
When interacting with AI systems over extended periods, there often comes a moment when something begins to feel subtly off. At first, the AI agent seems remarkably sharp. It understands intent with precision, generates sophisticated code, and follows complex instructions with impressive consistency. But as conversations grow longer and projects become more complicated, the system can gradually begin to lose focus.
It may forget functions that were modified only moments earlier, bring up bugs that have already been resolved, or even produce logically inconsistent hallucinations. Developers often describe this informally by saying things like, “The AI got tired,” or “It lost the thread of the conversation.” In reality, however, these behaviors are early warning signs of something far more fundamental and inevitable: Context Collapse.
Interestingly, the recent leak involving Anthropic’s Claude Code internal materials offered a rare glimpse into how leading AI labs themselves think about this problem. Within those documents, the phenomenon was described using a striking term: Context Entropy.
The analogy comes directly from the second law of thermodynamics. Just as entropy naturally increases within a closed physical system, disorder also accumulates inside long-running AI interaction sessions. Tool outputs pile up, error logs accumulate, and user instructions evolve, contradict themselves, or get revised repeatedly over time. Eventually, the agent reaches a state where distinguishing the “current truth” from outdated or conflicting context becomes increasingly difficult.
At that point, performance degradation is no longer primarily a matter of model intelligence. Instead, it becomes a failure of context management. The real challenge is not whether the model can reason, but whether it can continuously identify and preserve the critical signal buried beneath an ever-growing mountain of informational noise.al noise.
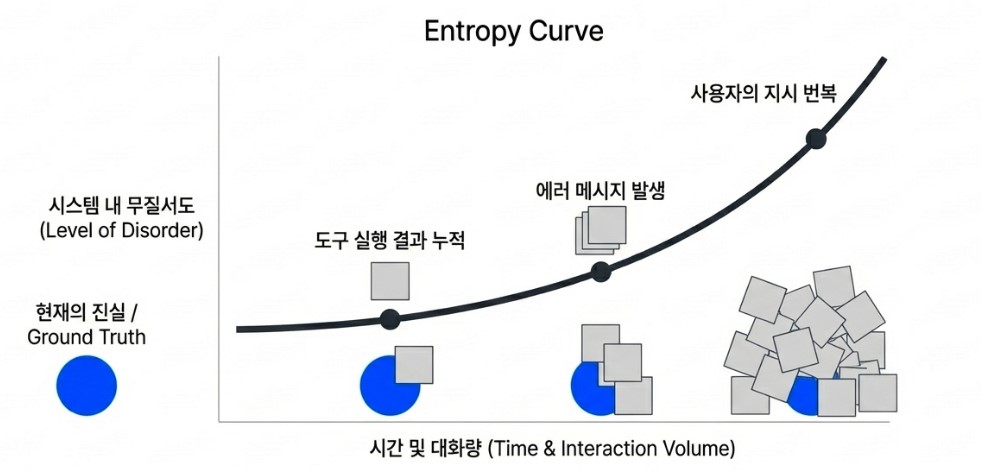
For a long time, the industry has tried to solve this problem by simply expanding the size of the context window. But increasing capacity to 100,000 or 200,000 tokens is only a temporary workaround. As the amount of information grows, disorder grows with it. Too much context can actually scatter the model’s attention and cause it to make mistakes at the very moment precision matters most.
The technical paradigm is now shifting rapidly from “how much can we fit in?” to “how precisely can we maintain what matters?”
What makes the Claude Code case especially striking is the highly detailed and almost human approach it appears to take in preventing context collapse. Rather than merely deleting or compressing data, it points toward a design philosophy in which AI periodically “sleeps” to organize memory, reviews its own recollections with skepticism, and blocks unnecessary tool interference before it contaminates the context.
This is more than a feature of one specific service. It offers a potential blueprint for the next generation of autonomous AI agents. In this article, we will examine the true nature of Context Collapse, one of the biggest barriers facing modern AI systems, and take a closer look at the mechanisms being proposed to overcome it.
The Art of Deletion: Teaching AI How to Forget Wisely
The true brilliance of human intelligence does not come from remembering everything. It comes from the ability to extract the one meaningful signal hidden within overwhelming informational noise.
For AI systems, however, especially large language model (LLM)-based agents, forgetting has long remained an unsolved problem.
As conversations grow longer, an agent’s internal memory gradually turns into something resembling a digital landfill filled with typos, meaningless greetings, repeated debugging logs, abandoned ideas, and outdated instructions. Once all of this information occupies the context window with equal weight, even a simple request like “Please modify this function” can become buried beneath the noise.
To address this issue, the industry’s earliest line of defense emerged in the form of two engineering strategies: sliding windows and selective memory management.

The sliding window approach is the most intuitive, and also the most ruthless.
The model maintains a fixed limit on how many recent tokens it can actively process. As new information enters the system, older context is continuously pushed out and discarded. It is somewhat like cramming for an exam by focusing only on the newest practice questions while older knowledge slowly disappears from memory.
But this method comes with a serious weakness: it fails to preserve historical continuity.
If the core architectural principles established early in a project or the naming conventions agreed upon by a development team eventually slide out of the context window, the agent may suddenly lose consistency and begin making contradictory or nonsensical suggestions.
From a developer’s perspective, it can feel as though a colleague who perfectly understood the project yesterday has suddenly become a stranger overnight.
To overcome these limitations, AI systems have increasingly adopted a more sophisticated strategy: importance-based selective retention.
This is not a democratic system where every piece of information is treated equally. It is a highly pragmatic hierarchy in which information earns its survival based on long-term utility and business value.
For example, in a customer-service chatbot or e-commerce assistant, casual conversation such as “How are you today?” carries almost no operational value. By contrast, a sentence beginning with “My shipping address is…” becomes mission-critical information that must be preserved at all costs.
The AI treats these two categories very differently.
The same principle can be seen in game NPC dialogue systems. Out of thousands of interactions with a player, the game may permanently remember major branching decisions such as whom the player chose to save, while casually discarding temporary jokes or small talk exchanged along the way.
Modern AI agents increasingly operate in a similar fashion.
As conversations grow longer, only the most recent exchanges remain in active memory, while older interactions are compressed into structured summaries centered around key events and decisions. This helps preserve the purity of the context without overwhelming the model’s attention mechanisms.
Ultimately, only an AI system that learns how to forget intelligently can remain coherent across thousands of conversational turns without losing sight of the project’s goals.
In that sense, the art of deletion is not really about reducing the amount of information. It is a constant struggle to preserve the quality and integrity of what truly matters.
Information Refinement and Hierarchical Memory: Turning Massive Data into Distilled Knowledge
If memory management is the painful process of deciding what to discard, then determining how the remaining information should be organized and refined belongs to a far more sophisticated architectural domain: the refinement of information itself.
Feeding thousands of pages of legal precedents or massive open-source API documentation directly into an AI model is like forcing someone to swallow an entire library whole. Overwhelmed by endless waves of text, the model eventually falls into what developers sometimes jokingly describe as a “goldfish state,” where it remembers only the last few lines it encountered.
This is precisely where techniques such as Recursive Summarization and Retrieval-Augmented Generation (RAG)-based dynamic memory step in to restore order to chaos.

Recursive summarization works by periodically compressing past interactions into distilled summaries whenever a conversation reaches a certain threshold. Instead of preserving every detail verbatim, the system extracts only the essential “knowledge essence” from earlier exchanges.
The AI summarization features now appearing in tools like Slack or Notion offer an early glimpse of this idea. Thousands of scattered messages can suddenly be reduced into three concise bullet points, transforming fragmented noise into a coherent narrative.
It resembles the behavior of an experienced student reading a dense textbook while annotating only the most important concepts in the margins, later reconstructing the broader meaning from those carefully selected keywords alone.
But this approach also introduces an unavoidable trade-off.
As summarization repeats recursively over time, subtle nuances and fine-grained logical details inevitably begin to fade. Lowering entropy often requires sacrificing informational precision. It is an engineering compromise between compression efficiency and contextual fidelity.
To overcome these limitations, the industry has increasingly turned toward a combination of hierarchical context structuring and RAG.
This approach organizes information into layered memory systems such as:
- Global Context
- Task Context
- Short-Term Conversational Memory
Core architectural principles and system-level instructions remain fixed at the highest level as immutable global memory. Current coding tasks or active problem-solving states reside within task memory. Meanwhile, lightweight conversational exchanges are handled through ephemeral short-term memory.
This layered structure dramatically improves contextual stability.
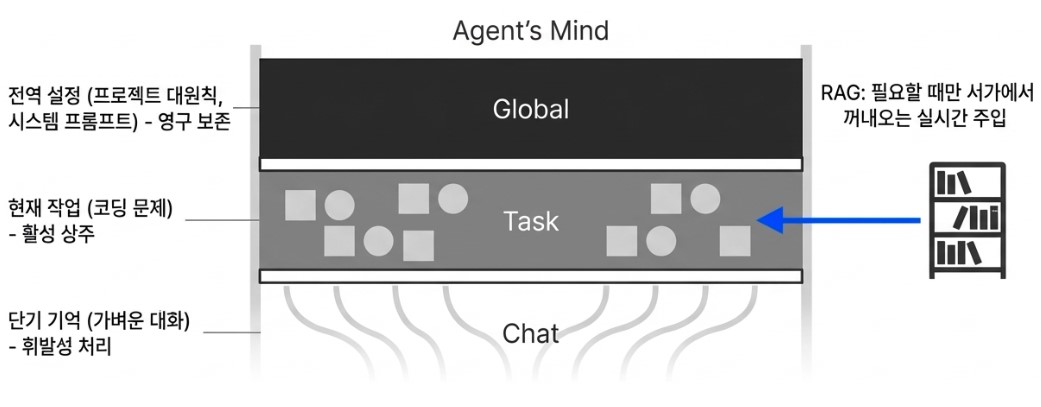
When combined with RAG, the system becomes even more powerful. Instead of forcing the model to retain every interaction indefinitely, older information is stored externally inside vector databases. Then, only when the model recognizes that a previous interaction may be relevant, such as “I’ve encountered a similar bug before,” does it dynamically retrieve the necessary context and inject it back into the reasoning process in real time.
The result feels less like brute-force memorization and more like an experienced engineer pulling the exact reference manual needed from a library shelf at precisely the right moment. Today, the combination of hierarchical memory structures and RAG has become one of the most effective ways to maximize context efficiency in modern AI systems.
And yet, even these techniques still expose an important limitation: they remain fundamentally reactive. Summarization compresses information only after it accumulates. RAG improves retrieval efficiency only after context has already fragmented. Hierarchical structuring preserves organizational flow, but the system itself still lacks genuine autonomy.
It cannot independently resolve contradictions within its own memory, proactively reorganize knowledge during idle periods, or continuously refine and purify context the way human cognition naturally does. These limitations are now pushing AI architecture toward something far more ambitious: systems capable of autonomously reorganizing their own memory, almost as if the AI itself were sleeping, reflecting, and consolidating knowledge in the background.
The next generation of AI agents is no longer evolving toward static memory management alone. It is evolving toward dynamic intelligence.
A Paradigm Shift: Conquering Entropy Through Autonomous Refinement
The techniques discussed so far were undeniably effective defensive mechanisms, but they all shared one critical weakness: they were fundamentally reactive.
They operated only after information had already entered the system. They summarized, compressed, or discarded context according to predefined rules, but they lacked any form of intelligent self-correction capable of resolving contradictions, purifying corrupted memory, or reorganizing knowledge proactively.
Against this backdrop, the design philosophy revealed through Anthropic’s Claude Code offered a glimpse into an entirely different direction for AI architecture. Rather than simply managing context, it introduced the idea of autonomous refinement, a system in which the AI actively maintains and restores order within its own memory.

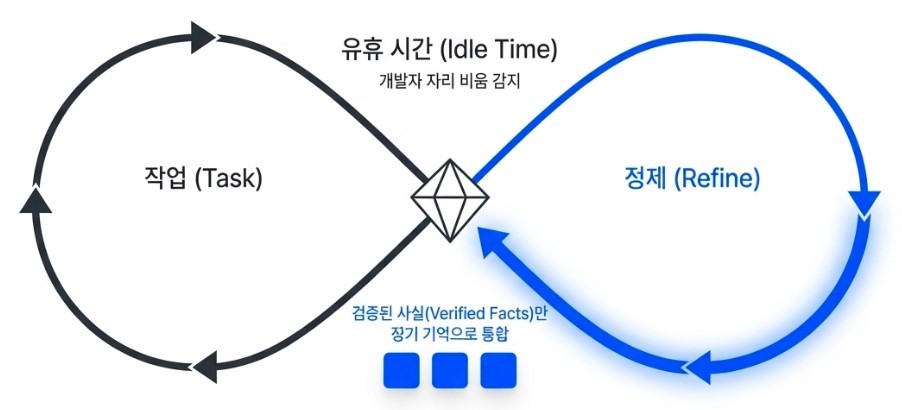
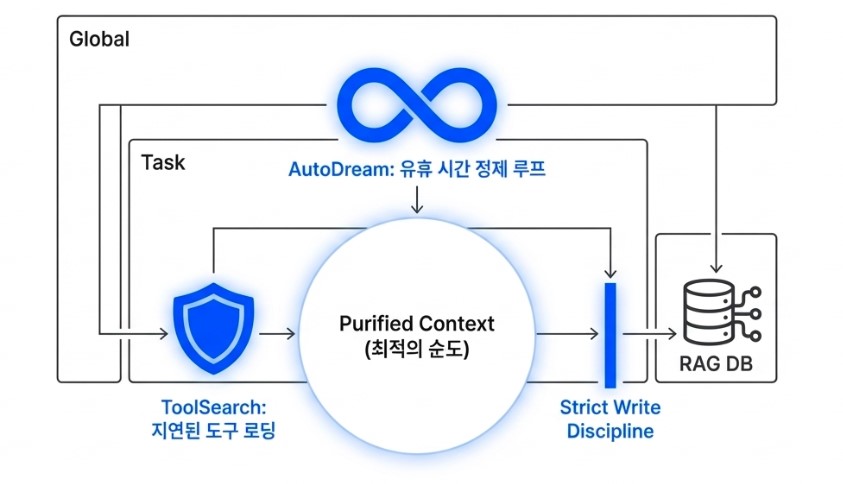
One of the most striking innovations is a mechanism inspired by human sleep, known internally as AutoDream.
Humans consolidate fragmented memories and clear neurological waste during sleep. Claude Code appears to apply a remarkably similar principle during developer idle time. While the primary agent is inactive, separate background sub-agents review previous conversations, task histories, tool outputs, and coding sessions in parallel.
The goal is not merely compression.
Instead, the system actively searches for logical inconsistencies, revisits ambiguous reasoning chains, and restructures uncertain assumptions into verified knowledge. A vague conversational statement such as “this function might be causing the issue” can later be cross-validated against the actual codebase and transformed into a far more reliable conclusion like “this function triggers an error under specific conditions.”
This represents a profound departure from earlier approaches.
Traditional memory optimization often reduced entropy by sacrificing informational precision. AutoDream moves in the opposite direction: it uses idle computational cycles to increase informational clarity and contextual purity. By the time the developer returns, the agent is no longer carrying fragmented conversational debris, but a cleaner and more refined internal understanding of the project itself.
Another particularly fascinating mechanism is Deferred Tool Loading, also referred to as ToolSearch, a strategy designed to preserve the model’s limited attentional bandwidth. Modern AI agents are connected to hundreds of external tools and APIs, and traditionally many systems loaded the full schemas and documentation for all available tools directly into context from the very beginning. This is equivalent to a chef covering the kitchen counter with manuals for hundreds of cooking utensils before even starting the recipe. The workspace becomes cluttered long before any real work begins.
Claude Code approaches this differently. Initially, the agent retains only lightweight references to tool names and high-level capabilities. Then, only at the precise moment when the model determines that a particular capability is actually necessary, does it dynamically inject the full schema and operational details for that specific tool into context.
The result is a dramatic increase in contextual purity. Instead of overwhelming the model with unnecessary technical documentation, the system preserves its attention for the user’s immediate problem. In effect, the AI actively creates an environment optimized for focus and reasoning rather than drowning itself in irrelevant information. (This concept was briefly explored in the earlier blog post, “Two Paths to Building AI Agents: CLI vs MCP.”)
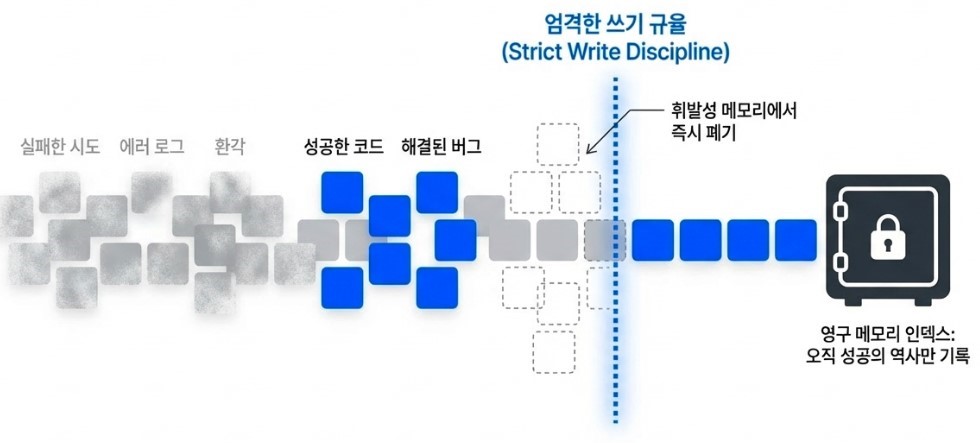
Equally important is the introduction of what could be described as a strict write discipline for memory indexing. Only successful outcomes are permanently written into long-term memory structures. Failed attempts, transient errors, and noisy intermediate reasoning steps are prevented from polluting the persistent context layer. This dramatically reduces the risk of hallucinations caused by contaminated historical memory and allows the agent to build its internal state around a curated “history of success” rather than an ever-growing archive of confusion and failure.
In many ways, this marks the beginning of a new generation of AI architecture. The goal is no longer simply to store more context. It is to cultivate cleaner, more trustworthy, and increasingly self-organizing intelligence.
Ultimately, the examples demonstrated by Claude Code point toward a much larger idea. The future of AI will not belong to systems that simply possess larger memories, but to systems capable of intelligently deciding what to doubt, what to preserve, and when to retrieve the right information at the right moment.
These forms of autonomous refinement will extend far beyond coding assistants into every professional domain where maintaining long-term contextual coherence is essential. What we are witnessing is not merely the emergence of another AI tool, but the evolution of context itself, as AI systems begin to mirror increasingly human-like patterns of thought, memory, and reasoning.
Intelligence Is Defined by What We Choose to Preserve
So far, we have explored one of the greatest challenges facing modern AI agents: Context Collapse, along with the emerging mechanisms designed to overcome it. Earlier generations of AI pursued scale above all else, striving to become ever-larger systems trained on ever-larger datasets. But the direction is now changing. The next generation of AI is evolving from a “giant that remembers everything” into something closer to a wise manager capable of selectively refining, organizing, and preserving only what truly matters.
One of the clearest lessons from both previous discussions and the Claude Code case study is that AI reliability no longer comes solely from model size. No matter how large a model becomes, it can still collapse under the weight of informational entropy if its context management fails. Techniques such as AutoDream and Deferred Tool Loading suggest that AI systems must begin to learn deeply human behaviors: forgetting unnecessary information, focusing attention on what matters most, and consolidating knowledge during periods of inactivity. These processes are not optional optimizations. They may ultimately become the foundation that allows AI agents to function as long-term collaborative partners rather than short-lived assistants that gradually lose coherence over time.
The future of the AI agent market will likely be shaped not simply by advances in model capability, but by the sophistication of context management architectures. Technologies that began as coding-assistant infrastructure are already expanding into fields such as medicine, law, finance, and research, industries where maintaining long-term contextual continuity is absolutely critical. Agents capable of sustaining clarity and consistency across projects lasting days or even weeks could fundamentally reshape human productivity far beyond what current AI systems can offer.

In the end, the defining question for future AI systems may not be “How much can they know?” but rather “How effectively can they preserve what truly matters?”
The engineering battle against context collapse is, in many ways, an attempt to bring order to informational chaos. And through that struggle, we may be witnessing the early foundations of something far more significant: AI systems capable of becoming genuinely trustworthy intellectual collaborators.
What makes this moment especially fascinating is that these systems are no longer evolving purely through scale. They are beginning to evolve through memory, prioritization, reflection, and selective forgetting, processes that increasingly resemble the structure of human cognition itself.
The fight against context entropy may ultimately shape not only the future of AI architecture, but the future relationship between humans and machine intelligence as a whole.



