
DeepSeek는 어떻게 ‘기억’과 ‘추론’을 분리해 냈는가? (Engram 리뷰)
2026년의 포문을 여는 1월과 2월, 그야말로 세상을 뒤흔드는 AI 기술들이 하루가 멀다 하고 쏟아지고 있습니다. 그 거대한 파도 속에서도 지난 1월 DeepSeek가 발표한 ‘엔그램(Engram)’ 논문은 단순한 성능 지표 갱신을 넘어, AI 업계에 근본적인 화두를 던졌습니다. 바로 우리가 너무나 당연하게 받아들이고 있던, 어쩌면 수많은 전문가들조차 간과해 온 트랜스포머(Transformer) 아키텍처의 태생적 한계를 정면으로 겨냥했기 때문입니다.
지금까지의 대규모 언어 모델(LLM)들은 복잡한 논리적 추론을 할 때나, 고정된 단순한 정적 지식을 떠올릴 때나 동일하게 무거운 신경망 연산을 수행해 왔습니다. 즉, 단순한 ‘기억(Memory)’을 매번 재구성하기 위해 막대한 GPU 자원과 컴퓨팅 파워를 낭비하는 치명적인 비효율을 안고 있었던 셈이죠.
DeepSeek의 Engram은 기존 아키텍처의 비효율을 해결하기 위해 ‘조건부 메모리(Conditional Memory)’라는 혁신적인 구조를 도입했습니다. 쉽게 말해, ‘단순 기억’과 ‘복잡한 사고’를 처리하는 영역을 완벽하게 분리하여 연산 효율을 극대화한 것입니다.
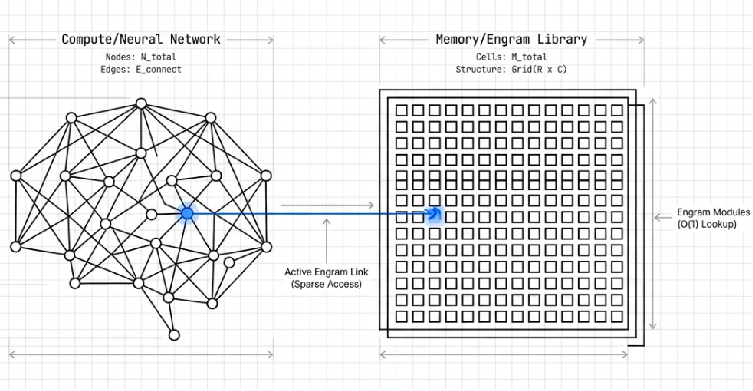
그 중심에는 사전에서 단어를 찾듯 정적인 지식을 즉시 꺼내 쓰는 O(1) 해시 조회(Hash Lookup) 방식이 있습니다. 여기서 O(1) 해시 조회란, 저장된 데이터가 아무리 방대해져도 검색 속도가 느려지지 않고 ‘단 한 번’의 확인만으로 원하는 정보를 찾는 방식을 뜻합니다. 마치 거대한 물류 창고에서 물건을 찾을 때 모든 상자를 하나하나 뒤지는 대신, 바코드를 찍자마자 물건의 정확한 위치 좌표가 나와 즉시 꺼내오는 것과 같은 이치입니다.
Engram은 바로 이 원리를 적용해 ‘프랑스의 수도는 파리’와 같은 고정된 지식을 무거운 연산 없이 즉각적으로 불러옵니다. 이렇게 단순 암기라는 무거운 짐을 전용 모듈에 덜어낸 덕분에, 핵심 신경망(MoE)은 오직 고도의 논리적 추론과 사고에만 에너지를 쏟을 수 있게 되었습니다. 결과적으로 모델은 절약된 연산 자원을 바탕으로 훨씬 더 깊고 복잡한 문제 해결에 온전히 집중할 수 있게 된 것입니다.
작년 한 해, 압도적인 효율과 아키텍처 혁신으로 전 세계를 경악하게 만들었던 DeepSeek의 행보를 떠올려 보십시오. 이 혁신적인 Engram 아키텍처가 곧 발표될 것으로 예상되는 DeepSeek V4의 근간이 된다면, 무식한 연산량(Compute) 늘리기 경쟁에 매몰되어 있던 AI 시장에 또 한 번 엄청난 충격을 안겨줄 것이 자명합니다. 맹목적인 스케일링(Scaling)의 시대가 저물고, 구조적 혁신의 시대가 본격적으로 열리고 있습니다.
본 글에서는 DeepSeek Engram이 트랜스포머의 오랜 비효율을 어떻게 걷어냈는지, O(1) 조회의 기술적 원리는 무엇인지, 그리고 이것이 향후 AI 패권 경쟁에 어떤 의미를 가지는지 심도 있게 파헤쳐 보겠습니다.

트랜스포머의 치명적 모순: ‘기억’과 ‘추론’을 구별하지 못하는 뇌
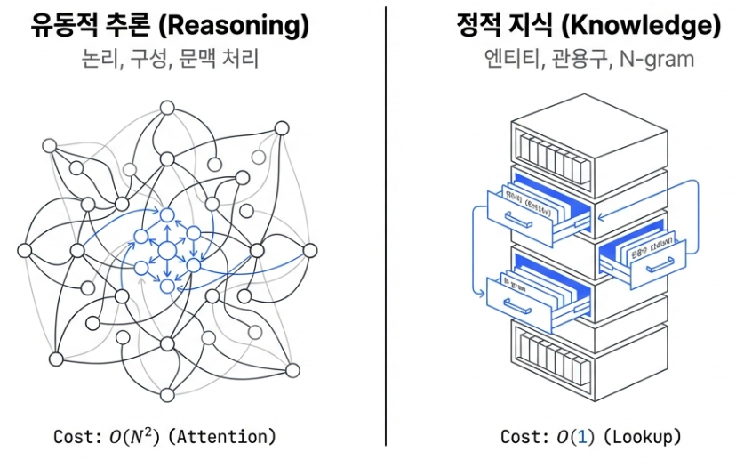
우리가 흔히 사용하는 대규모 언어 모델(LLM)은 놀라운 성능을 보여주지만, 내부를 들여다보면 심각한 구조적 모순을 안고 있습니다. 연구팀은 그 근본적인 원인을 언어의 본질인 ‘언어적 이중성(Linguistic Duality)’에서 찾습니다. 언어에는 복잡한 논리적 인과관계를 따지는 ‘동적 추론(Compositional Reasoning)’과, 이미 고정된 사실을 단순히 떠올리는 ‘정적 패턴(Knowledge Retrieval)’이 공존한다는 것입니다.
하지만 기존의 트랜스포머는 이 두 가지를 전혀 구분하지 않습니다. “프랑스의 수도는 어디인가?” 같은 단순한 사실을 꺼낼 때나, “다이애나 왕세자비(Diana, Princess of Wales)”와 같은 고유 명사를 처리할 때조차 복잡한 수학 증명을 할 때와 동일하게 초기 레이어의 수많은 주의 집중(Attention) 뉴런을 소모합니다. 논문의 지적처럼, “표준 트랜스포머는 고유한 지식 검색(Primitive) 기능이 없기 때문에, 단순한 룩업 테이블로 처리할 수 있는 사소한 작업마저 값비싼 연산을 통해 억지로 시뮬레이션하며 소중한 자원을 낭비”하고 있는 것입니다.
제조 라인이나 산업용 CAD 환경에 AI를 도입할 때 가장 큰 걸림돌이 ‘무거운 연산량’이었던 것을 떠올려 보십시오. 고해상도 이미지를 실시간으로 분석하는 머신비전 시스템에서 극도로 최적화된 YOLO 아키텍처가 필수적이듯, 제한된 컴퓨팅 자원 안에서는 ‘가벼운 처리’와 ‘무거운 추론’을 철저히 분리하는 것이 공학의 기본입니다.
기존 트랜스포머가 이러한 기본을 무시한 채 낭비를 거듭할 때, DeepSeek은 바로 이 지점에 현미경을 들이댔습니다. 구글의 Titans 아키텍처가 추론 시점에 동적으로 학습하는 ‘신경 메모리(Neural Memory)’를 통해 동적인 학습을 강조했다면, DeepSeek의 Engram은 정반대로 거대한 ‘정적 도서관’을 구축하는 방식을 택했습니다. 단순한 정적인 사실을 재구축하는 데 쓰이던 불필요한 연산을 원천 차단해 버린 것입니다.
조건부 메모리(Conditional Memory): 희소성(Sparsity)의 새로운 축
DeepSeek이 꺼내든 ‘조건부 메모리(Conditional Memory)’는 기존 아키텍처의 한계를 완벽하게 깨부수는 핵심 아이디어입니다. 기존의 전문가 혼합(MoE, Mixture-of-Experts) 모델이 ‘어떤 전문가(연산 유닛)를 활성화할 것인가’를 결정하며 연산의 낭비를 줄이는 데 집중했다면, Engram은 한 발 더 나아가 ‘어떤 지식을 바로 꺼내 쓸 것인가’에 집중하여 메모리와 탐색 과정의 낭비마저 없애버렸습니다.
이를 기술적으로 요약하자면, ‘희소 연산(Sparse Computation)’과 ‘희소 조회(Sparse Lookup)’의 완벽한 분업이라고 할 수 있습니다.
- Sparse Computation (MoE): Thinking의 최적화
입력된 문맥에 맞춰 필요한 전문가 신경망만 선택적으로 활성화하여 연산 효율을 극대화합니다. 즉, 모델이 고도로 논리적인 ‘생각’을 전개하는 과정을 담당합니다. - Sparse Lookup (Engram): Knowing의 최적화
입력 문맥을 키(Key)로 삼아O(1) 복잡도의 해시 검색을 통해 지식을 직접 인출합니다. 즉, 모델이 이미 ‘알고 있는 팩트’를 즉각적으로 불러오는 과정을 담당합니다.
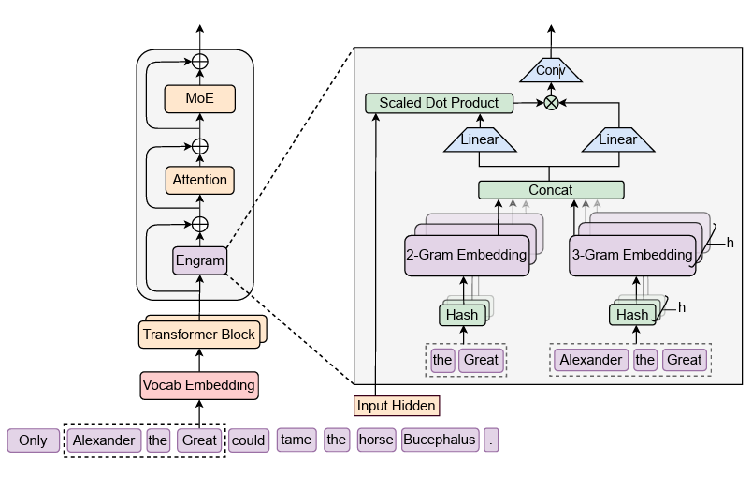
이러한 혁신이 가능했던 핵심은 지식을 저장하는 방식의 근본적인 변화에 있습니다. Engram은 자주 등장하는 정적인 지식을 복잡한 신경망(모델 가중치) 안에 무겁게 새겨 넣는 낡은 방식을 과감히 버렸습니다. 대신, 고전적인 자연어 처리 기법인 N-gram의 개념을 현대적으로 재해석하여, 모델의 뇌 외부에 거대한 ‘지식 창고(임베딩 테이블)’를 구축했습니다.
이제 모델은 뻔한 내용을 떠올리기 위해 복잡한 신경망 연산을 돌리며 에너지를 낭비하지 않습니다. ‘생각해야 할 것’과 ‘이미 알고 있는 것’을 구조적으로 완벽히 분리함으로써, 외부 창고에서 즉각적으로 지식을 꺼내 오고 한정된 하드웨어 자원을 가장 최적화된 형태로 분배할 수 있게 된 것입니다.
Engram의 3대 핵심 메커니즘: O(1) 조회의 완성
Engram은 구조적 낭비를 막기 위해, 고도의 ‘논리적 추론’은 기존의 핵심 신경망(MoE)에 맡기고, 변하지 않는 ‘단순 지식’은 외부 창고에서 즉각적으로 꺼내오는 ‘조건부 메모리(Conditional Memory)’ 구조를 씁니다.
그렇다면 이 혁신적인 메모리 시스템은 과연 어떻게 톱니바퀴처럼 맞물려 돌아갈까요? 완벽한 지식 검색을 가능하게 만드는 Engram의 3대 핵심 메커니즘을 알기 쉽게 풀어드립니다.
흩어진 의미를 하나로 묶다: 토크나이저 압축 (Tokenizer Compression)
단어의 모든 형태를 있는 그대로 메모리에 저장하면 용량이 기하급수적으로 늘어납니다. AI가 글을 읽을 때 “Apple”, “apple”, ” apple(공백 포함)” 등은 모양은 조금씩 다르지만 결국 의미는 같습니다. Engram은 메모리 창고의 밀도를 극대화하기 위해, 대소문자를 통일하고 불필요한 공백과 기호를 제거하는 일종의 ‘정리 정돈(전처리)’ 과정을 거칩니다. 의미가 동일한 단어들을 하나의 ‘표준 고유 번호(Canonical ID)’로 압축해 묶어버리는 것이죠. 이 과정을 통해 쓸데없는 중복 데이터(유효 어휘 집합)가 약 23%나 줄어들며, 귀중한 메모리 공간의 낭비를 원천적으로 차단합니다.
주소 겹침을 막는 교차 검증: 멀티 헤드 해싱을 통한 O(1) 조회 (Multi-Head Hashing)
깔끔하게 정리된 단어들은 다시 의미 있는 묶음(N-gram)으로 연결됩니다. Engram은 이 묶음들을 복잡한 연산으로 찾아 헤매는 대신, 거대한 메모리 테이블의 ‘정확한 주소 값’으로 즉시 변환하는 마법(해시 함수)을 부립니다. 덕분에 데이터 탐색에 걸리는 시간은 문맥의 길이에 상관없이 항상 일정한 O(1)의 즉각적인 조회 속도를 보장합니다.
하지만 여기서 문제가 하나 발생할 수 있습니다. 완전히 다른 단어가 우연히 같은 주소로 배정되는 ‘해시 충돌(Hash Collision)’이라는 배송 사고입니다. Engram은 이를 막기 위해 여러 개의 독립적인 주소 탐색기(멀티 헤드)를 동시에 투입합니다. 만약 한 탐색기가 충돌로 인해 엉뚱한 쓰레기 값을 가져오더라도, 나머지 탐색기들이 찾아온 올바른 정보들이 이를 덮어쓰며 오류를 상쇄시키는 강력하고 튼튼한 안전망을 확보했습니다.
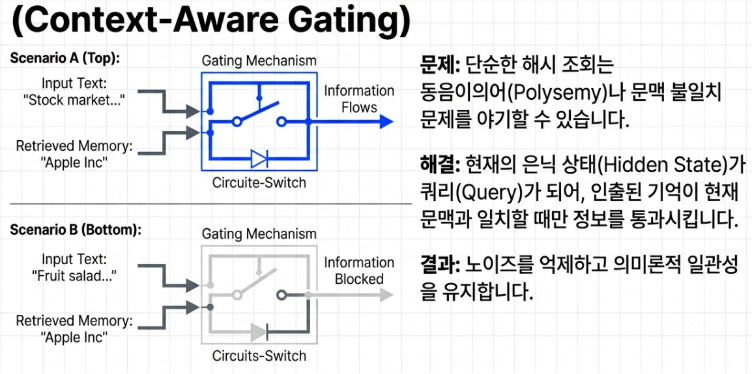
똑똑한 문지기의 철통 방어: 문맥 인식 게이팅 (Context-aware Gating)
해시를 통해 지식을 빛의 속도로 찾아왔다고 해서 무턱대고 AI의 메인 사고에 섞어버릴 수는 없습니다. 방금 꺼내온 정적 메모리 ‘Apple’이 맛있는 과일인지, 아이폰을 만드는 테크 기업인지 현재 대화의 흐름(문맥)을 파악해야 하니까요.
이를 위해 Engram은 일종의 ‘똑똑한 문지기(Gate)’를 세워둡니다. 이 문지기는 모델이 지금까지 대화하며 파악해 둔 ‘전체적인 흐름(Hidden state)’을 기준 삼아, 방금 가져온 지식이 지금 상황에 꼭 필요한 정보인지 실시간으로 점수를 매깁니다. 이 점수는 0점과 1점 사이로 계산되는데, 만약 현재 문맥과 상충하는 엉뚱한 정보(노이즈)라면 점수가 0점에 가깝게 떨어집니다. 결과적으로 쓸모없는 정보는 AI의 핵심 연산에 융합되기 전에 안전하게 억제되고 차단됩니다.
이 정교한 시스템 덕분에, 트랜스포머 본연의 메인 연산 엔진(Attention 및 MoE)은 기계적 암기라는 지루한 노동에서 완전히 해방되었습니다. 이제 모델은 더 깊은 논리적 추론과 거시적인 문맥을 파악하는 데 귀중한 연산력을 100% 쏟아부을 수 있게 되었습니다. 이는 단순히 효율을 높인 것을 넘어, 초거대 AI가 안고 있던 자원 낭비 문제를 근본적으로 뜯어고친 진정한 아키텍처의 패러다임 전환이라 평가할 수 있습니다.
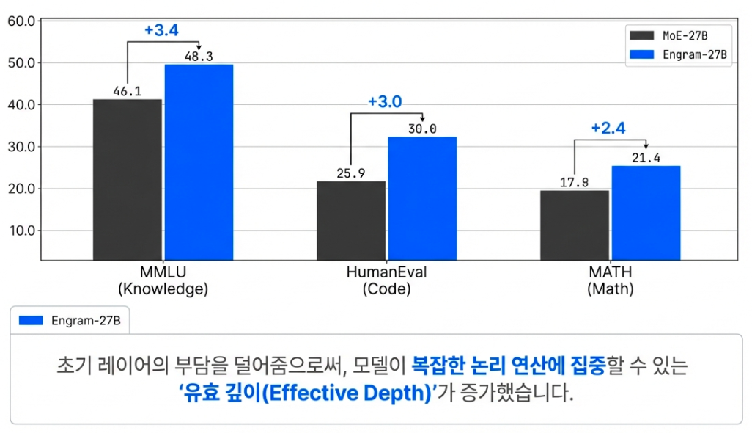
추론 능력의 역설적 향상 — “기억을 비웠더니 머리가 좋아졌다”
Engram은 단순히 지식을 저장하는 데 그치지 않고, 모델의 ‘유효 깊이(Effective Depth)’를 심화시킵니다. DeepSeek는 LogitLens와 KL Divergence 분석을 통해 Engram이 모델 내부의 잔차 스트림(Residual Stream) 수렴을 가속화한다는 사실을 밝혀냈습니다.
초반 레이어에서 수행되던 정적 지식 복원 작업을 Engram이 전담하자, 상위 레이어들은 복잡한 추론에 온전히 집중할 수 있게 되었습니다.
“Engram relieves the backbone’s early layers from static reconstruction,
effectively deepening the network for complex reasoning.”
Architecture Note: 주요 성능 향상 지표
- 지식 성능: MMLU +3.4, CMMLU +4.0
- 추론 성능: BBH +5.0, ARC-Challenge +3.7
- 수학/코드: MATH +2.4, HumanEval +3.0
이러한 결과는 Engram이 지식 보조 도구를 넘어, 모델이 더 고차원적인 사고를 할 수 있도록 뇌의 ‘가용 에너지’를 확보해주는 혁신임을 보여줍니다.
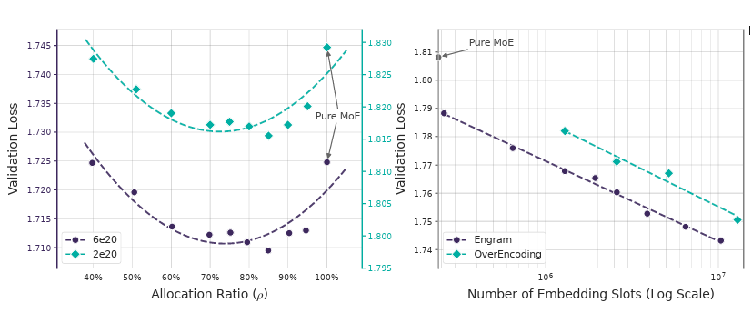
최적의 균형을 찾다: U자형 스케일링 법칙
DeepSeek 연구진이 이 논문에서 증명한 또 하나의 흥미로운 사실은 ‘U자형 스케일링 법칙(U-shaped Scaling Law)’입니다. 쉽게 말해, 한정된 모델의 두뇌 용량을 ‘기억력(Engram)’과 ‘사고력(MoE 연산)’에 각각 얼마씩 투자해야 가장 똑똑한 AI가 될까?에 대한 해답을 찾은 것입니다.
수많은 실험 끝에 도출된 결과는 명확했습니다. 전체 용량의 약 20%를 Engram(단순 기억)에, 나머지 80%를 MoE(복잡한 추론)에 할당했을 때 모델의 성능이 가장 극대화되었습니다.
만약 메모리에 너무 의존하게 되면 모델이 스스로 복잡한 논리를 전개할 ‘사고력’을 잃어버립니다. 반대로 연산에만 모든 자원을 쏟아부으면, 뻔한 사실을 매번 처음부터 다시 생각하느라 불필요한 에너지를 낭비하게 되죠. 이 8 대 2라는 황금 비율 덕분에, 모델의 초기 레이어들은 단순 암기 작업에서 완전히 해방되어 훨씬 더 깊고 날카로운 추론에 집중할 수 있게 되었습니다.
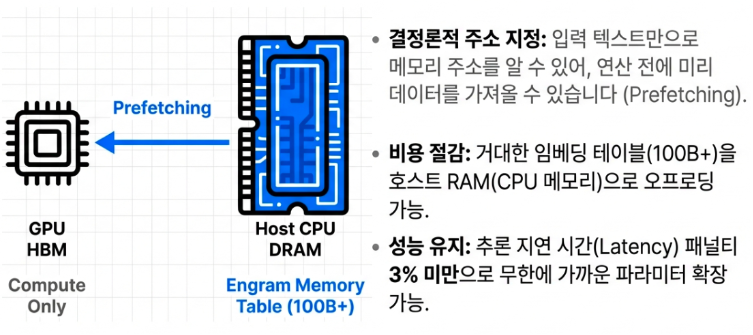
시스템 레벨의 혁신: GPU 메모리(HBM)의 해방
아마도 현장의 엔지니어와 비즈니스 리더들 입장에서 Engram이 가장 반가운 이유는 바로 하드웨어의 한계, 즉 비싸고 좁은 GPU 메모리(HBM)의 굴레를 벗어났다는 점일 것입니다.
앞서 설명한 Engram의 거대한 지식 사전(임베딩 테이블)은 복잡한 신경망 연산이 필요 없는 단순하고 결정론적인 해시(Hash) 구조를 띠고 있습니다. 따라서 굳이 품귀 현상을 빚고 있는 초고가 GPU의 VRAM에 이 방대한 사전을 꾸역꾸역 올려둘 필요가 없습니다.
대신, 가격이 훨씬 저렴하고 용량 확장이 자유로운 일반 서버의 메인 메모리(CPU DRAM 등)에 지식 사전을 보관합니다. 정적인 지식을 필요할 때만 즉시 매칭해서 가져오기 때문에, 값싼 메모리에 저장해 두어도 속도 지연(Latency)이 거의 발생하지 않기 때문입니다. 이는 무조건 더 많은 GPU를 사들여야만 했던 무한 장비 경쟁 시대에, 스마트한 아키텍처 설계라는 완전히 새로운 돌파구를 열어준 엄청난 혁신입니다.
마치며: 다가올 V4와 AI 아키텍처의 새로운 표준
최근 AI 업계는 기존 아키텍처의 한계를 극복하기 위해 Mamba 같은 상태 공간 모델(SSM), 복잡한 위상 구조를 처리하는 GNN, 그리고 멀티모달 환경의 VLM 등을 앞다투어 쏟아내고 있습니다. 이 모든 혁신의 밑바탕에는 “더 이상 무식한 연산량(Compute)만으로는 미래가 없다”는 절박함이 깔려 있습니다.
DeepSeek Engram은 바로 이 지점에서, LLM이 ‘생각하는 법(연산)’과 ‘기억하는 법(메모리)’을 구조적으로 완전히 분리해야 한다는 새로운 설계 철학의 승리를 보여줍니다. 단순한 기술적 잔기술(Trick)이 아니라, 하드웨어의 물리적 한계인 ‘메모리 장벽(Memory Wall)’을 아키텍처의 지혜로 극복하고 신경망의 인지적 노동을 재배치한 혁명적인 진화입니다. 트랜스포머 생태계에 늘 빠져 있던 ‘순수 메모리’라는 마지막 퍼즐 조각을 완벽하게 맞춰 넣은 것이죠.
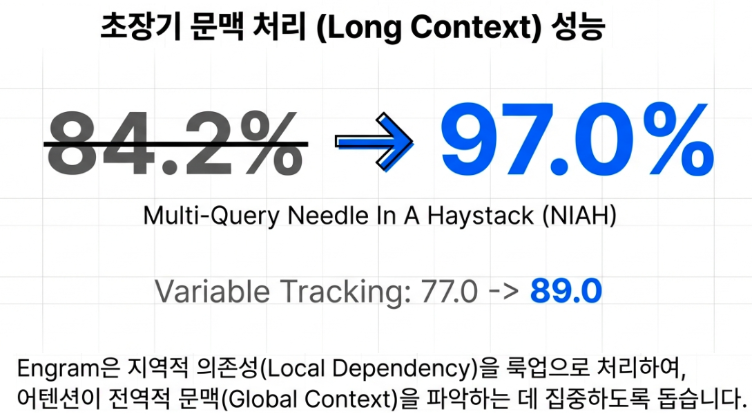
이러한 Engram 기술은 차세대 DeepSeek V4에서 100만 토큰 이상의 거대한 컨텍스트 창(Context Window)을 지원하는 핵심 동력이 될 것입니다. 단순 암기나 로컬 의존성 문제를 즉각적인 해시 조회(Lookup)로 해결함으로써, 초장문 문맥에서도 핵심 정보를 절대 놓치지 않는 고밀도 검색 능력을 제공하게 됩니다. 향후 V4가 가져올 구체적인 산업적 변화는 다음과 같습니다.
- 고밀도 정보 검색(High-Density Retrieval)
여러 개의 숨겨진 바늘을 동시에 찾는 Multi-Query NIAH(Needle In A Haystack) 성능을 바탕으로, 방대한 문서 속 수십 개의 핵심 정보를 동시에 정확히 인출해 냅니다. - 초거대 코드 베이스 분석
수만 줄에 달하는 복잡한 코드 구조와 식별자 패턴을 O(1) 속도로 인출하여, 개발 및 디버깅 과정의 추론 오류를 최소화합니다. 이것은 향후 Claude나 Gemini 등 서구 LLM 업체들과의 대결에서 우위를 점할 수 있는 좋은 포인트로 보입니다. - 무손실 장기 기억
컨텍스트 길이가 길어질수록 앞의 내용을 잊어버리는 고질적인 ‘기억의 희석’ 문제를, 연산과 메모리의 완벽한 구조적 분리를 통해 해결합니다. - 인프라 비용의 파괴
비싸고 용량이 제한된 GPU HBM(고대역폭 메모리)에 얽매이지 않고 파라미터를 유연하게 확장할 수 있어, 기업들의 AI 서비스 구축 단가를 획기적으로 낮춥니다.
결과적으로 Engram은 단순한 성능 개선 수단을 넘어, 차세대 희소 모델(Sparse Models)이 반드시 갖추어야 할 핵심적인 표준(Primitive)으로 자리 잡을 것입니다.
곧 발표될 DeepSeek V4가 Engram을 메인 아키텍처로 채택하고 등장한다면, AI 업계의 화두는 “누가 더 많은 GPU를 가졌는가”에서 “누가 더 영리하게 아키텍처를 설계했는가”로 완전히 뒤바뀔 것입니다. 바야흐로 연산량 만능주의 시대가 저물고, 진정한 ‘설계의 시대’가 도래하고 있습니다.




요즘 AI 얘기를 보면 무조건 모델 크기나 연산량만 늘리면 된다는 분위기가 있었는데, 이 글을 보니까 꼭 그런 것만은 아니라는 생각이 드네요. 기억과 추론을 나누는 구조라는 설명이 특히 흥미로웠습니다. 쉽게 설명해주셔서 재미있게 읽었습니다!