
If the information is clearly inside a PDF, why can’t we find it?
Most of us have experienced this frustration at least once trying to locate a specific number in a PDF report filled with complex tables and charts, or searching for a key clause in a scanned contract, only to come up empty-handed. Even though the information is clearly there, it simply doesn’t show up in the results.
The root of this problem lies in how traditional search systems treat documents as nothing more than sequences of text. While optical character recognition (OCR) makes it possible to extract text from images, it often strips away critical visual context, such as table structures, chart layouts, and overall document formatting.
To address this limitation, a groundbreaking approach called ColPali (ColPali: Efficient Document Retrieval with Vision-Language Models, February 2025) has emerged. Instead of converting documents into text, ColPali understands them as images in their original form.
In this article, we explore how ColPali works and highlight five key insights that reveal the future of document retrieval.

From Reading Text to Seeing Pages
One of ColPali’s most innovative features is the complete removal of the OCR step from the data processing pipeline.
Traditional approaches rely on a multi-stage process—image → OCR → text → retrieval. Along this pipeline, errors are inevitable. OCR engines may misinterpret characters for example, confusing the letter “I” with the number “1” or disrupt the order of complex layouts, leading to information loss and distortion. No matter how advanced a retrieval model is, it cannot produce accurate results if the input text itself is flawed.
ColPali takes a fundamentally different approach. It divides each document page into numerous small image patches and directly interprets their visual features. This allows it to preserve not only textual content, but also critical visual context such as font size, chart structures, and the arrangement of rows and columns in tables.
In other words, ColPali goes beyond simply reading text. It understands that large, bold text likely represents a title, that small text at the bottom of a page is a footnote, and that color-highlighted elements indicate important information demonstrating a level of visual comprehension similar to how humans read documents.
ColPali represents a shift in document retrieval systems from simple text-matching tools to intelligent agents capable of understanding visual semantics.
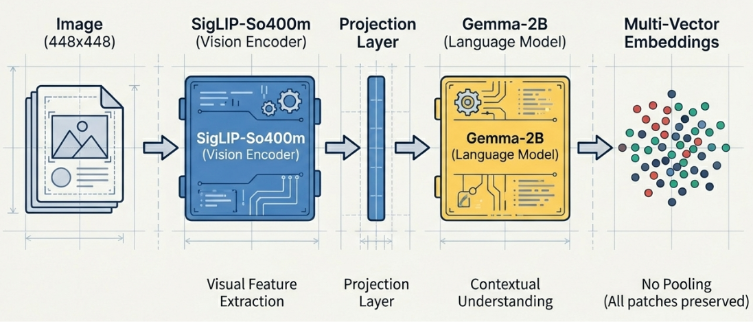
The Cost of Perfect Recall: Massive Storage Requirements
ColPali’s ability to preserve every visual detail on a page is a powerful advantage but it also comes with a critical trade-off: a dramatic increase in storage requirements.
ColPali uses a multi-vector approach, splitting each page into approximately 1,024 small image patches and encoding each one as an individual vector. Compared to traditional methods that compress an entire page into a single vector, this requires significantly more storage.
The difference is substantial.
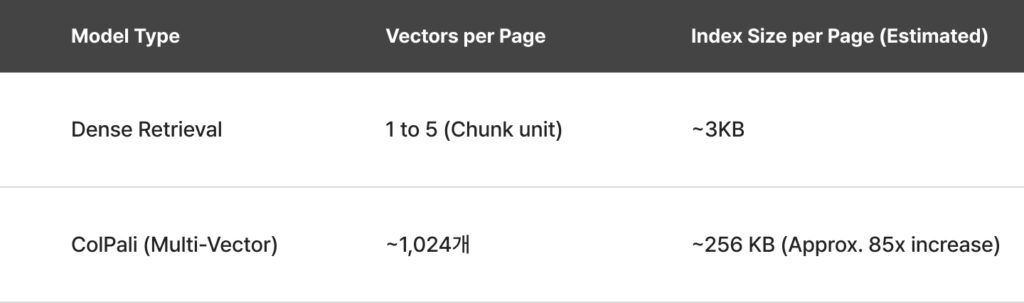
ColPali’s index size can be up to 85× larger than conventional dense retrieval methods. In enterprise environments handling millions of documents, this leads not only to higher storage costs but also increased RAM requirements for loading indices into memory ultimately raising the total cost of ownership (TCO) of the system.
Solving the Cost Challenge with Smart Compression Techniques
At first glance, these storage demands may seem like a major barrier to real-world adoption. However, researchers have introduced clever optimization techniques to address this issue.
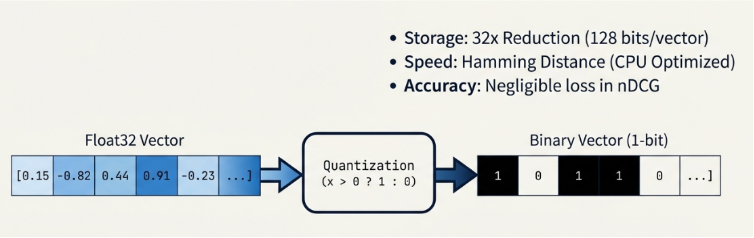
Binary Quantization
This technique compresses vectors by converting floating-point values into binary representations (0 or 1). It’s similar to turning a high-resolution image with millions of colors into a black-and-white sketch that preserves only essential contours.
While some detail is lost, storage requirements can be reduced by up to 32×, with minimal impact on retrieval accuracy.
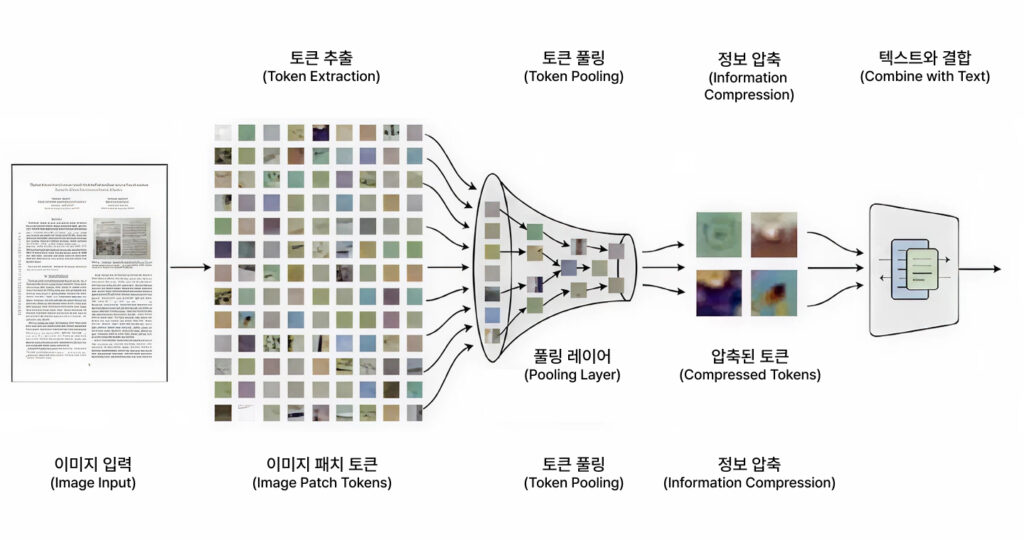
Token Pooling
Another approach, introduced in Light-ColPali, is based on the insight that not all image patches are equally informative. By identifying and removing less meaningful regions such as margins or background areas—the number of stored vectors can be significantly reduced.
Remarkably, even after reducing the number of vectors by 9× (retaining only about 11%), the system can still maintain over 98% of its original performance.
Thanks to these optimizations, ColPali moves beyond a purely experimental model and becomes economically viable for real-world deployment.
The Pace of Innovation: ColPali Has Already Been Surpassed
The speed of progress in AI is relentless. While ColPali introduced a groundbreaking architecture, newer models have already built upon its ideas and pushed performance even further.
One notable successor is ColQwen2 (June 2025). Built on the foundation of ColPali, it incorporates a more advanced vision-language model and introduces a key improvement: dynamic resolution processing.
Unlike ColPali, which resizes all images to a fixed resolution potentially distorting information in long or irregular documents such as receipts ColQwen2 preserves the original aspect ratio, maintaining visual fidelity.
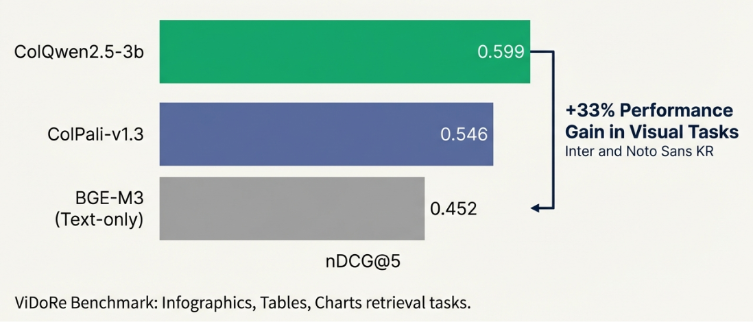
This generational leap is clearly reflected in benchmark results. In ViDoRe a benchmark designed to evaluate how well vision-language models understand the visual structure of documents ColQwen2 models outperform ColPali:
- 1st: ColQwen2.5-3B (0.599)
- 4th: ColPali-v1.3 (0.546)
This does not signal failure for ColPali. Rather, it highlights how rapidly the field is evolving along the path it pioneered—visual-first document retrieval.
Still, Text-Based Retrieval Remains Powerful
It is important to remember that visual retrieval is not the optimal solution for every problem.
Interestingly, in the ViDoRe benchmark, a proprietary text-based model from VoyageAI ranked 3rd, outperforming ColPali. This offers an important insight: If a document contains minimal visual complexity and OCR performance is strong, traditional text-based retrieval can still be highly effective and efficient.
Ultimately, there is no single best approach. The optimal solution depends on the nature of the data whether it is primarily text-driven or visually structured.
A New Question: How Should We See Documents?
The most significant shift brought by ColPali and its successors is the transition from text-centric to visual-centric document retrieval.
We are no longer confined by the limitations of OCR. Instead, we can begin to fully leverage the visual structure and nuance of documents.
Of course, new challenges have emerged particularly in storage and computational cost. But with techniques such as binary quantization and token pooling, these challenges are steadily being addressed.
ColPali ultimately forces us to rethink the core question.
The focus is no longer:
“How can we extract text more accurately?”
Instead, it becomes:
“How can we efficiently index and retrieve visual information?”



