
Last week, the global tech industry turned its attention to an announcement from Google Research.
The reason was the unveiling of TurboQuant, a new optimization technology capable of dramatically improving AI efficiency by overcoming one of the industry’s most stubborn hardware limitations.
Modern large language models (LLMs) can process hundreds of pages of context in a single session, giving the impression of near-limitless memory. But behind this impressive capability lies a critical infrastructure problem known as the KV Cache bottleneck.
An easy way to understand this is to imagine a scholar working at a desk. The more information the scholar needs to reference, the more documents pile up across the workspace. In this analogy, the desk represents GPU memory (VRAM), while the scattered documents represent the model’s KV cache.
As conversations grow longer and context expands, the desk quickly becomes overcrowded. Eventually, there is no remaining space for new information, causing severe slowdowns or even complete memory exhaustion, commonly known as an Out-of-Memory (OOM) failure.
The most obvious solution would be to buy a larger desk.
But in reality, endlessly scaling GPU infrastructure comes with enormous financial and physical costs, including skyrocketing hardware expenses and power consumption.
This is where TurboQuant introduces a fundamentally different idea.
Instead of expanding infrastructure, Google focused on reducing the “physical size” of the data itself.
More importantly, TurboQuant does not merely compress data aggressively at the expense of quality. It demonstrates a form of mathematical efficiency that dramatically reduces memory usage while preserving inference accuracy.
TurboQuant represents more than just another optimization update.
It signals a broader shift in AI computing philosophy, moving the industry away from brute-force hardware scaling and toward intelligent efficiency-driven architectures.
What Is TurboQuant?
At its core, TurboQuant is a highly efficient quantization algorithm designed to maximize data density without degrading model inference quality.

Its most important breakthrough is what could be described as quality neutrality: dramatically reducing memory consumption while preserving the integrity of the original information.
Normally, aggressive compression introduces distortion.
Just as reducing the size of an image often degrades visual quality, compressing AI model data typically causes inference instability or hallucinations.
TurboQuant solves this long-standing tradeoff through an outlier-aware strategy.
Imagine packing for an overseas trip.
Bulky winter clothes can easily be compressed inside vacuum bags without issue. But fragile wine glasses or delicate camera lenses cannot be squeezed the same way without damage.
AI data behaves similarly.
Within neural activations, certain highly sensitive values play a disproportionately important role in preserving model behavior. These critical elements are referred to as outliers.
TurboQuant intelligently separates ordinary data from these fragile outliers before compression begins.
It then applies highly granular bit allocations such as 2.5-bit or 3.5-bit precision depending on the characteristics of the data itself, maximizing storage efficiency while minimizing quality loss.
The result is an extreme level of compression efficiency that was previously considered impractical in real-world systems.
A Technical Deep Dive: The Two Pillars Behind TurboQuant
So far, we’ve explored how TurboQuant dramatically reduces memory usage while preserving AI inference performance.
But what exactly makes this possible under the hood?
At the implementation level, TurboQuant’s ability to overcome hardware limitations is built on two core technologies.
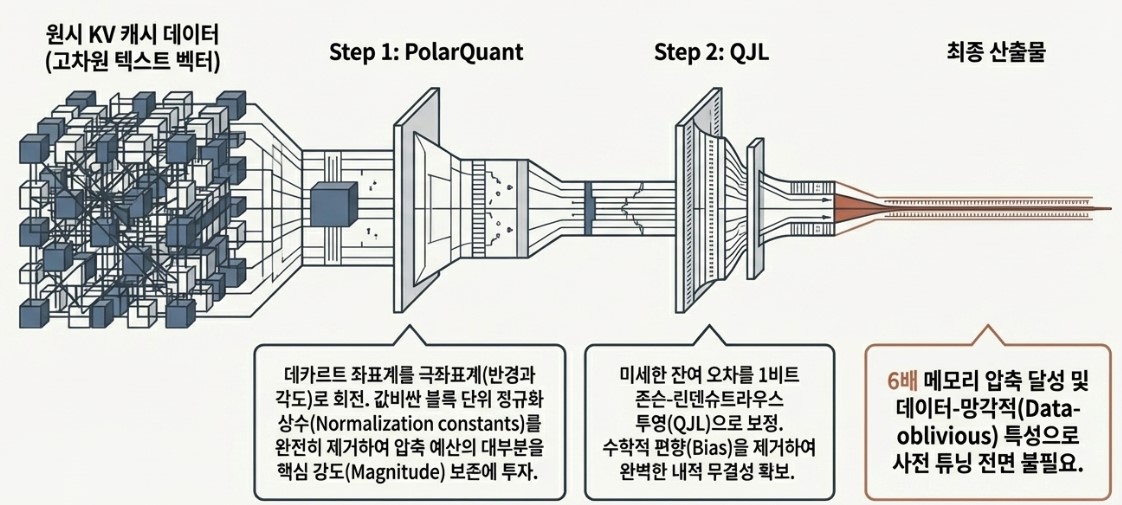
PolarQuant: Reinventing Coordinates to Eliminate Wasted Space
The first major component, PolarQuant, fundamentally redefines how data itself is represented.
Traditional AI systems typically store data using Cartesian coordinates based on horizontal (X) and vertical (Y) axes. While effective, this approach introduces an important limitation: each block of data tends to have a completely different numerical range.
To compress these blocks into standardized formats, the system must attach additional metadata explaining the original scale of each block. These auxiliary descriptors are known as normalization statistics.
The problem is that this metadata itself consumes memory, often accounting for roughly 1 to 2 bits per block.
In other words, even after compressing the data, valuable memory is still wasted storing the “labels” needed to explain the compressed representation. This overhead significantly reduces real-world compression efficiency.
PolarQuant addresses this issue by introducing a completely different framework: polar coordinates.
Instead of representing data through horizontal and vertical positions, PolarQuant expresses information using two intuitive elements:
- Radius (distance)
- Angle (direction)
This simplifies complex coordinate structures into cleaner directional vector representations.
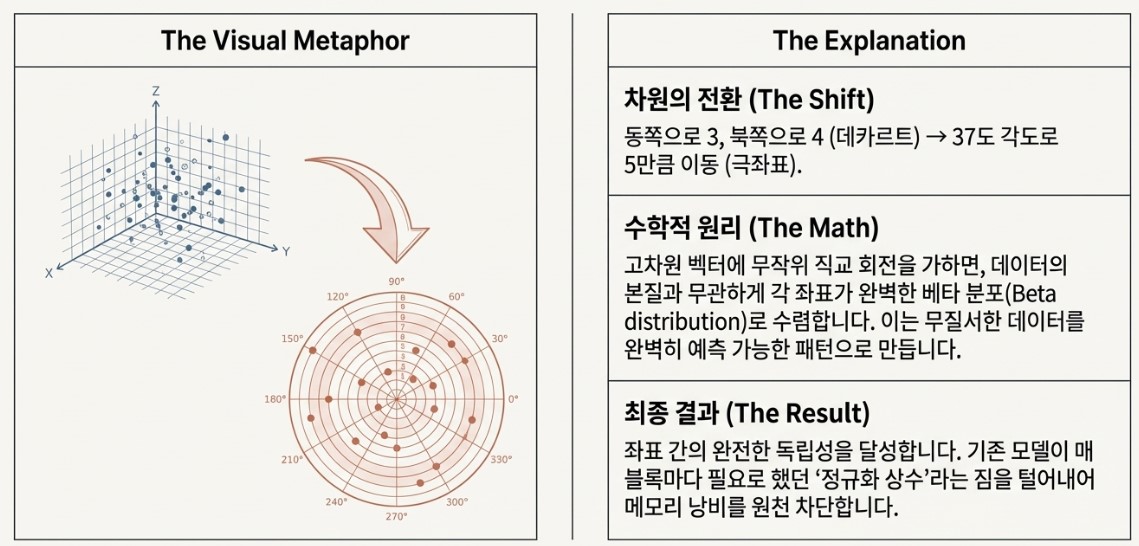
But the real breakthrough comes from PolarQuant’s use of random rotation.
When irregular high-dimensional data is mathematically rotated, the distribution of that data becomes more statistically uniform, often approaching Gaussian-like structures.
Once the data becomes organized into predictable distributions, the system no longer requires heavy normalization metadata for every individual block. Because the overall structure of the data is already mathematically understood, the compressed information can be reconstructed accurately without attaching additional explanatory “tags.”
As a result, PolarQuant nearly eliminates memory wasted on auxiliary information and dedicates almost all available capacity to preserving the actual data itself.
This is the true technical essence of PolarQuant: removing wasted space at the structural level to maximize compression efficiency.
To visualize the difference, imagine giving someone directions to hidden treasure.
Traditional Cartesian coordinates might sound like this:
“Walk 300 meters east, then turn 90 degrees and walk another 400 meters north.”
It works, but the explanation is long and rigid.
PolarQuant’s approach is much cleaner:
“Face 37 degrees northeast and walk straight for 500 meters.”
The destination is communicated more intuitively, with less unnecessary information.
That is essentially what PolarQuant achieves.
Instead of forcing data into rigid X and Y coordinate structures, it expresses information as elegant directional vectors built from angle and distance.
In doing so, it transforms bulky coordinate descriptions into streamlined mathematical representations optimized for extreme compression efficiency.
QJL (Quantized Johnson-Lindenstrauss): Correcting Residual Errors with 1-Bit Measurements
The second core pillar of TurboQuant is QJL, a technique designed to precisely compensate for the tiny data loss introduced during the PolarQuant compression process. These small discrepancies are known as residual errors.
Large language models operate through billions of layered mathematical operations. Under aggressive compression, even the most sophisticated algorithms inevitably introduce slight deviations from the original data.
Individually, these errors may appear insignificant. But as they accumulate across massive inference pipelines, they can eventually lead to serious performance degradation or unintended model bias.
To address this problem, TurboQuant builds upon a mathematical principle known as the Johnson-Lindenstrauss (JL) Lemma.
At the heart of the JL Lemma is the idea of random projection.
The principle states that even when high-dimensional data is projected into lower-dimensional space through random matrices, the relative distances and angular relationships between data points remain statistically preserved.
TurboQuant pushes this idea even further through a highly compressed variation called Quantized Johnson-Lindenstrauss (QJL).
The process works in three stages.
Step 1: Creating a “Shadow” of the Error
First, the residual error vectors remaining after PolarQuant compression are randomly projected into a lower-dimensional space.
Rather than storing the original error information directly, TurboQuant creates a lightweight mathematical “shadow” of those errors.
Step 2: Extreme 1-Bit Quantization
Next, the projected values are reduced to an extremely compact representation.
Instead of preserving exact numerical values:
- Positive values become +1
- Negative values become −1
In other words, the entire correction signal is compressed into a simple 1-bit directional sign.
Step 3: Correcting Dot Product Operations
One of the most important operations inside LLMs is the dot product, which measures how similar two vectors are during contextual reasoning.
Although QJL discards the precise magnitude of the original residual errors, something remarkable still happens:
When these compressed 1-bit signals participate in dot-product calculations, their statistical expectation remains aligned with the original error distribution.
In mathematical terms, this property is known as an unbiased estimator.
The exact numbers are gone, but the overall statistical behavior remains intact.
An intuitive way to think about QJL is to imagine correcting the trajectory of an arrow being pushed slightly off course by wind.
Instead of attaching a heavy and complex wind-measurement system to calculate every disturbance precisely, you add an ultra-light 1-bit counterweight to the arrow’s tail, allowing its flight path to statistically converge back toward the center of the target.
That is essentially what QJL achieves.
Without storing large correction datasets or expensive metadata, TurboQuant preserves mathematical consistency using only a tiny amount of additional information.
Ultimately, TurboQuant’s efficiency comes from the combination of two complementary technologies:
- PolarQuant, which reconstructs massive datasets into highly efficient representations
- QJL, which intelligently neutralizes residual errors with minimal overhead
Together, they form the mathematical foundation behind TurboQuant’s high-efficiency AI infrastructure.

In many ways, PolarQuant acts like an intuitive compass that brings order to a vast forest of data, while QJL serves as a 1-bit magician that erases the faint residual traces left behind within that forest.
It is the elegant harmony between these two powerful pillars that makes TurboQuant possible, allowing software-driven mathematical optimization to push beyond the physical limits of silicon itself.
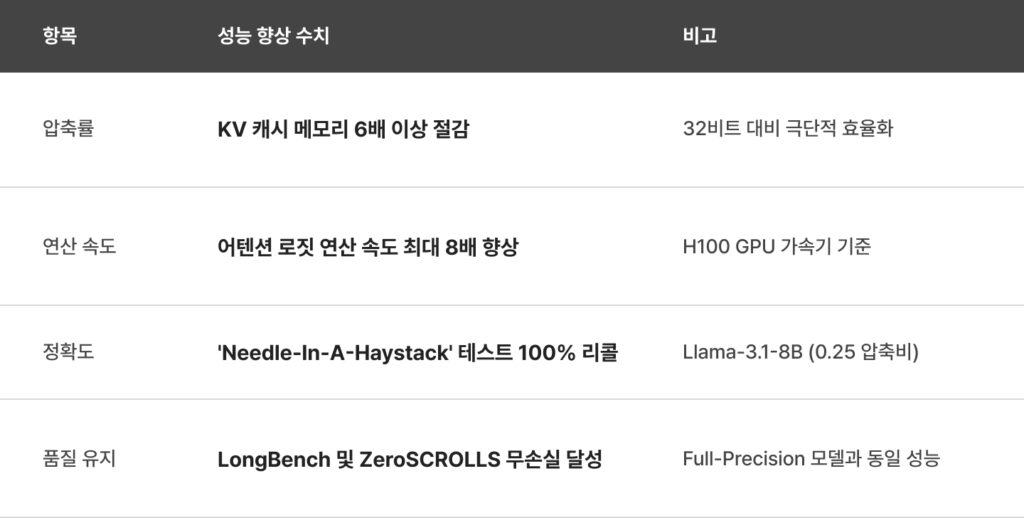
Remarkable Performance Gains: 6× Compression and 8× Acceleration
TurboQuant is far more than a theoretical concept.
Its real-world performance results, validated on NVIDIA H100 GPU systems, are nothing short of remarkable.
Why TurboQuant Stands Apart from Existing Compression Technologies
At this point, a natural question arises: “Haven’t AI data compression techniques existed before?”
Of course they have. However, the reason TurboQuant has attracted such global attention is that it overcomes many of the long-standing limitations of earlier approaches through what can best be described as mathematical completeness.
Where previous methods often relied heavily on heuristics, empirical tuning, or engineering intuition, TurboQuant elevates compression into the realm of rigorous mathematical optimization.
Its advantages become especially clear when compared with earlier approaches.
Mathematically Grounded Compression (vs. Existing Quantization Methods such as KIVI)
Earlier techniques such as KIVI frequently suffered from unstable compression efficiency depending on the structure and distribution of the data itself. In some cases, this could introduce noticeable distortion or inconsistent model behavior.
TurboQuant takes a fundamentally different approach. Instead of relying primarily on empirical approximations, it is grounded in information theory, particularly the concept known as the Shannon Lower Bound.
This boundary represents the theoretical physical limit of data compression efficiency. TurboQuant mathematically demonstrates that its compression performance operates within approximately 2.7× of this theoretical optimum, an extraordinarily close margin in practical AI systems.
This is not merely an engineering estimate or a heuristic approximation. It is a rigorously calculated result that approaches the mathematical limits of compression itself.
Complete Information Preservation (vs. Selective Deletion Methods such as SnapKV)
Some existing memory optimization systems, including approaches like SnapKV, reduce memory usage by selectively discarding tokens or contextual information deemed less important.
The problem is that these discarded fragments can later become critical for long-context reasoning.
As a result, aggressive token deletion can increase the likelihood of hallucinations, where the AI generates inaccurate or inconsistent responses because essential contextual clues were lost earlier in the conversation.
TurboQuant avoids this tradeoff entirely. It does not discard a single token.
Instead of deleting information, TurboQuant preserves the original data in full while increasing its storage density through highly efficient mathematical representation. In other words, it achieves compression without sacrificing informational integrity.
Real-Time Compression Without Pretraining (vs. Product Quantization, PQ)
Traditional Product Quantization (PQ) techniques require large pretrained codebooks to compress and reconstruct data efficiently. In practice, this means developers must first build and maintain extensive lookup structures before compression can even begin. It is somewhat like trying to lighten a backpack while carrying an enormous translation dictionary alongside it.
TurboQuant eliminates this overhead entirely. It requires no pretrained codebooks, no additional calibration stages, and no heavy decoding infrastructure. Instead, compression occurs dynamically during inference runtime itself, allowing optimization to happen in real time without introducing additional system burden.
Ultimately, TurboQuant surpasses many of the compromises that defined earlier compression approaches.
Rather than deleting data, relying on heavy auxiliary systems, or accepting unstable approximations, it establishes a new standard for AI compression grounded in mathematical precision and efficiency.
Industry Impact: Hardware Shockwaves and the Future Shaped by Jevons Paradox
The impact of TurboQuant spread far beyond research labs almost immediately after its announcement. What appeared to be a breakthrough in software optimization was interpreted by the hardware industry as both a technological marvel and a potential threat.
The market reaction made that anxiety visible.
Shortly after the announcement, major memory manufacturers such as Samsung Electronics (-4.7%) and SK hynix (-6.2%) saw noticeable declines in their stock prices. The concern was straightforward:
“If compression technology dramatically improves memory efficiency, won’t companies need fewer expensive semiconductors and GPUs?”
It was a familiar pattern, almost reminiscent of the panic that once spread through the oil industry whenever dramatic improvements in fuel efficiency emerged.
But this is precisely where Jevons Paradox becomes important.
In 19th-century Britain, improvements in steam engine efficiency led many to assume coal consumption would decline. Instead, lower operating costs accelerated industrial adoption so aggressively that total coal consumption increased exponentially.
The AI industry may now be approaching a similar moment.
Even if TurboQuant creates six times more effective memory capacity, developers are unlikely to leave that newly available space unused. Instead, they will use it to build longer and more sophisticated chains of thought (CoT), process increasingly massive multimodal datasets combining text, video, and audio, and push AI systems toward far more advanced reasoning capabilities.
In other words, greater efficiency does not necessarily reduce demand. It often expands the scale of what becomes economically possible. From this perspective, TurboQuant is not a threat to the semiconductor industry. If anything, it may become a catalyst that lowers the barrier to entry for countless organizations previously held back by infrastructure costs.
While memory usage per operation may decrease in the short term, the long-term effect could be the exact opposite: accelerating the pursuit of larger, deeper, and more capable AI systems, ultimately driving a new era of demand across the memory and AI hardware ecosystem.

Conclusion: From On-Device AI to Autonomous Visual Intelligence
Through TurboQuant, Google is doing something remarkable: bringing the power of massive AI systems, once accessible only to a select few, into everyday life. We are entering an era defined by the democratization of AI performance and the rise of autonomous intelligence, where machines are increasingly capable of reasoning and acting on their own.
One of the first transformations users will experience is the maturation of on-device AI.
Combined with technologies like TurboQuant, next-generation mobile processors such as Google’s Tensor G5 chip could overcome many of the physical memory limitations traditionally associated with smartphones and edge devices.
This means massive amounts of data can be processed directly on-device without relying heavily on cloud connectivity, enabling a new generation of privacy-preserving AI that delivers both security and performance in the palm of our hands. TurboQuant may also become one of the core enabling technologies behind Agentic Vision, expected to play a major role in systems like Gemini 3 Flash.
Autonomous visual reasoning requires AI systems to actively zoom, crop, rotate, and inspect images in search of contextual clues. These dynamic reasoning workflows inevitably create enormous memory pressure.
TurboQuant helps support this process efficiently, enabling visual intelligence systems to operate smoothly and responsively without latency bottlenecks.
Ultimately, the future envisioned by TurboQuant is one of fully localized intelligence.
Massive AI models that once required prohibitively expensive server infrastructure may soon run on ordinary laptops and consumer devices. This could fundamentally lower the infrastructure barrier for developers around the world, allowing far more people to experiment with and build next-generation AI systems.
In that sense, TurboQuant is far more than a compression technology.
It is a mathematically engineered framework that compensates for the physical limits of silicon itself, allowing AI systems to reason more continuously and efficiently without being constrained by memory bottlenecks.
Freed from infrastructure limitations, AI is steadily evolving toward a new stage of autonomous intelligence capable of solving increasingly complex problems with minimal human intervention. We may now be standing at a pivotal moment, one where efficient memory architectures become the foundation for the next major expansion of human and machine intelligence alike.



