
우리는 지금 ‘거거익선(巨巨益善)’의 AI 시대에 살고 있습니다. 수천억 개의 파라미터를 자랑하는 초거대 언어 모델(LLM)들이 연일 인간의 능력을 뛰어넘는 새로운 기록을 갈아치우고 있죠. 하지만 이 화려한 기술을 현업에 상용화하려는 순간, 우리는 차가운 현실과 마주하게 됩니다. 바로 쾌적한 클라우드 위에서만 돌아가는 무거운 인공지능과 스마트폰, 자율주행 드론, 산업용 비전 카메라 같은 엣지(Edge) 기기의 물리적 한계 사이에 존재하는 거대한 틈, 이른바 ‘배포의 계곡(Deployment Chasm)’입니다. 아무리 똑똑한 AI라도 현장에서 실시간으로 작동하지 못한다면 반쪽짜리 혁신에 불과합니다.

시장도 이미 변화하고 있습니다. 모바일 엣지 컴퓨팅 시장은 2024년 16억 5천만 달러에서 2032년 135억 달러 규모로 10배 가까운 폭발적인 성장이 예상됩니다. 데이터가 발생하는 그 현장에서 즉각적인 판단을 내려야 하는 찰나의 저지연성(Low-latency), 민감한 정보 유출을 원천 차단하는 프라이버시, 그리고 끊김 없는 사용자 경험(QoE)은 더 이상 선택이 아닌 생존의 조건이 되었습니다. 이제 거대 모델을 어떻게 경량화하고 빠르게 탑재할 것인가 하는 ‘모델 압축 기술’은 전체 시스템 아키텍처 설계의 승패를 가르는 가장 핵심적인 전략으로 부상했습니다.
이 치열한 경량화 전쟁에서 가장 우아하고 강력한 무기로 떠오른 것이 바로 ‘지식 증류(Knowledge Distillation, KD)’입니다. 특히 작년 초, AI 업계에 신선한 충격을 안겨준 DeepSeek-R1-8B의 사례가 이를 증명합니다. 무려 685B 파라미터를 가진 거대한 ‘교사(Teacher)’ 모델의 통찰력을 8B 크기의 작은 ‘학생(Student)’ 모델에 주입했더니, 오직 압축 효율성 하나만으로 235B급의 대형 모델들을 압도했습니다.
이는 지식 증류가 단순히 파라미터 수를 줄이는 기계적 최적화를 넘어, 거대 모델의 핵심 지능을 정교하게 추출하는 과정임을 시사합니다. 이러한 고효율 압축 기술이 하드웨어 리소스가 제한된 엣지 AI 환경에서도 고성능 모델 구현을 가능하게 하는 실질적인 해결책으로 기대되는 이유입니다.
거인의 뇌를 작은 칩 안에 이식하다: 지식 증류(Knowledge Distillation)
거대 언어 모델(LLM)이 클라우드 환경에서 막대한 전력과 컴퓨팅 자원을 소모한다는 점은 이미 잘 알려진 사실입니다. 하지만 서비스 현장에 적용되는 ‘배포의 계곡’을 넘기 위해 이 거대한 지능을 제한된 리소스의 엣지 기기에 구현하려면 기존과는 다른 최적화 접근이 필요합니다.
단순히 생각해보면, 처음부터 엣지 기기에 맞는 ‘작은 AI 모델’을 만들고 거기에 방대한 데이터를 주입해 학습시키면 될 것 같지만 이는 마치 어린아이에게 수백 권의 전공 서적을 던져주고 독학으로 양자역학 박사 학위를 따라고 강요하는 것과 같습니다. 결국, 학습 효율은 극도로 떨어지고, 스스로 도달할 수 있는 지능의 한계점도 명확하게 그어질 수밖에 없죠.
이러한 한계를 극복하기 위해 도입된 개념이 바로 ‘지식 증류(Knowledge Distillation)’입니다. 원리는 직관적입니다. 수천억 개의 파라미터로 방대한 데이터를 사전에 학습한 거대 모델을 ‘교사 모델(Teacher Model)’로 설정하고, 스마트폰이나 산업용 비전 카메라 등 실제 엣지 환경에 탑재될 경량 모델을 ‘학생 모델(Student Model)’로 정의합니다. 지식 증류는 교사 모델이 학습을 통해 확보한 복잡한 데이터 분포와 통찰을 학생 모델이 효과적으로 흡수할 수 있도록 가이드하는 과정입니다. 즉, 방대한 데이터에서 직접 정답을 찾게 하는 대신, 이미 정답을 알고 있는 교사 모델의 지식을 전이함으로써 소형 모델의 성능을 극대화하는 최적화 전략입니다.

그렇다면 체급 차이가 수백 배에 달하는 상황에서, 교사 모델은 어떤 방식으로 자신의 방대한 지식을 학생 모델에게 전달할까요? 그 핵심은 단순한 ‘정답’ 전수를 넘어 데이터 이면에 숨겨진 ‘확률적 통찰’을 공유하는 데 있습니다.
기존의 일반적인 인공지능 학습은 “이 사진은 고양이다(정답: 100%)”, “이 사진은 강아지다(정답: 100%)”라는 식의 단답형 암기 위주로 진행됩니다. 이를 학계에서는 ‘하드 라벨(Hard Label)’이라고 부릅니다. 하지만 고성능 교사 모델은 정답 외에도 오답일 가능성까지 포함된 미묘한 확률적 판단 근거를 함께 가지고 있습니다.
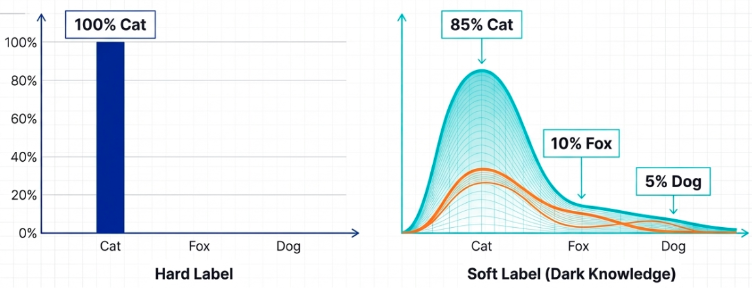
지식 증류에서는 이러한 풍부한 확률 정보를 ‘소프트 라벨(Soft Label)’이라 칭하며 학생 모델에게 전달합니다. 단순히 “고양이가 정답이다”라고 가르치는 것이 아니라, “이 사진은 고양이일 확률이 매우 높지만, 귀의 모양을 보아 강아지일 확률도 일부 존재한다”는 식의 구체적인 판단 분포를 학습시키는 것입니다.
학계에서는 이처럼 정답 뒤에 가려진 아주 섬세한 판단의 결을 가리켜 ‘숨겨진 지식(Dark Knowledge)’이라고 부릅니다. 학생 모델은 단순히 정답을 외우는 것을 넘어 이 숨겨진 지식을 스펀지처럼 흡수합니다. 오답과 정답 사이의 미묘한 관계성, 데이터에 숨겨진 구조적 특징을 단숨에 깨우치게 되는 것이죠. 마치 거장이 붓을 쥐는 미세한 힘과 각도를 제자가 어깨너머로 배우듯, 거대 모델의 ‘직관’을 그대로 물려받게 되는 것입니다.
이러한 지식 전수 과정은 리소스가 제한된 엣지(Edge) 환경에서 강력한 위력을 발휘합니다. 고속 생산 라인에서 찰나의 순간에 불량을 잡아내야 하는 머신 비전 카메라나, 실시간 연산이 필수적인 자율주행 드론을 예로 들 수 있습니다. 이러한 기기들은 수십 기가바이트(GB) 규모의 모델을 구동할 메모리 공간도, 막대한 전력을 감당할 하드웨어 자원도 부족합니다.
하지만 지식 증류를 거친 경량 AI 모델을 탑재하면 상황이 달라집니다. 소형 칩셋 환경에서도 학생 모델은 교사 모델의 판단 체계를 효과적으로 계승했기 때문에, 적은 연산 자원만으로도 복잡한 시각 정보를 빠르게 처리하고 정확한 결과를 도출할 수 있습니다.
결과적으로 지식 증류는 거대 모델의 방대한 파라미터는 클라우드에 남겨두고, 핵심적인 ‘추론 지능’만을 추출하여 엣지 기기에 최적화하는 핵심 공정이라 할 수 있습니다. 최근 DeepSeek의 8B 모델이 체급이 수십 배 큰 모델들을 성능으로 상회할 수 있었던 비결 역시, 이러한 정교한 지식 전수 과정을 통해 모델의 압축 효율을 극대화했기 때문입니다.
다크 지식(Dark Knowledge)의 연금술: 온도 파라미터와 최적화 전략
학생 모델이 교사 모델의 지능을 온전히 흡수하기 위해서는, 정답 확률 뒤에 가려진 미묘한 정보인 ‘다크 지식’을 수면 위로 끌어올려야 합니다. 앞서 살펴본 이 다크 지식이 실제 상용화 환경에서 어떻게 작용하는지, 고속 머신 비전 시스템을 예로 들어 살펴보겠습니다.
제품 표면의 미세 결함을 분석할 때, 거대한 교사 모델은 단순히 “불량”이라고 단정 짓지 않습니다. 대신 “이 패턴은 85% 확률로 스크래치이지만, 형태적 특성을 분석해 보면 미세 먼지(Dust)와도 10%의 유사성을 띤다”는 식의 입체적인 판단 근거를 제공합니다. 불량과 정상 사이의 구조적 관계성을 파악하는 것, 이것이 현장에서 모델의 신뢰성을 결정짓는 다크 노리지의 실체입니다.
그렇다면 이러한 확률적 통찰을 어떻게 수치화하여 학생 모델에 전달할 수 있을까요? 여기서 지식 증류의 핵심 기법인 ‘온도 파라미터(Temperature, T)’가 활용됩니다.
교사 모델의 신경망을 거쳐 나온 원시 데이터(Logits)는 아래의 Softmax 함수를 통해 확률 분포로 변환됩니다.
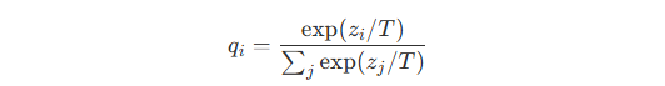
이 공식의 핵심은 분모와 분자에 위치한 T값에 있습니다. 일반적인 AI 모델은 T=1인 상태로 동작하며, 이는 정답의 확률만을 극단적으로 높게 산출합니다. 하지만 T값을 높이게 되면(Soften), 확률 분포가 완만해지면서 상대적으로 낮았던 오답들의 확률값이 수면 위로 드러나기 시작합니다. 이를 통해 학생 모델은 “왜 이 데이터가 오답일 가능성이 있는지”에 대한 미세한 뉘앙스를 학습 가능한 수치 데이터로 받아들이게 됩니다.
왜 이 ‘다크 지식’이 엣지 환경에서 치명적으로 중요할까요?
바로 ‘결정 경계(Decision Boundary)’를 매끄럽게 깎아주기 때문입니다. 조명과 각도가 쉴 새 없이 변하는 제조 라인의 비전 카메라나, 예측 불가능한 변수가 난무하는 실외 자율주행 드론을 떠올려 보십시오. 정답만 기계적으로 외운 학생 모델은 예기치 못한 노이즈가 발생했을 때 결정 경계가 뾰족하고 거칠어 치명적인 오작동을 일으키기 쉽습니다. 하지만 다크 지식을 통해 유연하고 매끄러운 결정 경계를 물려받은 모델은, 처음 보는 낯선 데이터(Unseen Data) 앞에서도 교사 모델처럼 유연하게 대처하는 압도적인 일반화(Generalization) 성능을 발휘하게 됩니다.
용량 매칭(Capacity Matching): 전략가의 딜레마와 해법
그러나 다크 지식을 추출해 냈다고 해서 모든 엣지 상용화가 끝나는 것은 아닙니다. 시스템 아키텍처를 설계하는 전략가로서 반드시 직면하게 되는 거대한 장벽, 바로 ‘용량 매칭(Capacity Matching)’의 문제입니다.
아무리 위대한 교사의 가르침이라도, 학생의 기초 수학 능력이 턱없이 부족하다면 그 지식을 담아낼 수 없습니다. 역설적으로 엣지 디바이스에 탑재하기 위해 학생 모델의 파라미터 크기를 극단적으로 줄이게 되면, 교사 모델이 전달하는 그 방대하고 복잡한 다크 지식을 수용(Capacity)하지 못해 병목 현상이 발생합니다. 반대로 학생 모델의 덩치를 키우면 지식을 잘 받아들이겠지만, 우리가 처음 목표로 했던 ‘저전력, 초경량 엣지 배포’라는 목적 자체가 퇴색되고 맙니다.
이 극단적인 압축 시나리오의 딜레마를 돌파하기 위해 현업의 엔지니어들은 ‘점진적 증류(Progressive Distillation)’라는 해법을 꺼내 들었습니다. 대학교수(수천억 파라미터)가 초등학생(수십억 파라미터)에게 직접 양자역학을 가르치는 대신, 중간 단계에 석박사급 조교(Teaching Assistant) 모델들을 배치하는 것입니다.
거대 모델의 지식을 적당한 크기의 중간 모델로 1차 증류하고, 이 중간 모델이 다시 최종 엣지용 초소형 모델로 2차 증류를 진행합니다. 이 릴레이 방식을 통해 지식의 유실을 최소화하면서도, 스마트폰이나 소형 엣지 프로세서에서도 매끄럽게 구동되는 극한의 압축 효율을 달성할 수 있게 됩니다. 결국 지식 증류는 단순한 모델 경량화 기술을 넘어, 하드웨어의 물리적 한계와 AI 소프트웨어의 무한한 가능성 사이를 정교하게 튜닝하는 고도의 엔지니어링 예술인 셈입니다.

깎고, 증류하고, 압축하라: 하드웨어-소프트웨어의 공동 최적화
앞서 우리는 ‘다크 지식’이라는 소프트웨어적 마법을 통해 거대 모델의 통찰력을 추출하는 방법을 확인했습니다. 하지만 스마트폰, IoT 기기, 소형 로봇 등 엣지(Edge) 환경이라는 냉혹한 전장에서는 알고리즘의 우수성만으로는 결코 살아남을 수 없습니다. 진정한 상용화의 ‘배포의 계곡’을 넘기 위해서는, 시스템 아키텍트의 관점에서 하드웨어의 물리적 특성과 소프트웨어의 지능이 한 몸처럼 맞물려 돌아가는 ‘공동 최적화(Co-design)’가 반드시 수반되어야 합니다.
수십억, 수백억 개의 파라미터를 가진 LLM이나 온디바이스 AI 에이전트를 엣지 기기에 올릴 때 흔히 빠지는 함정이 있습니다. 바로 프로세서의 연산 속도(FLOPs)에만 집착한다는 것입니다. 하지만 실제 기기의 배터리를 무섭게 갉아먹고 전체 시스템의 목을 조르는 진범은 따로 있습니다. 바로 ‘메모리 액세스 비용’입니다. 거대한 AI 모델의 데이터를 메모리에서 연산 장치로 끊임없이 퍼 나르는 과정 자체가, 실제 연산보다 훨씬 더 방대한 에너지를 소모하고 심각한 병목 현상(Bottleneck)을 일으키기 때문입니다.
이 치명적인 메모리 대역폭의 한계를 돌파하기 위해, 지식 증류(Distillation, D)는 단독으로 쓰이지 않고 두 명의 강력한 조력자와 팀을 이룹니다. 바로 가지치기(Pruning, P)와 양자화(Quantization, Q)입니다. 업계에서는 이 세 가지 기술의 결합을 ‘PDQ 전략’이라고 부릅니다.
거대 언어 모델의 신경망에서 비교적 덜 중요한 시냅스(연결)를 과감하게 끊어내어 모델의 뼈대를 앙상하게(희소성, Sparsity) 만드는 것이 ‘가지치기’라면, 그 빈자리에 교사 모델의 다크 지식을 쏟아부어 지능의 손실을 빠르게 복구하는 것이 ‘증류’입니다. 여기에 모델이 사용하는 숫자의 정밀도를 무거운 32비트 실수(FP32)에서 가벼운 8비트 정수(INT8)나 그 이하로 뭉뚱그려 메모리 점유율을 극단적으로 줄여버리는 ‘양자화’가 더해집니다.
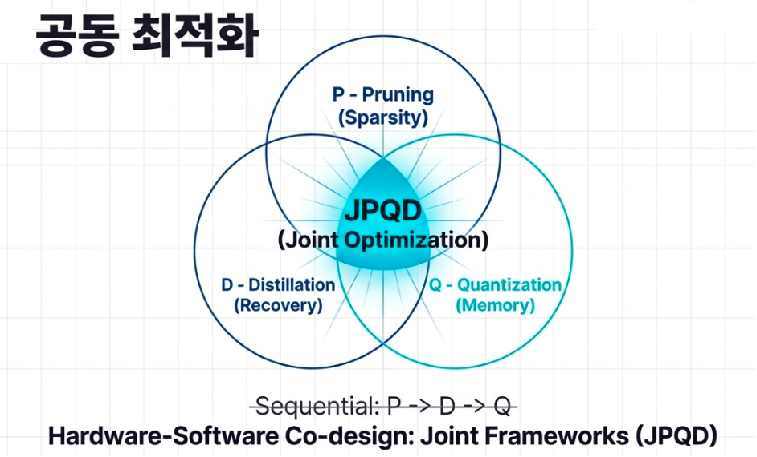
이 최적화의 워크플로우는 전략에 따라 진화하고 있습니다. 과거에는 이를 P -> D -> Q 순서로 차례대로 진행하는 직렬 파이프라인(Sequential Pipeline) 방식이 주를 이루었습니다. 하지만 최근에는 세 가지 과정을 한 솥에 넣고 동시에 끓여내는 JPQD(Joint Pruning, Quantization, and Distillation) 같은 혁신적인 프레임워크가 대세로 떠오르고 있습니다. 파라미터를 깎아내고 압축하는 동시에 증류를 수행함으로써, 모델이 극한의 다이어트를 견뎌내면서도(Quantization-robust) 교사 모델 본연의 문맥 이해력과 추론 능력을 잃지 않도록 꽉 잡아주는 고도의 기술입니다.
더 나아가 이렇게 극도로 정제된 LLM은 최종적으로 안착할 엣지 하드웨어의 ‘실리콘 성향’과 완벽히 동기화되는 하드웨어 캘리브레이션(Calibration)을 거쳐야만 합니다. 하드웨어마다 선호하는 데이터의 형태가 다르기 때문입니다. 예를 들어 Google Coral Edge TPU 같은 하드웨어는 아주 엄격하고 타이트한 INT8 양자화 포맷을 요구하는 반면, NVIDIA의 Jetson 라인업 같은 엣지 플랫폼은 FP16(반정도 실수)과 INT8을 유연하게 섞어 쓰는 혼합 정밀도(Mixed Precision)를 지원하여 아키텍트에게 더 넓은 설계의 자유도를 제공합니다.
결국, PDQ 전략과 하드웨어 캘리브레이션이라는 치열한 튜닝 과정을 거친 LLM은 놀라운 변화를 맞이합니다. 수백 기가바이트의 클라우드 서버에서만 간신히 돌아가던 무거운 언어 모델이, 이제는 인터넷 연결조차 없는 손바닥만 한 스마트폰 내부에서 초당 수십 개의 단어(Tokens Per Second, TPS)를 매끄럽게 뿜어내며 실시간으로 사용자와 대화하는 온디바이스 AI 에이전트로 완벽하게 재탄생하게 되는 것입니다.
연합 증류(Federated Distillation)와 ‘잊힐 권리’
나의 일정, 은밀한 대화 내용, 심지어 금융 및 건강 정보까지 속속들이 알고 있는 AI 에이전트가 더 똑똑해지기 위해 매번 클라우드 서버로 내 개인 데이터를 전송해야 한다면 어떨까요? 아무리 성능이 뛰어난 AI라도 이는 치명적인 보안 위협이자, 기술 상용화 자체를 가로막는 거대한 법적 규제 리스크가 됩니다. 사용자의 데이터를 기기 밖으로 단 한 발짝도 반출하지 않으면서도, 전 세계 수백만 대의 엣지 기기들이 각자의 경험을 공유하며 다 함께 똑똑해질 수는 없을까요?
이 불가능해 보이는 딜레마를 타개하기 위해 등장한 혁신적인 아키텍처가 바로 ‘연합 증류(Federated Distillation, FD)’입니다.

과거 초창기 모델들이 사용했던 연합 학습(Federated Learning)은 각자의 스마트폰에서 학습한 무거운 ‘모델의 가중치(Weights)’ 자체를 중앙 서버로 주고받았습니다. 하지만 파라미터가 수십억 개에 달하는 LLM 시대에 이 방식은 통신망에 엄청난 과부하를 일으킬 뿐만 아니라, 해커가 가중치를 역산하여 원본 개인정보를 복원해 내는 공격에도 취약했습니다.
여기서 앞서 다루었던 지식 증류의 마법이 또 다른 형태로 빛을 발합니다. RIFLE(Robust Information For Federated Learning) 프레임워크와 같은 최신 연합 증류 기술은, 무겁고 위험한 가중치 대신 오직 ‘소프트 로짓(Soft Logits)’만을 추출하여 암호화된 상태로 중앙 서버와 교환합니다.
쉽게 비유하자면, 수백만 명의 학생(엣지 기기)들이 각자의 방에서 가장 내밀한 일기장(개인 원본 데이터)을 펴놓고 공부를 합니다. 그리고 선생님(중앙 서버)에게 일기장을 통째로 제출하는 대신, 그 일기장을 읽고 느낀 ‘확률적 뉘앙스와 깨달음의 요약본(소프트 로짓)’만을 익명으로 제출하는 것입니다. 중앙의 거대한 교사 모델은 이 수백만 개의 깨달음을 모아 거대한 글로벌 지능으로 통합한 뒤, 다시 정제된 지식의 형태로 학생들에게 내려보냅니다. 통신 비용은 극단적으로 낮아지고, 프라이버시 노출 위험은 원천 차단되는 가장 우아하고 안전한 통신 아키텍처의 완성입니다.
‘연합 잊기(ZeroFU)’와 AI 시대의 잊힐 권리
하지만 여기서 끝이 아닙니다. 진정한 데이터 주권은 ‘보호’를 넘어 사용자가 원할 때 언제든 자신의 흔적을 지울 수 있는 ‘잊힐 권리(Right to be Forgotten)’까지 완벽하게 보장해야 합니다. 만약 특정 사용자가 “내 데이터를 기반으로 학습된 지능의 흔적을 당장 삭제해 줘!”라고 요구한다면 어떻게 될까요?
과거에는 그 한 명의 기여분을 지우기 위해 거대한 AI 모델 전체를 폐기하고 처음부터 다시 학습시켜야 하는, 천문학적인 비용의 악몽(Retraining)을 겪어야만 했습니다. 이를 해결하기 위해 최신 엣지 아키텍처 전략에는 ‘연합 잊기(Federated Unlearning, ZeroFU)’라는 고도의 기술이 전격 도입되고 있습니다.
이는 전체 모델을 부수지 않고도, 특정 클라이언트가 기여한 지능의 파편만을 찾아내어 마치 정밀한 외과 수술처럼 지능적으로 도려내는(Unlearning) 기술입니다. 모델의 전체적인 성능 저하 없이 특정 개인의 정보만을 효과적으로 소거함으로써, 기업은 천문학적인 재학습 비용을 방어하고 유럽의 GDPR 같은 강력한 개인정보 보호 규제에 완벽하게 대응하는 전략적 무기를 얻게 됩니다.
결국 엣지 디바이스로 향하는 지식 증류는 단순히 모델의 크기를 욱여넣는 기술을 넘어, 사용자의 데이터를 철저히 보호하고 통제권을 온전히 돌려주는 ‘안전하고 윤리적인 온디바이스 AI 생태계’를 구축하는 가장 든든한 방패 역할을 수행하고 있습니다.
스마트폰에서 산업/관제용 VLM까지, 엣지 AI의 최전선
다크 지식을 품고 하드웨어와 완벽하게 동기화된 가벼운 AI 모델들은 이제 클라우드의 그늘을 벗어나 현실 세계의 가장 역동적인 전장으로 파고들고 있습니다. 가장 먼저 체감할 수 있는 변화는 우리 손안의 스마트폰과 웨어러블 기기에서 시작되었습니다. 인터넷 연결이 완전히 끊긴 비행기 안에서도 실시간으로 복잡한 문맥을 번역하고, 사용자의 은밀한 개인정보를 서버로 보내지 않고도 스케줄을 관리하는 온디바이스(On-device) AI 에이전트의 탄생은 앞서 다룬 연합 증류와 압축 기술이 없었다면 불가능했을 마법입니다.
또한, 예측 불가능한 변수로 가득한 로보틱스와 자율주행 분야에서도 엣지 AI는 생존의 핵심입니다. 시속 수십 킬로미터로 달리는 드론이나 공장을 누비는 물류 로봇(AMR)이 장애물을 마주했을 때, 클라우드 서버에 “이것이 무엇인지” 묻고 답을 기다릴 찰나의 여유는 없습니다. 기기 내부에서 스스로 판단하고 즉각적인 회피 기동을 수행하는 실시간 추론(Low-latency) 능력은 엣지에서 극한으로 튜닝된 경량화 모델만이 제공할 수 있는 특권입니다.
최적화의 정점: 생성형 AI 관제 ‘OdinAI’를 엣지로 끌어내린 라온피플의 ‘AI Box’
엣지 AI 최적화 기술의 진가는 극도의 정확성과 실시간성이 요구되는 ‘현장 관제’에서 명확히 드러납니다. 16년간 다져온 머신 비전의 내공을 담아낸 라온피플의 ‘AI Box’는, 이 까다로운 엣지 아키텍처의 가능성을 현실로 증명해 낸 우아한 사례입니다.
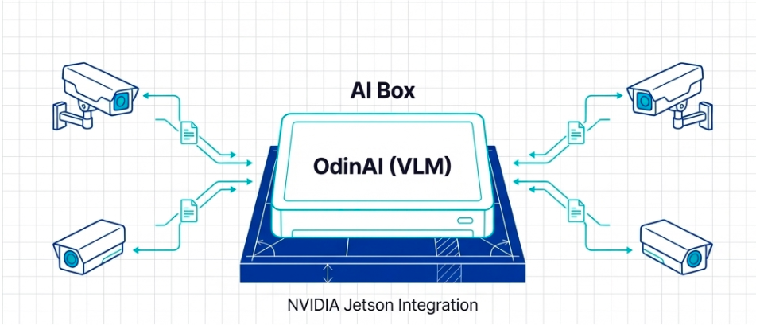
그 중심에는 생성형 AI 관제 솔루션인 ‘OdinAI(오딘AI)’가 있습니다. 산업 현장과 교차로의 수많은 카메라가 쏟아내는 방대한 시각 정보를 인간의 언어로 즉각 해석해 내려면, 이미지와 텍스트를 동시에 이해하는 시각-언어 모델(VLM)이 필수적입니다. 문제는 클라우드의 거대한 GPU 클러스터에서나 돌아갈 법한 이 무거운 VLM을 어떻게 현장의 작은 엣지 생태계에 이식하느냐였습니다.
라온피플은 치열한 튜닝 과정을 통해 이 거대한 지능을 엔비디아 젯슨(NVIDIA Jetson) 기반의 제한된 하드웨어 위에 온전히 독립시켰습니다. 주목할 점은 단순히 모델의 크기를 줄이는 데 그치지 않고, 단일 엣지 디바이스 하나로 무려 4채널의 고해상도 비전 데이터를 동시에(Concurrent) 실시간 분석하는 성능을 확보했다는 것입니다.
이는 앞서 다루었던 시스템 아키텍트 관점의 ‘하드웨어-소프트웨어 공동 최적화(Co-design)’가 현장에서 어떻게 작동하는지 보여주는 훌륭한 장면입니다. 모델의 불필요한 뼈대를 정교하게 깎아내고(가지치기), 젯슨 플랫폼의 혼합 정밀도 특성에 맞춰 데이터를 압축하며(양자화), 교사 모델의 다크 지식을 고스란히 이식하는(증류) 고도의 엔지니어링이 뒷받침되었기에 가능한 결과입니다.
이러한 전략적 접근을 통해 라온피플은 메모리 대역폭의 한계를 극복하고, 지능형 교통 시스템(ITS)과 스마트 관제 현장에 ‘클라우드가 필요 없는 생성형 AI(OdinAI)’를 성공적으로 안착시켰습니다. 거대한 지능을 작고 단단한 칩셋 안에 담아내어 가장 복잡한 현장의 문제를 타개하는 것. 이것이 우리가 ‘배포의 계곡’을 건너 마주하게 될 엣지 AI의 진정한 가치일 것입니다.
압축을 넘어 ‘행동하는 지능’으로: 에이전틱 AI와 엣지의 미래
인공지능 혁신의 최전선은 이제 거대한 클라우드에만 머물지 않고, 작고 빠른 현실 세계의 엣지(Edge)로 그 영토를 급격히 확장하고 있습니다. 인터넷 연결 없이 스마트폰 내부에서 텍스트를 실시간으로 분석해 내는 Llama 3.2(1B/3B) 초경량 모델이나, 거대 모델의 강력한 추론 능력을 모바일급 칩셋에 고스란히 이식해 낸 DeepSeek-R1-Distill-1.5B 같은 최신 성과들은 이 위대한 여정의 훌륭한 이정표입니다.
하지만 지식 증류(Knowledge Distillation)와 아키텍처 최적화의 진짜 종착지는 단순한 모델 압축이 아닙니다. 다크 지식의 정교한 추출, 하드웨어-소프트웨어 공동 최적화(PDQ), 프라이버시를 지키는 연합 증류, 그리고 ESG 기반의 비용 절감까지. 이 모든 기술적 궤적은 결국 수동적인 엣지 단말기를 스스로 인지하고 행동하는 ‘모바일 에이전틱 AI(Mobile Agentic AI)’로 진화시키는 핵심 촉매제입니다. 엣지 환경에서의 완전한 범용 지능은 아직 조심스러운 목표일지 모르나, 그를 향한 견고한 토대는 서서히 완성되어가고 있습니다.
라온피플의 OdinAI를 장착한 AI Box가 이를 완벽히 증명합니다. 무거운 시각-언어 모델(VLM)마저 혹독한 최적화를 뚫고 엣지 칩셋에 안착하여 실시간 관제를 수행하는 지금, 초거대 AI와 엣지 기기 사이를 가로막던 ‘배포의 계곡(Deployment Chasm)’은 허물어져가고 있습니다.
이제 지식 증류는 거대 모델의 통찰을 추출해 세상 모든 곳에 배치하는 거대한 ‘지능 전이 프레임워크’로 작동하고 있습니다. 산업/관제 현장의 카메라와 주머니 속 기기가 거대 AI의 지능을 온전히 소유하게 될 때, 우리의 비즈니스와 일상은 어떻게 바뀔까요? 혁신의 최전선에 선 아키텍트로서, 우리는 이미 그 위대한 경계를 넘어서고 있습니다.



