
How DeepSeek Decoupled Memory and Reasoning
In January and February 2026, the AI industry is being hit by a wave of world shaking technologies almost every day. Amidst this massive tide, the Engram paper published by DeepSeek in January has raised a fundamental question for the entire industry that goes beyond mere performance metrics. It directly targets the inherent limitations of the Transformer architecture, a framework that many experts have taken for granted or even overlooked.
Until now, Large Language Models (LLMs) have performed the same heavy neural network computations whether they were conducting complex logical reasoning or simply recalling fixed, static knowledge. This meant they suffered from a fatal inefficiency, wasting massive GPU resources and computing power to reconstruct simple Memory every single time.
To solve this inefficiency, DeepSeek’s Engram introduced an innovative structure called Conditional Memory. In simple terms, it maximizes operational efficiency by completely separating the domains responsible for simple recall and complex thinking.
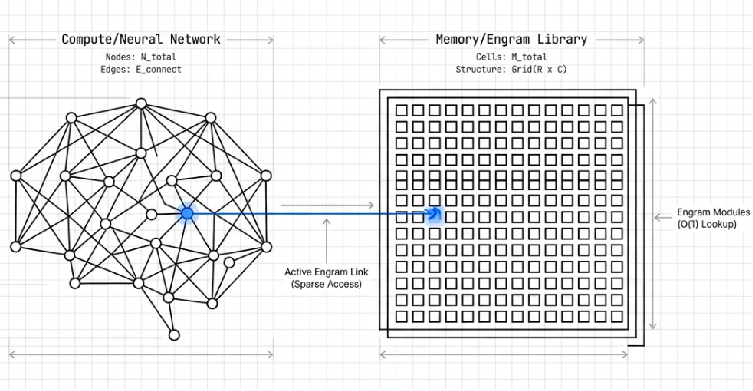
At the heart of this system is the $O(1)$ Hash Lookup method, which allows the model to retrieve static knowledge instantly, much like looking up a word in a dictionary. The term $O(1)$ Hash Lookup refers to a search method where the speed does not decrease regardless of how vast the stored data becomes, finding the desired information in a single check. It is like scanning a barcode in a giant warehouse to immediately get the exact coordinates of an item, rather than searching through every box one by one.
By applying this principle, Engram instantly retrieves fixed facts such as “The capital of France is Paris” without heavy computation. By offloading the burden of simple memorization to a specialized module, the core neural network (MoE) can devote all its energy exclusively to high level logical reasoning and thought. As a result, the model can focus entirely on solving much deeper and more complex problems using the saved computational resources.
Recall the actions of DeepSeek last year, which astonished the world with overwhelming efficiency and architectural innovation. If this revolutionary Engram architecture becomes the foundation for the expected DeepSeek V4, it will undoubtedly deliver another massive shock to the AI market, which has been preoccupied with a mindless race to increase compute. The era of blind scaling is fading, and the era of structural innovation is officially beginning.
In this post, we will delve deep into how DeepSeek Engram stripped away the long standing inefficiencies of the Transformer, the technical principles of $O(1)$ lookup, and what this means for the future competition for AI supremacy.

The Critical Contradiction of Transformers: A Brain That Cannot Distinguish Memory from Reasoning
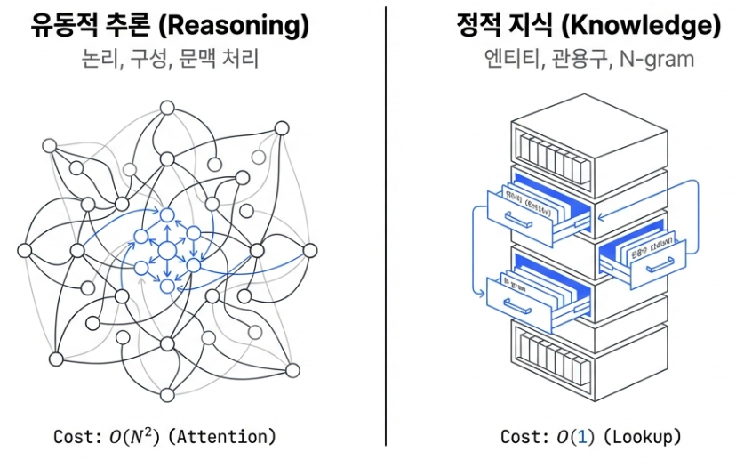
The Large Language Models (LLMs) we commonly use demonstrate remarkable performance, yet looking inside reveals a serious structural contradiction. The research team finds the fundamental cause in the Linguistic Duality that defines the essence of language. Language consists of both Compositional Reasoning which handles complex logical causality and Knowledge Retrieval which simply recalls fixed, static facts.
However, existing Transformers make no distinction between these two. When retrieving a simple fact like “What is the capital of France?” or processing a proper noun like “Diana, Princess of Wales,” the model consumes a massive number of attention neurons in its initial layers, just as it would when performing a complex mathematical proof. As the paper points out, because standard Transformers lack a primitive function for unique knowledge retrieval, they waste precious resources by forcibly simulating trivial tasks which could be handled by a simple lookup table through expensive computations.
Recall that the biggest obstacle to implementing AI in manufacturing lines or industrial CAD environments was the heavy computational load. Just as an extremely optimized YOLO architecture is essential for machine vision systems that analyze high resolution images in real time, the fundamental principle of engineering within limited computing resources is to strictly separate light processing from heavy reasoning.
While existing Transformers continued to waste resources by ignoring these fundamentals, DeepSeek placed this exact issue under a microscope. If Google’s Titans architecture emphasized dynamic learning through Neural Memory that learns at the time of inference, DeepSeek’s Engram took the opposite approach by building a massive Static Library. It essentially blocked the unnecessary computations previously used to reconstruct simple static facts at their source.
Conditional Memory: A New Axis of Sparsity
The Conditional Memory introduced by DeepSeek is a core idea that completely breaks through the limitations of existing architectures. While conventional Mixture of Experts (MoE) models focused on reducing computational waste by deciding which experts to activate, Engram goes a step further by focusing on which knowledge to retrieve instantly, thereby eliminating waste in both memory and the search process.
Technically, this can be summarized as a perfect division of labor between ‘Sparse Computation‘ and ‘Sparse Lookup’.
- Sparse Computation (MoE): Optimization of Thinking
This maximizes operational efficiency by selectively activating only the necessary expert neural networks according to the input context. In other words, it handles the process where the model develops highly logical thinking. - Sparse Lookup (Engram): Optimization of Knowing
Using the input context as a key, it retrieves knowledge directly through a hash search with $O(1)$ complexity. This means it handles the process where the model instantly recalls facts it already knows.
The core of this innovation lies in a fundamental change in how knowledge is stored. Engram boldly discarded the outdated method of heavily embedding frequently occurring static knowledge within complex neural networks or model weights. Instead, it modernized the classical Natural Language Processing concept of N grams to build a massive Knowledge Warehouse (embedding table) outside the model’s core brain.
Now, the model no longer wastes energy running complex neural network operations to recall obvious information. By structurally and perfectly separating what to think from what is already known, it can instantly pull knowledge from the external warehouse and distribute limited hardware resources in the most optimized form possible.
The Three Core Mechanisms of Engram: Perfecting O(1) Retrieval
To prevent structural waste, Engram employs a Conditional Memory structure that delegates high level logical reasoning to the existing core neural network (MoE) while instantly retrieving immutable simple knowledge from an external warehouse.
How does this innovative memory system work together like precision clockwork? Here are the three core mechanisms of Engram that enable perfect knowledge retrieval.
Unifying Scattered Meanings: Tokenizer Compression
Storing every variation of a word in memory causes capacity to expand exponentially. When an AI reads, terms like “Apple,” “apple,” and ” apple” with a space have slightly different forms but share the same meaning. To maximize the density of the memory warehouse, Engram undergoes a preprocessing phase that unifies case and removes unnecessary spaces and symbols. It compresses words with identical meanings into a single Canonical ID. This process reduces redundant data within the effective vocabulary set by approximately 23%, fundamentally preventing the waste of precious memory space.
Cross-Validation to Prevent Address Overlap: O(1) Lookup via Multi-Head Hashing
The cleanly organized words are reconnected into meaningful clusters known as N grams. Instead of searching for these clusters through complex computations, Engram performs a magical hash function that instantly converts them into exact address values within a massive memory table. Consequently, the time required for data exploration always guarantees an instantaneous $O(1)$ lookup speed, regardless of the context length.However, a potential issue called Hash Collision may occur, where completely different words are accidentally assigned to the same address. To prevent such delivery errors, Engram deploys multiple independent address explorers (multi heads) simultaneously. Even if one explorer retrieves an incorrect noise value due to a collision, the robust safety net ensures that the correct information retrieved by the other explorers overwrites and cancels out the error.
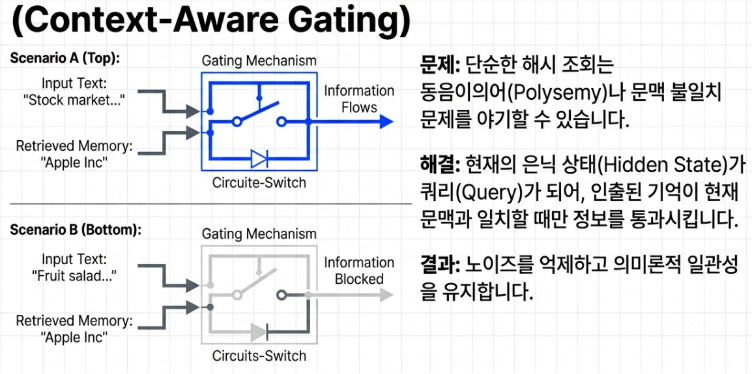
Ironclad Defense by a Smart Gatekeeper: Context-aware Gating
Even if knowledge is retrieved at the speed of light through hashing, it cannot be blindly integrated into the AI’s main thinking process. The model must determine whether the retrieved static memory “Apple” refers to a delicious fruit or the tech company that makes iPhones by grasping the current flow of conversation.
To achieve this, Engram establishes a Smart Gatekeeper (Gate). Based on the hidden state that the model has identified throughout the conversation, this gatekeeper assigns a real time score to determine if the retrieved knowledge is essential for the current situation. This score is calculated between 0 and 1. If the information is irrelevant noise that conflicts with the current context, the score drops close to 0. As a result, useless information is safely suppressed and blocked before it can merge into the core AI operations.
Thanks to this sophisticated system, the Transformer’s inherent main computational engines, specifically Attention and MoE, have been completely liberated from the tedious labor of mechanical memorization. The model can now devote 100% of its precious computing power to deeper logical reasoning and grasping macroscopic contexts. This represents more than a simple increase in efficiency; it is a true architectural paradigm shift that fundamentally resolves the resource waste issues previously inherent in hyperscale AI.
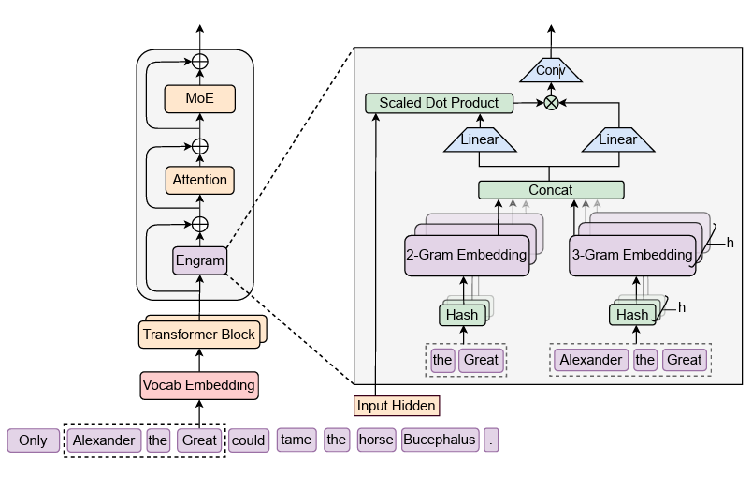
The Paradoxical Enhancement of Reasoning: Better Thinking by Emptying Memory
Engram goes beyond simply storing knowledge; it deepens the Effective Depth of the model. Through LogitLens and KL Divergence analysis, DeepSeek revealed that Engram accelerates the convergence of the Residual Stream within the model.
As Engram took full responsibility for the static knowledge restoration previously performed in the early layers, the upper layers became free to concentrate entirely on complex reasoning.
“Engram relieves the backbone’s early layers from static reconstruction,
effectively deepening the network for complex reasoning.”
Architecture Note: Key Performance Improvement Metrics
- Knowledge Performance: MMLU +3.4, CMMLU +4.0
- Reasoning Performance: BBH +5.0, ARC Challenge +3.7
- Math and Code: MATH +2.4, HumanEval +3.0
These results demonstrate that Engram is more than a knowledge assistant; it is an innovation that secures the brain’s available energy, allowing the model to engage in higher order thinking.
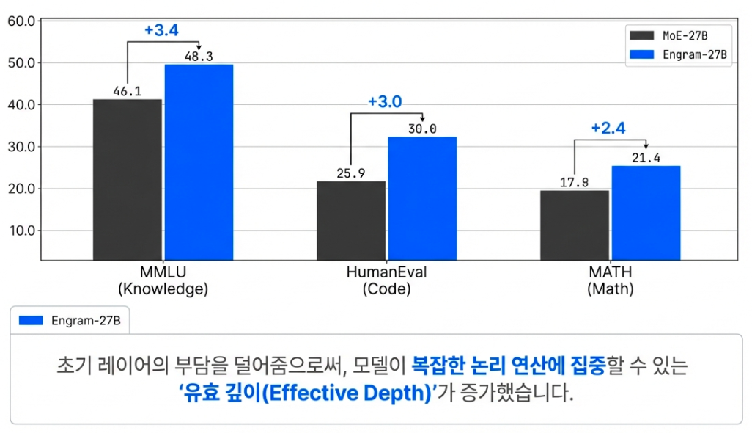
Finding the Optimal Balance: The U-shaped Scaling Law
Another fascinating discovery proven by the DeepSeek research team in this paper is the U-shaped Scaling Law. Simply put, they found the answer to the question: “How much of a model’s limited brain capacity should be invested in memory (Engram) versus thinking power (MoE computation) to create the smartest AI?”
The results derived after numerous experiments were clear. Model performance was maximized when approximately 20% of the total capacity was allocated to Engram (simple memory) and the remaining 80% to MoE (complex reasoning).
If the model relies too heavily on memory, it loses the thinking power necessary to develop complex logic independently. Conversely, if all resources are poured into computation, it wastes unnecessary energy rethinking obvious facts from scratch every time. Thanks to this golden ratio of 8 to 2, the initial layers of the model have been completely liberated from simple memorization tasks, allowing them to focus on much deeper and sharper reasoning.
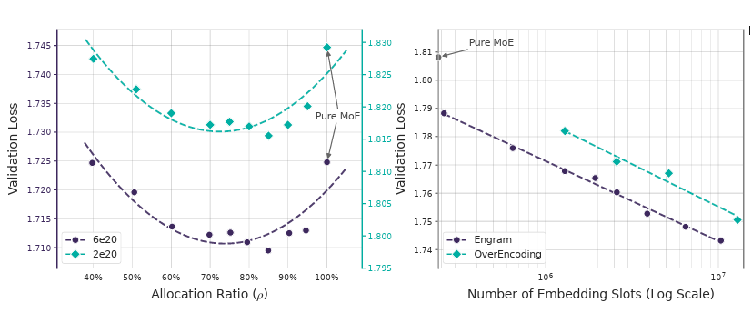
System Level Innovation: Liberation of GPU Memory (HBM)
For field engineers and business leaders, the most welcoming aspect of Engram is likely its ability to break free from hardware limitations, specifically the constraints of expensive and scarce GPU memory (HBM).
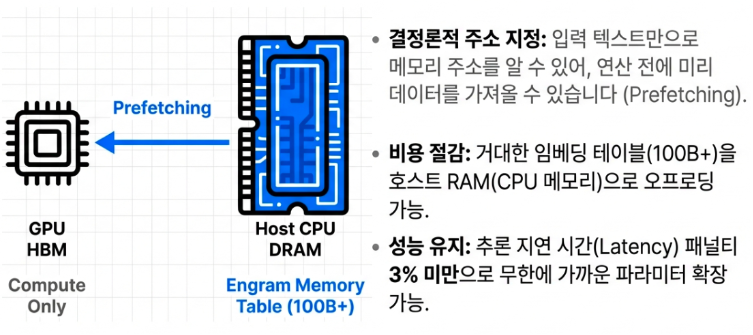
The massive knowledge dictionary or embedding table of Engram described earlier features a simple and deterministic Hash structure that does not require complex neural network computations. Therefore, there is no need to force this vast dictionary into the VRAM of ultra expensive GPUs, which are currently facing severe supply shortages.
Instead, the knowledge dictionary is stored in the main memory of general servers, such as CPU DRAM, which is significantly cheaper and offers flexible capacity expansion. Because static knowledge is instantly matched and retrieved only when needed, storing it in less expensive memory results in almost no latency. This is a tremendous innovation that has opened a completely new breakthrough through smart architectural design, moving away from the era of infinite hardware competition where companies were forced to continuously purchase more GPUs.
The Upcoming V4 and the New Standard for AI Architecture
Recently, the AI industry has been racing to introduce State Space Models (SSM) like Mamba, Graph Neural Networks (GNN) for complex topological structures, and Visual Language Models (VLM) for multimodal environments to overcome the limitations of existing architectures. At the root of all these innovations lies a sense of urgency: there is no future in relying solely on mindless increases in compute.
At this very point, DeepSeek Engram demonstrates the triumph of a new design philosophy: Large Language Models (LLMs) must structurally and completely separate how they think (computation) from how they remember (memory). This is not just a simple technical trick; it is a revolutionary evolution that overcomes the Memory Wall, a physical hardware limitation, through architectural wisdom and the redistribution of the neural network’s cognitive labor. It has perfectly fitted the final puzzle piece of Pure Memory that was always missing from the Transformer ecosystem.
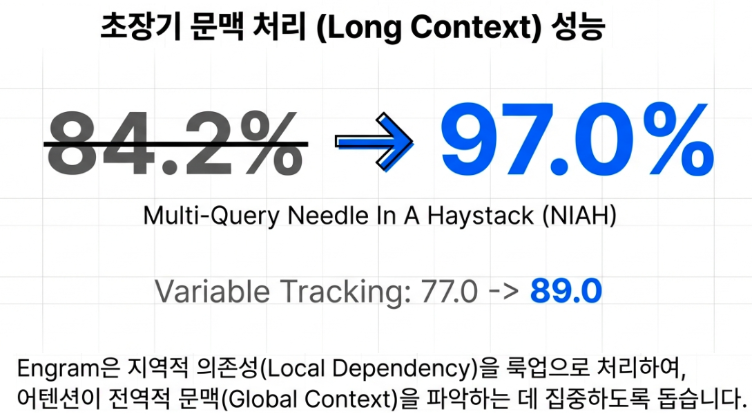
This Engram technology will serve as the core engine supporting a massive context window of over one million tokens in the next generation DeepSeek V4. By resolving simple memorization or local dependency issues through instantaneous hash lookups, it provides high density retrieval capabilities that never lose key information, even within ultra long contexts. The specific industrial changes V4 is expected to bring are as follows.
- High-Density Retrieval
Based on Multi Query Needle In A Haystack (NIAH) performance, which finds multiple hidden needles simultaneously, it accurately extracts dozens of key pieces of information from vast documents at once. - Analysis of Hyperscale Codebases
By retrieving complex code structures and identifier patterns spanning tens of thousands of lines at $O(1)$ speed, it minimizes reasoning errors during the development and debugging process. This appears to be a strong advantage for gaining an edge in the competition against Western LLM providers such as Claude or Gemini. - Lossless Long Term Memory
It solves the chronic problem of Memory Dilution, where earlier content is forgotten as the context length increases, through the perfect structural separation of computation and memory. - Disruption of Infrastructure Costs
By allowing for the flexible expansion of parameters without being tied to expensive and capacity limited GPU HBM (High Bandwidth Memory), it drastically lowers the unit cost for enterprises to build AI services.
Consequently, Engram will move beyond being a mere tool for performance enhancement to establish itself as a core Standard (Primitive) that next generation Sparse Models must possess.
If the soon to be released DeepSeek V4 emerges with Engram as its main architecture, the central topic of the AI industry will shift completely: from “Who owns more GPUs?” to “Who designed a smarter architecture?” The era of Compute Maximalism is fading, and a true Era of Design is dawning.




Comments
Posts that violate our policies may be removed without prior notice.