
“이것만 다 읽으면 견적 낼 수 있을 텐데…”
수백 페이지짜리 시방서를 한 장 한 장 넘기며 스펙을 찾는 일, 참 고단한 작업입니다. 분명 글자를 읽고 있는데, 정작 필요한 정보는 자꾸 눈을 피해 다니는 기분이 들죠. 여전히 많은 제조 현장에서는 이 ‘시방서 검토’라는 과정에 많은 시간을 쏟고 있습니다.
“요즘 똑똑하다는 ChatGPT에 시방서를 넣었는데, 왜 스펙 추출이 안 될까요?” 라고 질문하시는 분들이 많은데, 이건 모델의 성능이 부족해서가 아닙니다. 시방서라는 녀석이 워낙 제멋대로라 그렇습니다. 회사마다 형식이 다르고, 동일한 스펙도 표현이 제각각인 비정형 문서이기 때문인데요. 예를 들어, “허용 전류 50A”라는 스펙 하나를 두고도 A사는 ‘정격전류’라 쓰고, B사는 영어로 ‘Rated current’, D사는 표 안에 ‘Imax’라고 적어둡니다.
표: “허용 전류 50A”라는 스펙에 대한 각기 다른 시방서 표현방식

이렇게 형식과 표현이 제각각인 ‘비정형 문서’를 읽어내는 것은 인공지능에게도 꽤 어려운 일입니다. 그래서 이런 문서는 일반적인 규칙 기반(If-Then)으로는 정확한 정보를 추출할 수 없습니다. 결국, 사람처럼 “아, 이 표현이랑 저 표현이랑 같은 거구나” 하고 느끼는 암묵지가 필요합니다.
10년 차 과장님의 숙련된 직관을 복제하다.
🔍 사람은 어떻게 읽나, 암묵지의 정체
사실 10년 차 과장님은 시방서를 슥 훑기만 해도 압니다. ‘Imax’라고 적혀 있어도 “아, 이거 허용 전류 말하는 거네” 하고 단번에 알아차리시죠. 여기엔 두 가지 본능이 작동합니다.
우선 뭘 찾아야 하는지, 즉 우리 제품 견적에 필요한 스펙 목록이 머릿속에 이미 들어있습니다. 그리고 명시적인 키워드가 없어도 맥락으로 읽어냅니다. “과부하 방지 기준”이라는 표현 뒤에 숨은 전류 스펙을 귀신같이 잡아내는 거죠.
우리는 이처럼 숙련된 직관을 암묵지라고 부릅니다. 이 감각은 오직 경험으로만 쌓입니다. 그래서 신입 사원이 두 시간 내내 끙끙댈 일을 베테랑은 30분 만에 끝내는 겁니다.
🤖 AI에게 암묵지를 가르치는 방법 — Hybrid Retrieval
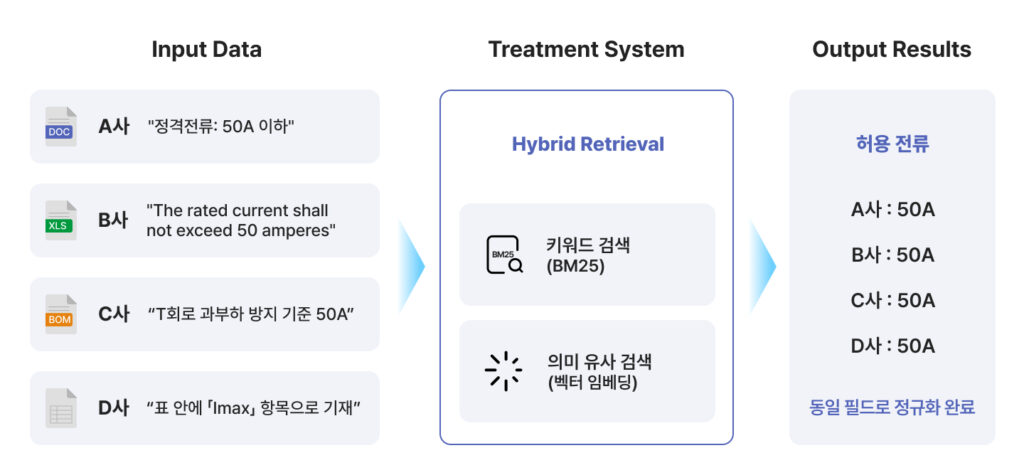
라온피플의 HI FENN Works는 바로 이 ‘과장님의 직관(암묵지)’을 AI에게 가르쳤습니다. 단순히 글자만 찾는 게 아니라, Hybrid Retrieval(하이브리드 검색)이라는 기술로 인간의 읽기 방식을 그대로 복제한 것인데요. 아래의 두 가지 방식을 동시에 사용합니다.
- 키워드 정의 (머릿속 스펙 목록)
‘허용 전류’, ‘Rated current’, ‘Imax’ 같은 필수 키워드를 미리 설정합니다. - 의미적 유사 검색 (맥락 읽기)
문서 전체를 벡터 공간에 펼쳐놓고 의미가 가까운 것들을 찾아냅니다. 덕분에 “과부하 방지 기준 50A”라고 써 있어도, AI는 이를 ‘허용 전류’와 같은 맥락으로 찰떡같이 알아듣습니다.
결국 키워드로 정확도를 잡고, 의미 검색으로 표현의 다양성을 커버하는 셈입니다. 이렇게 HI FENN Works는 신입 사원이 10년 걸려 축적한 노하우를 단 1분 만에 발휘합니다.
검토의 시간을 재정의하다.
복잡한 기술 설계가 끝나는 순간, 실무자는 비로소 ‘시간 대비 효율’이 완전히 달라지는 경험을 하게 됩니다.
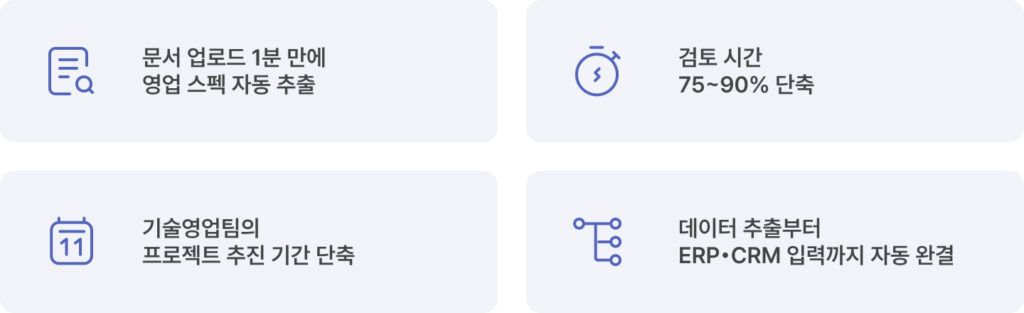
문서를 업로드하고 커피 한 잔을 마시는 짧은 시간 동안, HI FENN Works는 수백 페이지에 달하는 시방서에서 필요한 영업 스펙을 한 번에 추출해냅니다. 사람이 직접 검토하던 시간의 75~90%가 단숨에 줄어드는 셈입니다. 여기서 끝이 아닙니다. 에이전트는 추출된 데이터를 ERP나 CRM과 같은 사내 시스템에 자동으로 입력해, 후속 작업까지 매끄럽게 이어줍니다.
그동안 기술 영업팀이 하나의 프로젝트를 붙잡고 며칠씩 매달리던 시간은, 이제 훨씬 짧고 명확한 흐름으로 재편됩니다.
VLM으로 도면을 해석하다.
하지만 시방서에서 스펙을 정확히 뽑아냈다고 해서, 일이 끝나는 것은 아닙니다.
진짜 난관은 그 다음에 등장합니다. 바로 도면입니다.
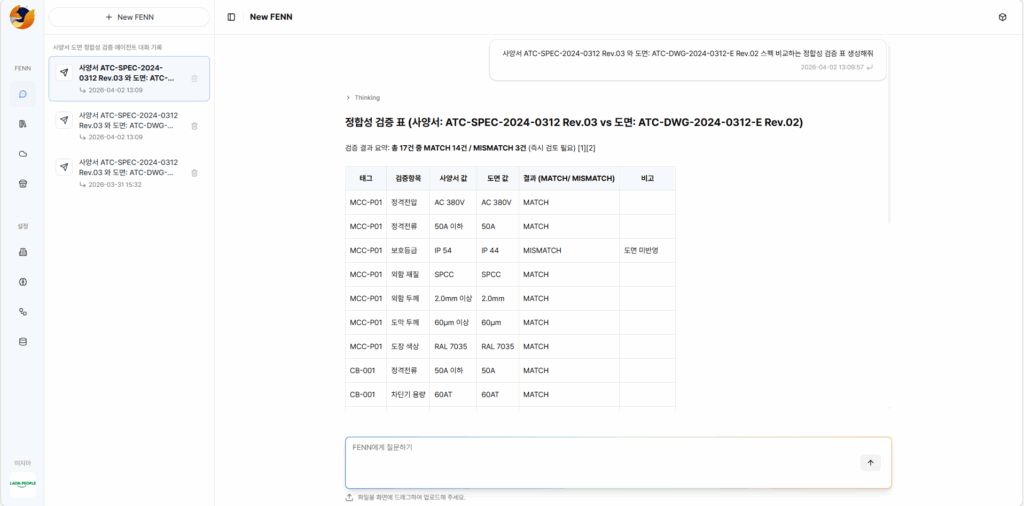
기술 사양서와 도면의 수치는 반드시 일치해야 하지만, 이 둘을 일일이 대조하며 확인하는 과정은 그 자체로 상당한 집중력과 시간을 요구합니다. 반복될수록 피로가 쌓이고, 작은 오차 하나에도 신경이 곤두서게 되는 작업이죠.
그래서 우리는 AI에게 VLM(시각 언어 모델)이라는 ‘눈’을 달아주었습니다.
수많은 도면 이미지를 학습한 VLM은 복잡한 기호와 치수를 정확하게 읽어내고, 시방서에서 추출된 데이터와 일치하는지를 단 1분 내에 판독합니다. 사람이 놓치기 쉬운 미세한 차이까지도 일정한 정밀도로 잡아내죠.
물론 실제 현장에서는 ‘읽어내는 것’만으로는 충분하지 않습니다.
기업마다 동일한 치수라도 그 의미가 길이인지, 폭인지, 두께인지 다르게 해석되기 때문입니다. 그래서 이 AI를 우리 조직의 기준과 용어에 맞게 길들이는 튜닝 과정을 거칩니다. 이 단계를 거치고 나면, VLM은 단순한 숫자를 넘어 그 숫자가 담고 있는 맥락과 의미까지 함께 이해하고 추출하게 됩니다.
비로소, 시방서와 도면이라는 서로 다른 두 정보가 하나의 흐름으로 자연스럽게 연결되는 것이죠.
‘모델’이 아닌 ‘파이프라인’으로 완성하다.
그렇다면, 시방서와 도면을 하나의 흐름으로 연결시키는 것은 어떻게 가능했을까요?
핵심은 ‘모델의 성능’이 아니라, 전체 흐름을 설계하는 ‘파이프라인’에 있습니다.
비정형 문서를 다루는 일은 기업마다, 부서마다 서로 다른 ‘언어와 체계’를 이해해야 하는 작업이기 때문입니다.
데이터를 어떻게 나누고 맥락을 유지할 것인지 (Chunking),
우리 도메인에 맞게 AI를 어떻게 길들일 것인지 (Fine-tuning),
그리고 기계가 놓칠 수 있는 마지막 1%를 사람이 어떻게 보완할 것인지 (Human-in-the-Loop)
이 각각의 지점을 어떻게 배치하고 연결하느냐에 따라, 같은 모델도 전혀 다른 결과를 만들어냅니다.
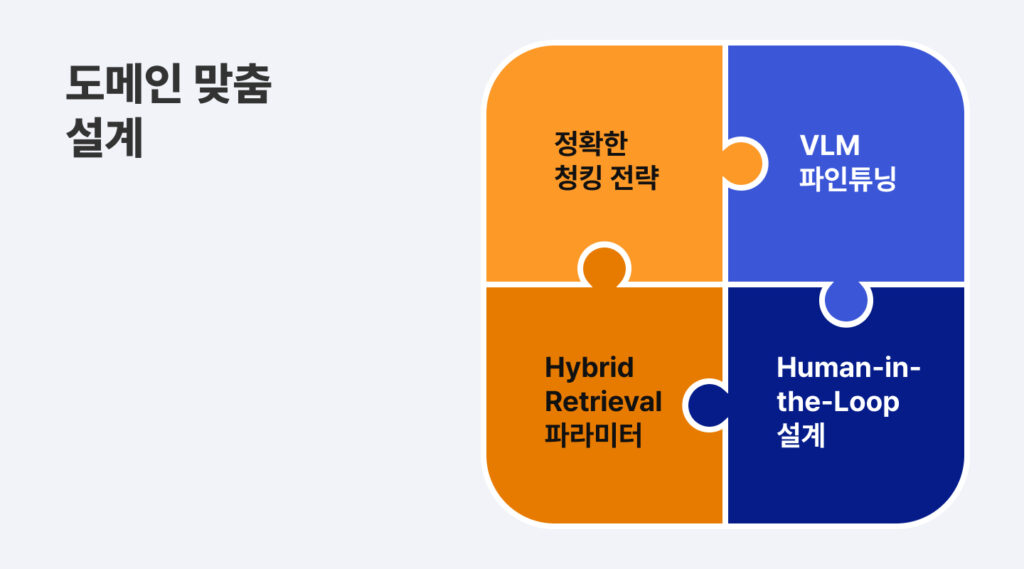
결국 파이프라인 전반을 설계하는 과정에서 가장 중요한 것은 기술을 어디까지 맡기고, 어디서 사람의 판단을 개입시킬 것인가에 대한 균형을 맞추는 것이라고 할 수 있습니다.
라온피플은 다년간의 머신비전과 VLM 개발 경험을 통해, AI가 가장 잘하는 영역과 한계에 부딪히는 지점을 명확히 구분해왔습니다. 동시에, 그 빈틈을 사람의 예리한 판단으로 어떻게 보완해야 하는지도 깊이 이해하고 있습니다.
이 균형 위에서 설계된 HI FENN Works Agent는, 단순한 자동화를 넘어 실무에 바로 적용 가능한 수준의 완성도를 지향합니다.
2026년, HI FENN Works Agent와 함께 시방서와 도면 검토라는 반복적이고 소모적인 작업에서 벗어나, 더 중요한 판단과 전략에 집중해보시길 바랍니다.




댓글
운영 정책에 반하는 글은 사전 고지 없이 삭제될 수 있습니다.