴시키기 위해 전략적인 2단계 학습을 채택합니다.
- 1단계 (사전 학습 – Feature Alignment): 시각 인코더와 언어 모델을 고정한 채 오직 투사 레이어만 학습시킵니다. CC3M 데이터셋(595K 쌍)을 사용하여 모달리티 간 정렬을 수행하며, 이는 8장의 A100 GPU로 단 6시간 만에 완료될 정도로 매우 효율적입니다.
- 2단계 (미세 조정 – End-to-End Fine-tuning): 시각 인코더는 고정하되 투사 레이어와 언어 모델 전체의 가중치를 업데이트합니다. 158K개의 지시어 데이터를 통해 실제 사용자의 복잡한 요구사항을 처리하는 전문적인 과업 수행 능력을 확보합니다.
효율성과 성능 표준의 정립: LLaVA-1.5
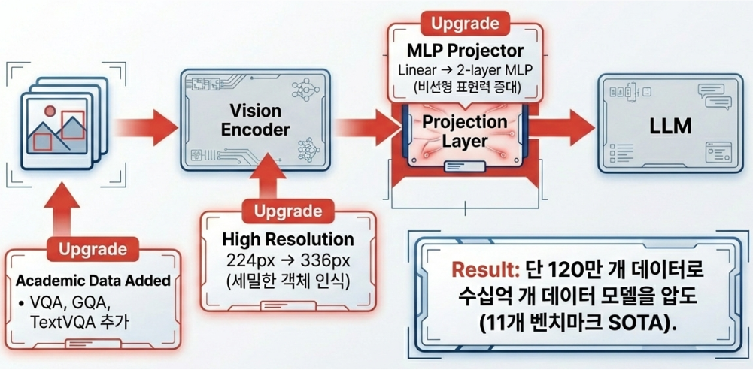
LLaVA-1.5(2023년)는 단순한 업그레이드를 넘어 오픈소스 멀티모달 모델의 실질적인 표준을 제시했습니다. 핵심은 구조적 개선과 데이터의 질적 향상에 있습니다. 기존의 단순 선형 레이어를 비선형 MLP 커넥터로 교체하고 이미지 해상도를 336px로 높여 시각적 이해도를 정교화했습니다.
특히 학술적 VQA 데이터와 공유 데이터셋(ShareGPT4V) 등 고품질 데이터를 전략적으로 믹스하여 학습 효율을 극대화했습니다. 그 결과, 수천억 개의 파라미터를 가진 거대 상용 모델들과 비교해도 손색없는 성능을 단 13B 규모의 모델로 증명해내며 자원 효율성의 정점을 보여주었습니다.
한계를 넘어선 진화: LLaVA-Next(v1.6)
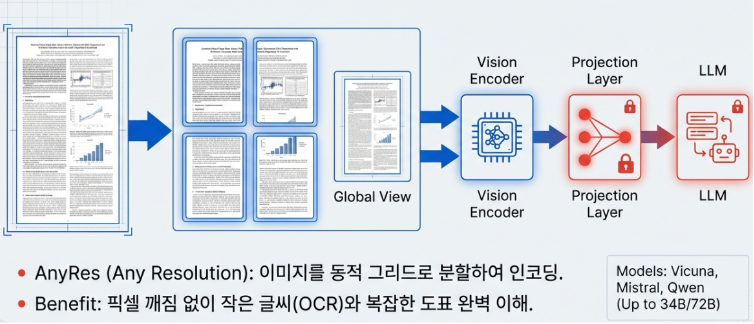
LLaVA-NeXT(v1.6, 2024년)는 기존의 한계를 넘어 상용 모델인 Gemini Pro와 견줄 만큼 강력한 진화를 이뤄냈습니다. 가장 큰 혁신은 ‘AnyRes’ 알고리즘의 도입입니다. 이 기술은 고해상도 이미지를 고정된 크기가 아닌 {2×2, 1×2, 2×1, 1×3, 3×1, 1×4, 4×1} 등 동적 그리드로 유연하게 분할하여 처리합니다. 전체 구도를 파악하는 글로벌 뷰와 세부 패치를 분석하는 로컬 뷰를 결합함으로써, 작은 텍스트를 읽어내는 OCR 능력과 복잡한 도표 분석 성능을 비약적으로 끌어올렸습니다.
또한 LLaVA-NeXT는 Mistral-7B, Llama-3(8B), 그리고 대규모 모델인 Qwen-1.5(72B/110B) 등 최신 언어 모델을 백본으로 채택하며 성능의 폭을 넓혔습니다. 특히 Qwen 기반 모델은 강력한 중국어 제로샷 능력을 보여주며 글로벌 범용성까지 확보했습니다. 이러한 구조적 유연성 덕분에 이미지뿐만 아니라 비디오 이해 능력까지 확장되어, 영상의 흐름을 논리적으로 파악하는 제로샷(Zero-shot) 역량까지 갖추게 되었습니다. LLaVA-NeXT는 이처럼 강력한 백본과 혁신적인 시각 분석 기술을 결합하여 오픈소스 VLM의 정점을 보여줍니다.
시각을 넘어 시간의 맥락으로: LLaVA-Video
LLaVA-Video(2024년)는 이미지 중심의 멀티모달 모델을 넘어, 시간의 흐름을 파악해야 하는 비디오 도메인에서도 혁신적인 성능을 보여줍니다. 이 모델의 핵심은 AnyRes 기술을 비디오 프레임 단위로 확장한 ‘AnyRes-Video’ 전략에 있습니다. 고해상도 영상을 단순히 줄이는 것이 아니라, 프레임을 동적으로 분할하여 세부 패치를 분석함으로써 영상 속 아주 작은 움직임이나 텍스트까지 정교하게 포착해냅니다.
기술적으로 가장 흥미로운 점은 이미지 데이터로만 학습된 모델이 비디오 작업을 즉시 수행하는 ‘제로샷 전이 능력’입니다. LLaVA-Video는 여기에 더해 약 178K개의 고품질 비디오 지시어 튜닝 데이터를 결합하여, 단순한 장면 묘사를 넘어 영상의 전체 맥락을 추론하고 복잡한 질문에 답하는 능력을 갖췄습니다. 또한 선형 스케일링 기법을 통해 LLM의 최대 토큰 길이를 극복함으로써, 장시간의 영상도 끊김 없이 이해할 수 있는 길이 일반화(Length Generalization) 능력을 보여줍니다. 결과적으로 오픈소스 모델임에도 불구하고 비디오 벤치마크에서 상용 모델인 Gemini Pro를 상회하는 결과를 기록하며 영상 이해 모델의 새로운 기준을 세웠습니다.
멀티모달의 완전체: LLaVA-OneVision
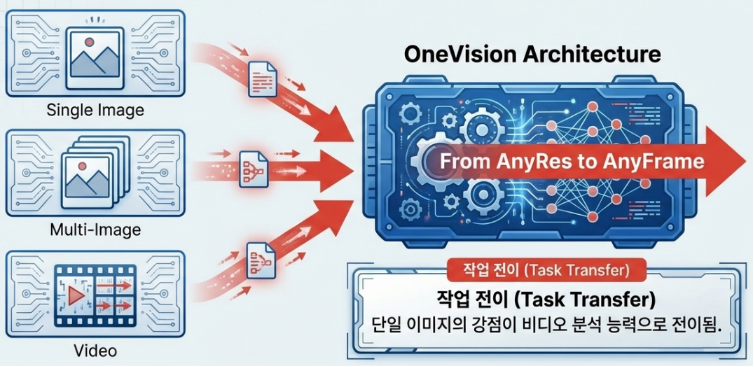
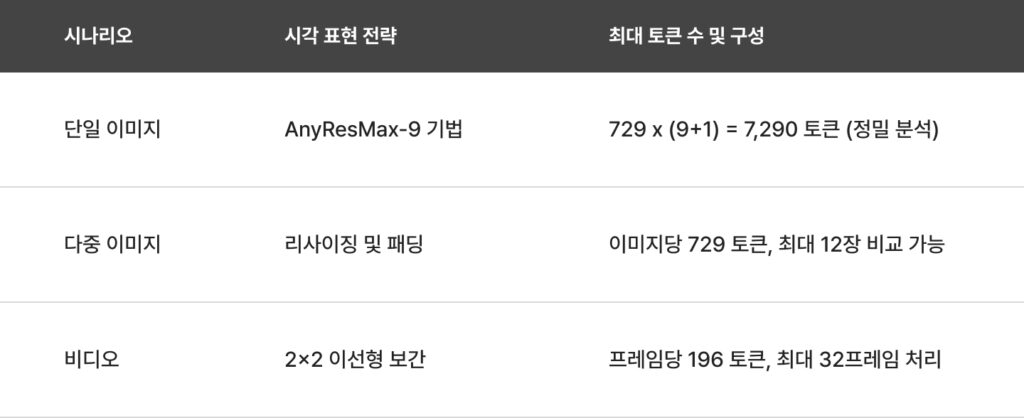
LLaVA-OneVision(2024년)은 단일 이미지, 다중 이미지(Multi-image), 그리고 비디오라는 세 가지 핵심 시나리오를 하나의 모델로 통합하며 오픈소스 멀티모달 모델(LMM)의 새로운 지평을 열었습니다. 이 모델의 가장 큰 혁신은 ‘AnyRes-Max’ 전략을 통해 고해상도 이미지 처리 능력을 극대화한 것과, 이미지에서 학습된 지능을 비디오와 다중 이미지 시나리오로 자연스럽게 전이시키는 Task Transfer 능력에 있습니다.
기술적으로는 SigLIP 시각 인코더와 Qwen2 언어 백본을 결합하여 강력한 기초 체력을 확보했습니다. 특히 동적 그리드 구성을 더욱 정교화하여 복잡한 차트 분석이나 여러 장의 이미지를 동시에 비교하는 추론 능력에서 상용 모델인 GPT-4o와 Gemini Pro 1.5에 필적하는 성능을 보여줍니다. 또한, 비디오 데이터 학습 시 토큰 효율성을 최적화하는 풀링(Pooling) 전략을 도입하여, 계산 자원을 절약하면서도 영상의 세부 디테일을 놓치지 않는 정교함을 갖췄습니다.
가장 놀라운 점은 이 모든 성능이 철저히 공개된 프레임워크와 효율적인 학습 파이프라인을 통해 구현되었다는 것입니다. LLaVA-OneVision은 대규모 큐레이션 데이터셋(85M)을 활용한 3단계 학습 과정을 거치며, 단순한 시각 인식을 넘어 실제 환경의 복잡한 문제를 해결하는 ‘에이전트’로서의 가능성을 증명했습니다. 이제 개발자들은 하나의 모델만으로 정지 영상부터 실시간 비디오 분석까지 아우르는 진정한 의미의 ‘OneVision’ 솔루션을 구축할 수 있게 되었습니다.
라이벌 분석: LLaVA vs. 타 VLM 모델
2026년 현재, 오픈소스 VLM 시장은 상용 모델에 필적하는 성능을 갖춘 세 계열이 각자의 설계 철학에 따라 시장을 삼분하고 있습니다.
주요 모델별 포지셔닝
- Qwen-VL (2.5 시리즈): ‘글로벌 범용성’의 강자입니다. 수억 개의 파라미터를 가진 시각 리샘플러로 정보 밀도를 극대화하며 비디오·오디오까지 통합합니다. 뛰어난 다국어 처리 능력 덕분에 글로벌 에이전트 서비스에 주로 활용됩니다.
- InternVL (2.5+): ‘압도적 스케일’을 지향합니다. 6B급 거대 시각 인코더를 탑재해 이미지 추출 단계부터 딥러닝 수준의 추론을 수행합니다. 초고해상도 OCR이나 정밀 의료 영상 분석 등 GPT-4o의 대안이 필요한 산업 현장에 적합합니다.
- LLaVA (OneVision/Video): ‘효율성의 상징’이자 오픈소스의 표준입니다. 구조적 단순함을 유지하면서도 고품질 데이터 증류 기술을 통해 적은 자원으로 최적의 성능을 냅니다. 커스터마이징이 쉬워 온디바이스(On-device) 모델 구축 시 기업들이 가장 먼저 찾는 모델입니다.
아키텍처 관점의 차별점
LLaVA의 독보적인 위치는 타 모델과의 아키텍처 비교에서 더욱 선명해집니다.
- vs CogVLM (Deep Fusion): CogVLM이 모델 내부에 별도의 ‘시각 전문가’ 모듈을 삽입하는 깊은 융합 방식을 취한다면, LLaVA는 투사 레이어를 통해 정보를 섞는 얕은 정렬(Shallow Alignment)을 선택했습니다. 이는 복잡한 구현 비용을 획기적으로 낮추는 결과로 이어집니다.
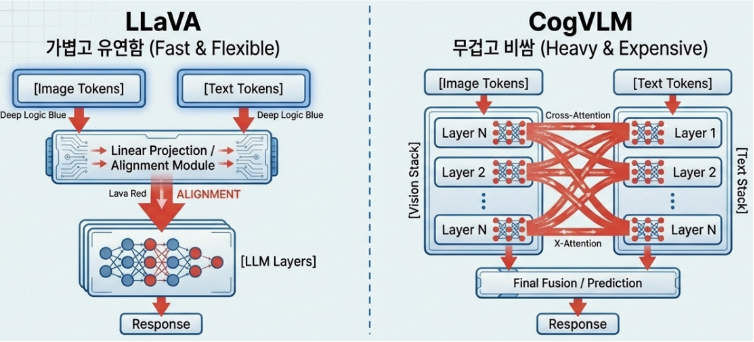
- vs Qwen/InternVL (Scaling): Qwen과 InternVL이 거대 리샘플러와 인코더 스케일링으로 승부할 때, LLaVA는 상대적으로 작은 CLIP 인코더를 사용합니다. 대신 데이터 정렬의 정교함을 극대화하여 8B 이하 중소규모 모델 시장에서 압도적인 효율성을 입증하고 있습니다.
요약: 당신의 프로젝트에 적합한 모델은?
결국 범용 서비스에는 Qwen, 정밀 분석에는 InternVL, 그리고 특화 도메인 최적화와 실전 배포에는 LLaVA가 최적의 선택입니다. LLaVA는 ‘복잡한 설계보다 정교한 데이터가 본질’임을 증명하며, 실전 지향적 VLM의 표준으로서 그 가치를 더해가고 있습니다.
실무 적용 및 향후 전망
실무 환경에서 LLaVA를 성공적으로 구축하고 운영하기 위해서는 아키텍처의 이해를 넘어선 구체적인 최적화 전략이 필수적입니다. 특히 한정된 자원 내에서 성능을 극대화하려는 개발자들에게 몇 가지 핵심 팁은 실무의 난이도를 획기적으로 낮춰줍니다.
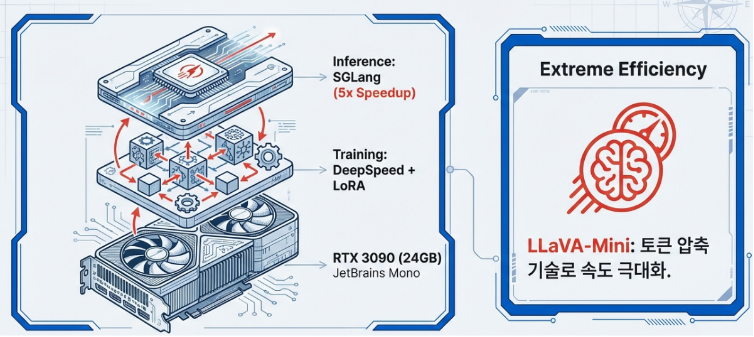
먼저 하드웨어 효율성 측면에서는 DeepSpeed와 LoRA(Low-Rank Adaptation)의 결합이 권장됩니다. 이 방식을 활용하면 파라미터 전체를 업데이트하지 않고도 메모리 사용량을 최소화할 수 있어, RTX 3090과 같은 소비자용 GPU에서도 7B 규모의 모델을 원활하게 구동할 수 있습니다. 이는 고가의 기업용 장비 없이도 고성능 멀티모달 환경을 구축할 수 있는 높은 접근성을 제공합니다.
추론 단계에서는 SGLang 엔진의 도입을 적극 고려해야 합니다. SGLang은 복잡한 프롬프트 구조를 최적화하여 기존 대비 최대 5배 빠른 추론 속도를 실현합니다. 이는 특히 대규모 비디오 캡셔닝이나 실시간 모니터링처럼 빠른 응답성이 요구되는 프로젝트에서 실질적인 생산성 향상으로 이어집니다.
만약 극단적인 효율성이 필요한 온디바이스 환경이라면 LLaVA-Mini가 훌륭한 대안이 됩니다. 이미지당 단 하나의 시각 토큰만 사용하는 압축 기술을 통해, 24GB VRAM 환경에서도 3시간 이상의 긴 영상을 처리할 수 있는 놀라운 자원 효율성을 보여줍니다.
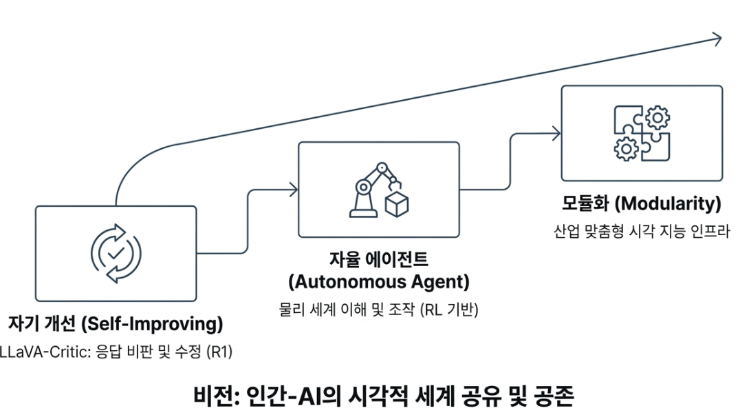
앞으로 LLaVA는 스스로 응답의 오류를 교정하는 LLaVA-Critic이나 강화 학습이 결합된 자율 에이전트 형태로 진화할 전망입니다. LLaVA는 이제 단순한 오픈소스 모델의 단계를 넘어, 시각적 세계와 언어를 연결하는 인공지능 생태계의 핵심 인프라로 굳건히 자리 잡고 있습니다.




댓글
운영 정책에 반하는 글은 사전 고지 없이 삭제될 수 있습니다.