
The release of Qwen3.5 in mid February 2026 sent shockwaves through the AI industry. Beyond mere performance gains, it proved the potential of a new architecture to solve the chronic issue of efficiency in AI. At the heart of its ability to achieve both overwhelming speed and accuracy lies an innovative technology called Gated DeltaNet (GDN).
The process of an AI handling vast amounts of data is often compared to a librarian managing a massive library. The widely used Transformer structure is like a librarian who uses an infinite floor. This librarian spreads out every single page of every book in the library on the floor at once and cross references them whenever something needs to be found. While the accuracy is perfect, the required floor space grows exponentially as the books get thicker. Eventually, the librarian collapses from the exhaustion of scanning tens of thousands of pages. This is exactly why Transformers slow down significantly and consume massive power when reading long texts.
Conversely, methods like RNN or Mamba are like a librarian holding a small whiteboard. They read by jotting down key points on the board as they turn each page, making them very fast. However, after reading thousands of pages, the whiteboard becomes a mess of overwritten letters. When new information arrives, a memory contamination phenomenon occurs, where previous important memories are blurred out.
Qwen3.5 introduced Gated DeltaNet as the problem solver at this very junction. This technology provides the whiteboard librarian with two magical tools: a precise eraser (Delta Rule) that selectively removes unnecessary information, and a powerful washer (Gating) that cleans the board when the context changes.
Through the Delta Rule, GDN updates only the past memories that overlap with current information. Using the Gating mechanism, it flexibly manages memory according to the importance of the information. As a result, Qwen3.5 has succeeded in maintaining the perfect accuracy of a Transformer while increasing inference speeds by several times compared to previous models. This marks the dawn of a next generation AI that is both intelligent and lightweight, possessing both cost efficiency and high intelligence.

Why the Smart AI Librarian Suffers from Amnesia: Limitations of Traditional Linear Attention
The Linear Attention method emerged to address these issues, but it suffered from two fatal flaws. The first is the Whiteboard Without an Eraser problem. Early Linear Attention librarians continued to write over the same board without erasing previous content. As the book grew thicker, information overlapped until it became impossible to discern what was important, leading to a collapse of the Signal to Noise Ratio SNR and ultimately causing the system to lose its past memories.
The second flaw is the Uniform Eraser found in models such as Mamba2. When the whiteboard becomes full, these models dim or erase the entire board regardless of the information’s importance. It is like wiping the entire board with a wet cloth, which significantly diminishes the ability to maintain complex and granular details.
Key Principle ① : The Precise Eraser and the Magic of Incorrect Notes
How did Gated DeltaNet regain its sharp memory? The secret lies in a smart update method called the Delta Rule. While conventional AIs blindly overwrote or roughly smudged information on their whiteboards, GDN first calculates what I do not know yet and then corrects exactly those parts.
The first secret of this process is the Precise Eraser. Mathematically, it employs a somewhat complex concept called the Householder matrix, but the principle is simple. When the AI reads a new word (Key), it precisely targets the exact spot where that information should be stored within the memory space. Specifically, through a process of L2 Normalization that standardizes the information length, this eraser resets only the outdated data in that spot to zero, clearing it perfectly. It has achieved surgical precision, akin to a scalpel, ensuring that only the necessary cells are cleaned before writing new data.
The second secret is the Incorrect Note style of updating. GDN does not save new information as is. Instead, it calculates the difference (Delta) between the incoming information and the information predicted based on existing memory. If the content is already obvious or known, the difference will be near zero, and the memory remains unchanged. Conversely, when entirely new content arrives, only that difference is recorded into the memory.
Through this method, the AI avoids wasting memory on redundant data and efficiently builds up only purely new information. Much like a top student’s study notes that focus only on mistakes while skimming over familiar topics, GDN inherently prevents memory collisions and remembers long contexts with remarkable clarity. This approach shares certain similarities with the Neural Memory update method found in Google’s Titan, which we explored previously.

Key Principle ② – The Powerful Washer and Smart Self Reflection
Having refined the details with a precise eraser, it is now time to manage the entire library board. The final secret of Gated DeltaNet lies in the Powerful Washer (Gating) that regulates the massive flow of context, and when combined with the ideas of Comba currently drawing attention in academia, the performance becomes even more flawless.
The first secret is a powerful cleaning function called the Global Reset. While an AI reads a document, there are moments when the topic completely shifts or a new chapter begins. If previous information remains, it only adds confusion. In such cases, GDN adjusts a valve called the Forget Gate to refresh the entire whiteboard. It simultaneously eliminates noise from the previous context and returns the board to a clean state ready for new information.
Taking this a step further, we need to focus on a powerful auxiliary tool called Comba. Announced in late 2024 by researchers from Princeton University and Together AI, Comba serves as a follow up study to Mamba 2. While the original Gated DeltaNet focused on Input Accuracy by recording information well into memory, Comba focuses on Output Precision by self correcting its own question, asking, “What exactly was I trying to find?”
This is similar to the Closed loop control principle found in complex control systems. If Gated DeltaNet maintains the memory state perfectly and combines it with Comba’s single line query correction formula, the model constantly asks itself what the core objective is, allowing it to strike the target precisely.
Ultimately, when the flawless recording ability of Gated DeltaNet meets the sharp questioning capability of Comba, large scale models like Qwen3.5 can find the most accurate answers without getting lost in complex data. Though they originated from different research paths, they form a perfect double act interlocking toward a single goal of efficiency.

Surpassing Hardware Limitations: The Magic of Parallel Computation Through Batch Processing
Having explored the intellectual aspects of GDN, the next focus is on the remarkable speed this model possesses. Historically, RNN based models like GDN had a fatal weakness. Their sequential structure, which required completing one page before moving to the next, prevented them from fully utilizing the power of modern Graphics Processing Units GPUs that excel at processing many tasks simultaneously.
Gated DeltaNet solved this problem through a sophisticated mathematical design known as WY Representation. While the name is technical, the principle is simple: it transforms tasks waiting in a long line into team based Chunk operations. Small, individual memory updates that previously had to be processed one by one are mathematically bundled into massive General Matrix Multiplication GEMM operations.
To provide context, GEMM is an operation that multiplies two giant matrices containing tens of thousands of data points all at once. Instead of processing information in individual pieces, it calculates tens of thousands of number pairs simultaneously, allowing the GPU to push its powerful parallel processing capabilities to the absolute limit.
To use a simple analogy, it is like moving from having 1,000 students solve a math problem one by one to putting all 1,000 students in an exam hall to take the test at the same time. By changing the computation method to GEMM through WY Representation, Gated DeltaNet has essentially taken data that used to pass through a narrow country lane one car at a time and placed it on an eight lane highway, increasing the speed dozens of times over.
The results of this shift are astounding. Whereas information previously had to be moved one piece at a time along the slow memory paths of the GPU, now the Tensor Cores, the most powerful engines inside the GPU, can launch these bundled operations in a single burst.
Consequently, Gated DeltaNet has secured processing speeds that stand shoulder to shoulder with the fastest known methods, such as FlashAttention or Mamba2. The reason Qwen3.5 can learn from vast datasets in an instant and provide us with immediate answers is due to this efficient design that extracts every last bit of performance from the hardware.

Robust Framework and Sophisticated Components: The Completion of the Architecture
Gated DeltaNet is not just a model with good ideas. To achieve peak performance in actual operation, it features a full option architecture that smartly recombines established technologies. It is akin to designing a modern car engine by placing proven, high quality components exactly where they are needed.
The first component is a small filter called Short Convolution. While Linear Attention is excellent at seeing distant information, it occasionally misses subtle relationships between adjacent words, such as when “New” and “York” combine to form a single proper noun. To prevent this, a small filter was added to scan words in groups of three or four just before the information is processed. Thanks to this, the AI has gained the meticulousness to capture even the finest contextual details.
The second is an efficient management system called Grouped Head Attention GHA. This resembles the technology used in the latest AI models like Llama 3, where the vast memory state is managed by dividing it into several groups. To use an analogy, instead of having one librarian manage every single bookshelf, professional librarians are assigned to specific sections to maximize management efficiency. This allows the model to learn a much wider variety of features simultaneously while reducing memory usage.
Finally, SwiGLU and RMSNorm are combined to ensure system stability. SwiGLU acts as a mixer that blends information to enhance the model’s expressiveness, while RMSNorm functions as a spirit level that maintains balance, preventing numbers from becoming too large or erratic during billions of calculations. Thanks to this sophisticated design, Gated DeltaNet maintains unwavering stability and delivers top tier performance even when processing massive amounts of data.

Proof of Performance: Precision That Never Misses a Single Needle Among a Million Words
No matter how excellent a theory is, it is useless without supporting real world performance. The true value of Gated DeltaNet is clearly revealed in the grueling Needle in a haystack test. This is an evaluation that measures how accurately an AI can find a single, out of place sentence (the needle) hidden within thousands of pages of extensive text.
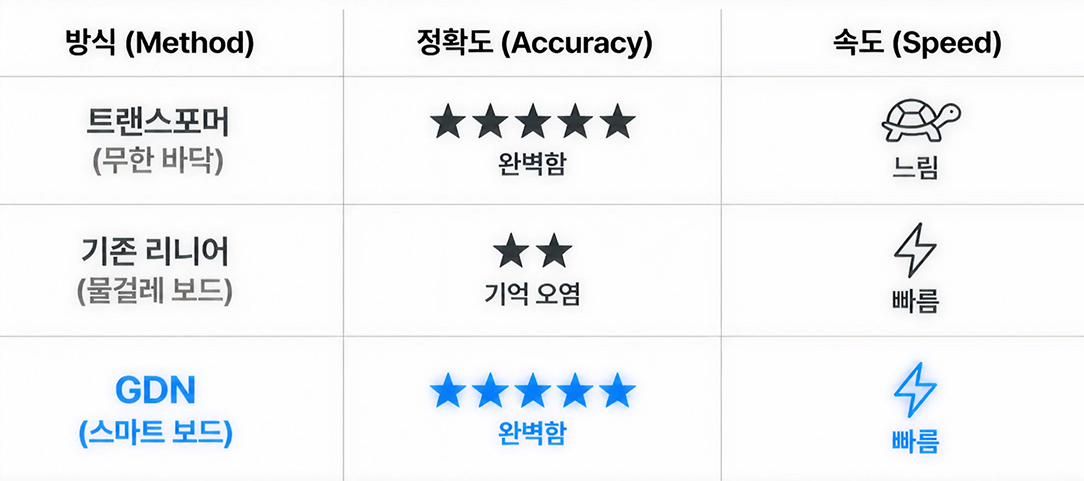
The results were astonishing. While the previous leader, Mamba2, recorded an accuracy of approximately 84.5% and showed signs of missing detailed information within long contexts, Gated DeltaNet achieved an overwhelming accuracy of 98.4%. This means it has reached a level of performance comparable to Transformers, which boast virtually perfect recall, moving beyond simply having a good memory.
This difference is a victory for the erasing strategy explained previously. While Mamba2 lost important needles by blurring all information over time, Gated DeltaNet maintained core information vividly by selectively erasing only unnecessary noise through the Delta Rule.
Furthermore, it proved its versatility by surpassing competing models in Perplexity, an index showing how naturally an AI understands context. Ultimately, GDN has shattered the long standing prejudice in the AI industry that “if it is fast, it is unintelligent, and if it is smart, it is slow.” It has perfectly captured both Transformer class intelligence and linear model class speed.
Strategy Beyond Limitations: Why Qwen3.5 Chose the Golden Ratio
When encountering new technology, the thing to guard against most is looking only at a rosy future. While Gated DeltaNet GDN is clearly an innovative architecture, realistic limitations still exist. How these limits were cleverly bypassed is the true secret behind the success of Qwen3.5.
The biggest challenge was the physical limitation of a fixed container. In a Transformer, as sentences grow longer, the buckets holding information expand infinitely to preserve all data. In contrast, GDN has a strictly defined memory state size. This means that in ultra long documents exceeding millions of words, an information bottleneck can occur where crucial information is overwritten, no matter how sophisticated the eraser.

To solve this, the Qwen3.5 team found a clever compromise called the 3:1 Hybrid Strategy. They configured three out of every four layers with the efficient GDN, while placing one conventional Full Attention layer that remembers all information in its original form.
This quarter of attention layers acts as a sort of high resolution dedicated lane. While GDN rapidly compresses and processes most information, the attention layer preserves core data that must never be forgotten in its original text, preventing any loss of information. Thanks to this, Qwen3.5 maintains the overwhelming speed of a linear model while recording Transformer class precision in needle in a haystack tests.
Of course, implementing such a mixed structure is dozens of times more difficult than a standard model. It requires writing custom code for hardware acceleration, and the process of delicately tuning two different structures to harmonize is a massive challenge for engineers. However, through this technical union, Qwen3.5 has proven that it is possible to be both fast and perfectly intelligent. Ultimately, the future of AI will not be led by a single perfect technology, but by strategic hybrids that complement each other’s weaknesses.
The Era of Intelligent Memory Models: The Golden Ratio of Efficiency and Precision
We have taken a detailed look at Gated DeltaNet GDN, the hidden protagonist behind the explosive performance of Qwen3.5. While past AI either simply spread information out infinitely as seen in Transformers or blindly overwrote data as in traditional Linear Attention, we have now entered the era of intelligent memory that actively writes, edits, and erases information.
By combining the efficient gating technology of Mamba with the precise update capabilities of DeltaNet, GDN has elevated the inherent limitations of linear models to the next level. In particular, as demonstrated in Qwen3.5, the 3:1 hybrid strategy with Full Attention will remain an excellent example of overcoming technical flaws through strategic design.
We live in an era where AI performance directly translates to cost and energy consumption. The reason we must pay attention to efficient architectures like Gated DeltaNet is clear. Implementing higher intelligence with fewer resources is the only way to make AI technology actually work across various industrial fields beyond the laboratory.



