
2017년 논문 ‘Attention is All You Need’가 발표된 이후, 트랜스포머(Transformer) 아키텍처는 인공지능 세계의 절대적인 지배자로 군림해 왔습니다. 하지만 이 강력한 아키텍처는 태생적인 한계를 안고 있었습니다. 바로 시퀀스 길이가 길어질수록 계산량이 기하급수적으로 늘어나는(O(L2)) ‘제곱의 벽(Quadratic Wall)’입니다. 현대 AI의 끝없는 문맥 욕구는 이 아키텍처를 한계점까지 밀어붙였습니다.
이 거대한 벽을 허물기 위해, 2023년 말 카네기 멜런 대학교의 Albert Gu와 Flash-Attention을 개발을 주도했던 프린스턴 대학교의 Tri Dao의 공동 연구로 발표된Mamba(Linear-Time Sequence Modeling with Selective State Spaces)라는 혁신적인 아키텍처가 등장했습니다. Mamba는 트랜스포머의 성능은 유지하면서도 계산 복잡도를 선형(O(L))으로 낮추며 AI의 새로운 패러다임을 제시했습니다.

이 글에서는 Mamba가 AI의 미래를 어떻게 바꾸고 있는지, 가장 놀랍고 중요한 4가지 진실을 통해 알아보겠습니다.
첫 번째 진실: Mamba의 진짜 혁신은 ‘속도’가 아닌 ‘선택성’에 있다
Mamba의 등장을 단순히 ‘더 빠른 모델’로만 이해한다면 핵심을 놓치는 것입니다. Mamba의 진정한 혁신은 속도가 아닌, ‘선택적 상태 공간(Selective State Space)’이라는 메커니즘을 통해 구현한 ‘선택성(Selectivity)’에 있습니다.
기존의 상태 공간 모델(SSM)은 입력 데이터와 상관없이 정보 처리 방식이 고정된 ‘선형 시불변(Linear Time-Invariant)’ 시스템이었습니다. 이 때문에 계산은 효율적이었지만, 문맥에 따라 어떤 정보가 더 중요한지 가려내는 능력이 부족했습니다.
반면 Mamba는 입력되는 데이터에 따라 실시간으로 어떤 정보를 기억하고 어떤 정보를 잊을지 스스로 ‘선택’하도록 설계되었습니다. 이는 기억을 업데이트하는 핵심 파라미터(B, C, Δ)들을 입력 토큰 자체에 따라 동적으로 바꾸는 방식으로 구현됩니다. 즉, 문맥의 흐름을 파악하고 중요한 정보에 집중하는 능력을 갖춘 것입니다. 바로 이 ‘선택성’ 덕분에 Mamba는 트랜스포머와 대등한 수준의 복잡한 추론 능력을 확보할 수 있었습니다.
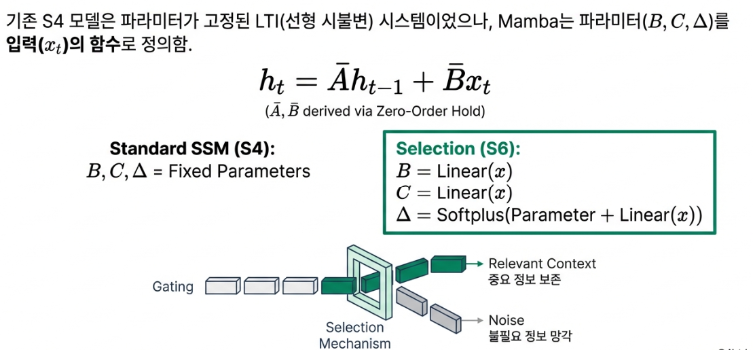
트랜스포머의 attention은 입력 데이터의 모든 부분의 관계를 전부 살피기(기억하기) 때문에 연산량이 입력의 제곱에 비례하지만, Mamba는 중요하지 않다고 판단되는 부분은 버리기 때문에 매우 효율적이기는 하지만, 그런 이유로 세세한 부분까지 동일하게 기억하는 능력은 트랜스포머에 비해 떨어지는 것도 사실이다.
두 번째 진실: 메모리를 잡아먹던 ‘KV 캐시’의 종말
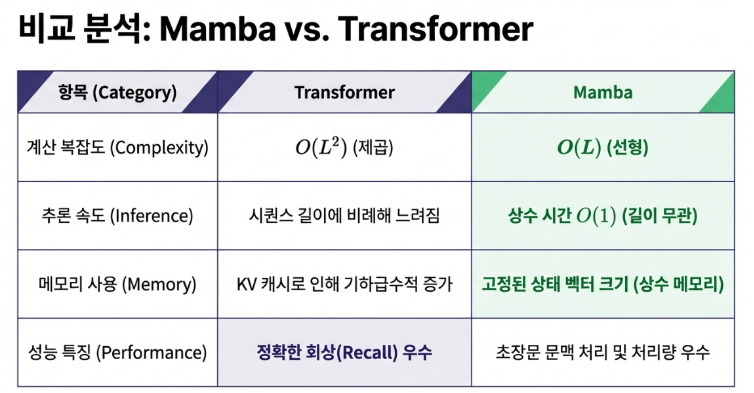
트랜스포머 모델이 문장을 생성(추론)할 때 가장 큰 골칫거리는 ‘KV 캐시’였습니다. 모델은 다음 단어를 예측하기 위해 이전에 등장한 모든 단어의 정보를 키(Key)와 값(Value) 형태로 저장해야 했는데, 문맥이 길어질수록 이 캐시가 GPU 메모리를 기하급수적으로 차지하는 병목 현상이 발생했습니다.
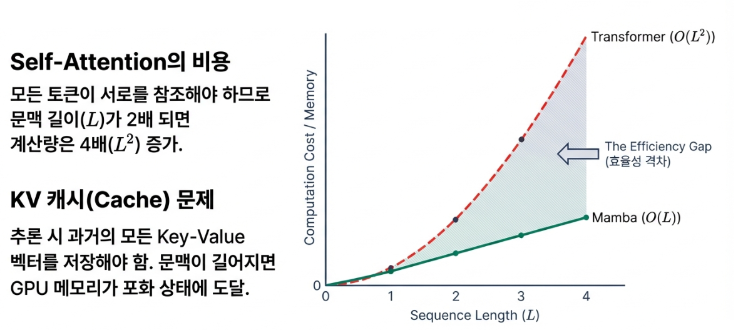
Mamba는 이 문제를 근본적으로 해결합니다. 과거의 모든 정보를 일일이 저장하는 대신, 고정된 크기의 ‘상태 벡터(State Vector)’ 하나에 핵심 정보를 압축하여 저장합니다. 따라서 문맥이 아무리 길어져도 Mamba가 사용하는 메모리 양은 거의 일정하게 유지됩니다.
이 차이가 가져오는 이점은 막대합니다. 동일한 하드웨어에서 훨씬 더 많은 동시 접속자를 처리할 수 있고, 추론 처리량은 최대 5배까지 높아집니다. 이는 AI 서비스의 운영 비용을 극적으로 낮추는 전략적 이점으로 직결될 뿐만 아니라, 스마트폰이나 노트북 같은 저사양 기기에서도 강력한 대규모 모델을 구동할 수 있는 가능성을 열었습니다.
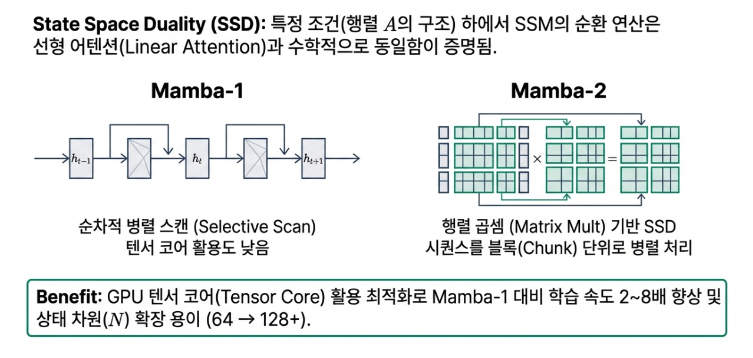
세 번째 진실: 가장 놀라운 반전, Mamba와 어텐션은 사실 같은 원리였다
오랫동안 Mamba와 트랜스포머는 서로 다른 철학을 가진 경쟁 관계로 여겨졌습니다. 하지만 2024년 공개된 Mamba-2(Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality)연구는 이 통념을 완전히 뒤엎었습니다. 바로 ‘상태 공간 이중성(State Space Duality)’ 이라는 놀라운 개념을 통해, 두 아키텍처가 수학적으로 동일한 원리에 기반하고 있음을 증명한 것입니다.
이는 Mamba의 순환적 상태 업데이트 방식과 트랜스포머의 어텐션 방식이 본질적으로 같은 계산을 다른 방식으로 풀어내는 것에 불과하다는 의미입니다. 마치 같은 목적지를 가기 위해 한쪽은 순환 도로를, 다른 한쪽은 모든 지점을 연결하는 직선 도로를 이용하는 것과 같습니다.
이는 트랜스포머와 Mamba가 서로 다른 아키텍처가 아니라, 동일한 선형 변환을 하나는 직접적인 위치 간 상호작용(어텐션)으로, 다른 하나는 재귀적 상태 업데이트(SSM)로 계산하는 것임을 의미한다.
이 발견은 두 아키텍처의 장점을 결합한 하이브리드 모델의 이론적 토대를 마련했으며, AI 하드웨어 설계에도 새로운 방향을 제시하고 있습니다.
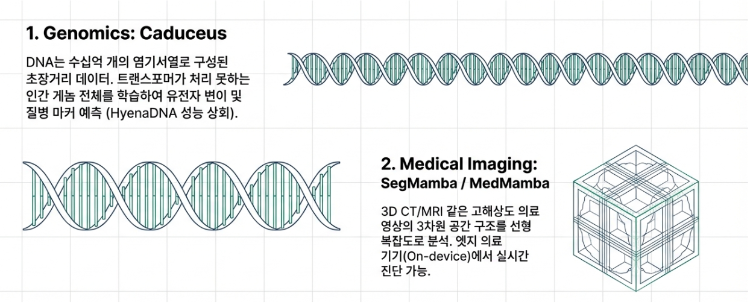
4. 언어를 넘어 유전체와 의료 영상까지, Mamba가 여는 새로운 AI의 지평
Mamba의 선형 스케일링(O(L)) 특성은 단순히 언어 모델의 효율을 높이는 데 그치지 않습니다. 기존 트랜스포머가 메모리 한계로 인해 제대로 다루지 못했던 ‘초장거리 시퀀스 데이터’ 분야에서 진정한 혁신을 일으키고 있습니다.
- 유전체학: Caduceus 같은 Mamba 기반 모델은 30억 염기쌍의 인간 게놈 전체를 단절된 조각이 아닌, 하나의 거대한 책으로 취급합니다. 덕분에 이전에는 계산적으로 불가능했던 미묘하고 장거리적인 유전적 서사를 발견하여 질병과의 연관성을 밝혀내고 있습니다.
- 의료 영상 분석: 수백 장의 슬라이스로 구성된 3D CT나 MRI 같은 방대한 데이터를 효율적으로 처리하여 정밀한 장기 분할 및 진단을 수행합니다. 이는 방대한 데이터를 클라우드로 전송할 필요 없이 병원의 로컬 하드웨어에서 실시간 진단 보조 도구를 구현할 가능성을 열어줍니다.
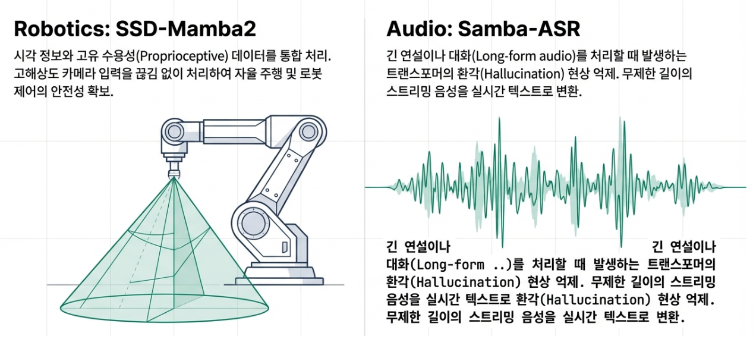
- 오디오 처리: Samba-ASR 모델은 매우 긴 연설이나 회의 녹취록을 실시간으로, 그리고 더 적은 오류로 텍스트로 변환합니다. 기존 모델들이 긴 오디오 처리 시 겪던 속도 저하나 환각 현상을 크게 개선했습니다.
마치며: ‘제곱에서 선형으로’, AI의 새로운 패러다임
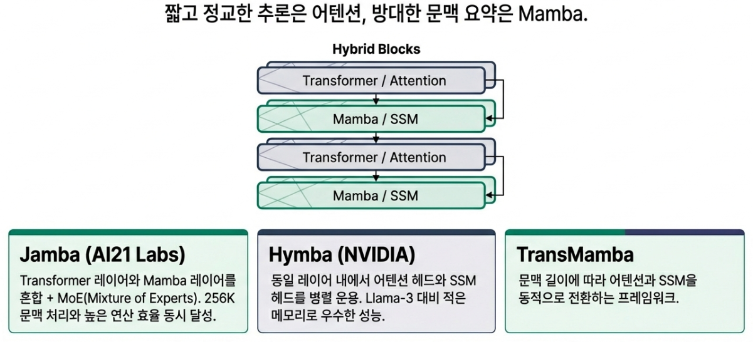
Mamba는 트랜스포머의 단순한 대체재가 아닙니다. 이는 AI 아키텍처의 패러다임이 비효율적인 ‘제곱 복잡도’에서 효율적인 ‘선형 복잡도’로 이동하고 있음을 보여주는 가장 강력한 증거입니다. 물론 Mamba가 모든 면에서 완벽한 것은 아니며, 특정 정보를 정확히 짚어내는 능력 등에서는 여전히 트랜스포머가 강점을 보입니다. 이 때문에 앞으로는 Mamba의 효율성과 트랜스포머의 정교함을 결합한 Jamba나 Hymba와 같은 하이브리드 모델이 AI 시장의 대세가 될 것입니다.

더 나아가, 거대 모델의 막대한 전력 소비가 사회적 문제로 대두되는 시대에 Mamba의 효율성은 중요한 의미를 갖습니다. 추론 단계에서 압도적인 에너지 효율을 보이는 Mamba는 AI 성능을 높이면서도 탄소 발자국을 줄일 수 있는 ‘그린 AI’의 핵심 기술로 주목받고 있습니다. 이는 단순한 기술적 승리를 넘어, 지속 가능한 AI를 향한 중요한 발걸음입니다.

AI가 거대한 데이터 센터를 넘어 우리 손안의 기기 속으로 들어오는 미래에, Mamba의 급진적인 효율성, 즉 단편적인 에너지 비용으로 지능을 제공하는 능력은 과연 ‘스마트함’의 새로운 표준이 될 수 있을까요? AI 패러다임의 거대한 전환은 이미 시작되었습니다.




댓글
운영 정책에 반하는 글은 사전 고지 없이 삭제될 수 있습니다.