
시각과 언어의 만남, VLM의 정의와 위상
시각-언어 모델(Vision-Language Models, VLM)은 컴퓨터 비전(CV)과 자연어 처리(NLP)의 교차점에서 탄생했습니다. 기계가 시각적 세계를 지각하고 언어를 통해 그 의미를 추론하도록 돕는 VLM은 단순한 이미지 설명 단계를 넘어, 현재는 복잡한 논리적 추론과 자율적 행동이 가능한 ‘멀티모달 에이전트’로 진화하고 있습니다.
이 글에서는 지난 10여 년간의 기술적 도약을 CNN-RNN 파이프라인, 대조 학습의 혁명, 거대 언어 모델(LLM)과의 통합, 그리고 네이티브 멀티모달리티라는 핵심 시기를 중심으로 분석하며, 미래의 피지컬 AI 시대를 조망해 보고자 합니다.
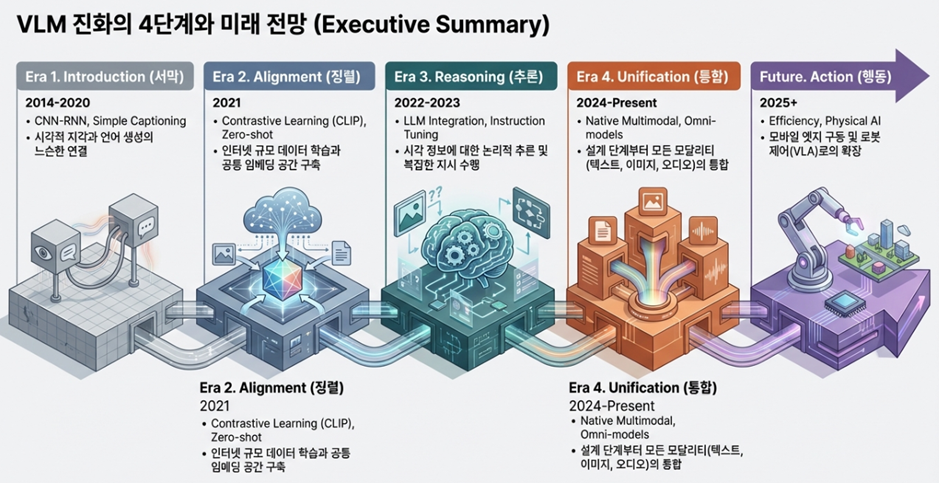
[2014-2020] 시각-언어 통합의 서막: CNN-RNN 파이프라인
초기 VLM 연구는 특정 작업에 최적화된 모듈형 아키텍처가 주류를 이뤘습니다. 이 시기의 핵심은 ‘시각적 지각’과 ‘언어적 생성’을 물리적으로 연결하는 것이었습니다.
- 기술적 메커니즘: 합성곱 신경망(CNN)을 시각 인코더로, 순환 신경망(RNN)을 언어 디코더로 결합한 구조가 대표적입니다. CNN(VGG, ResNet 등)이 이미지를 특징 벡터로 압축하면, LSTM이나 GRU가 이를 전달받아 문장을 생성합니다. 특히 m-RNN 모델은 CNN의 시각 특징을 RNN의 중간 계층에 직접 삽입하여 상호작용의 기초를 마련했습니다.
- 주요 작업: 이미지 캡셔닝(Image Captioning)과 시각적 질의응답(VQA)이 핵심 연구 목표였으며, 2015년경부터는 문장의 파편과 이미지 영역을 정렬하는 기법이 도입되었습니다.
참고) m-RNN(Multimodal Recurrent Neural Network)은 이미지의 시각적 정보와 자연어의 언어적 정보를결합하여, 이미지에 대한 설명을 생성(Image Captioning)하거나 이미지와 텍스트 간의 유사도를 측정하기 위해 설계된 딥러닝 아키테처입니다.
이 모델은 2014~2015년경 Baidu Research 팀(Junhua Mao 등)에 의해 제안되었으며, 당시 컴퓨터 비전과 자연어 처리(NLP)를 연결하는 혁신적인 구조로 평가받았습니다.
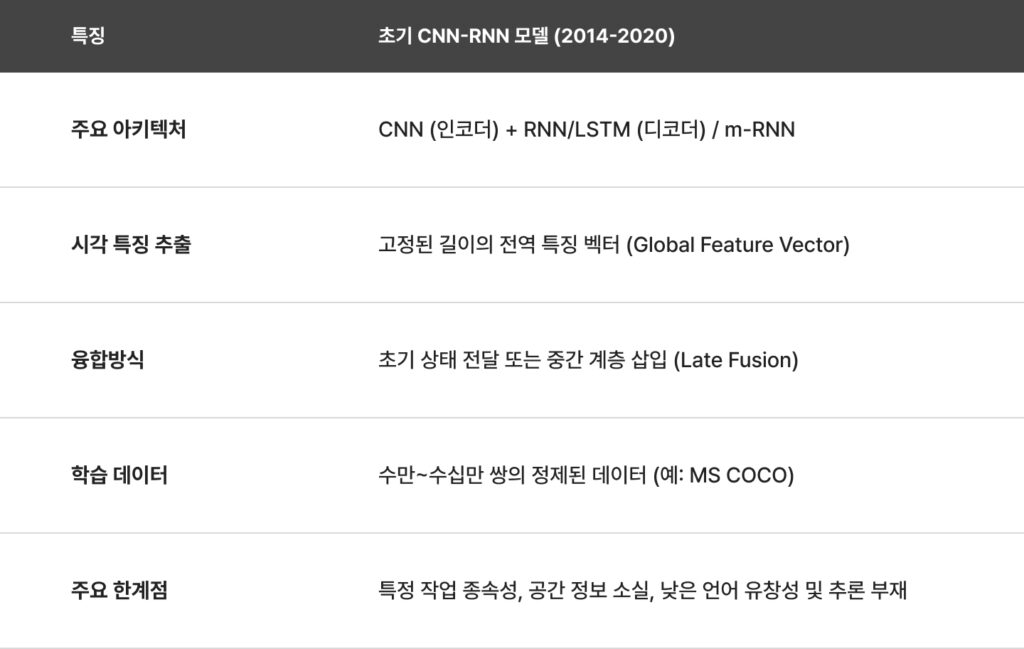
초기 VLM의 기술적 특징 및 한계점
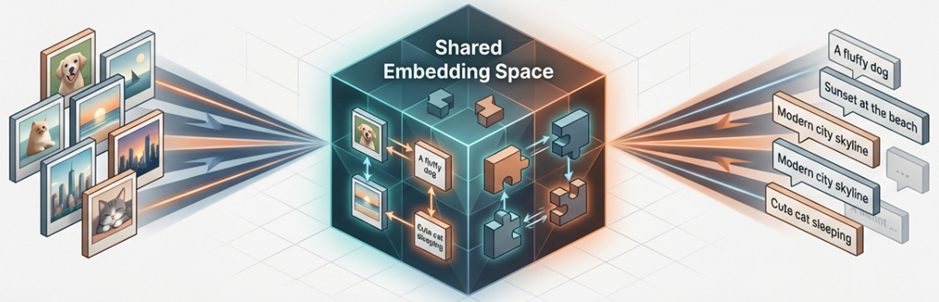
[2021] 대조 학습의 혁명: CLIP과 공통 임베딩 공간의 탄생
2021년 OpenAI의 CLIP(Contrastive Language-Image Pre-training) 등장은 지도 학습 중심의 패러다임을 인터넷 규모의 데이터 기반 ‘대조 학습(Contrastive Learning)’으로 전환시킨 일대 사건이었습니다.
- 패러다임의 전환: 기존의 고정된 범주 레이블을 넘어, 웹상의 4억 개의 이미지-텍스트 쌍을 활용해 범용적인 표현을 학습하기 시작했습니다.
- CLIP의 혁신: 텍스트와 시각 인코더(ViT)를 동일한 고차원 벡터 공간에 투영합니다. 매칭되는 쌍의 유사도는 높이고 나머지는 낮추는 대칭적 교차 엔트로피 손실(Symmetric Cross-entropy Loss)을 사용하며, 이를 통해 별도의 미세 조정 없이도 새로운 개념을 이해하는 ‘제로샷(Zero-shot) 전이 능력’을 확보했습니다.
- 데이터 공학의 흐름: 이후 SigLIP(Sigmoid Loss for Language Image Pre-training)은 구글에서 제안한 모델로 CLIP의 성능과 효율성을 획기적으로 개선한 방식이다. 소프트맥스(Softmax) 대신 시그모이드(Sigmoid) 손실을 도입하여 배치 크기의 한계를 극복하고 학습 효율을 극대화했습니다. 이러한 흐름은 LAION-5B와 같은 초거대 오픈 데이터셋 구축으로 이어졌습니다.
참고) LAION-5B는 전 세계에서 가장 거대하고 대표적인 오픈 소스 멀티모달 데이터셋입니다. 독일의 비영리 단체인 LAION(Large-scale Artificial Intelligence Open Network)에서 제작했으며, 현대 생성형 AI(예: Stable Diffusion)의 폭발적인 발전을 가능하게 한 핵심 밑거름이 되었습니다.
[2022-2023] 거대 언어 모델(LLM)과의 통합 및 지시어 튜닝
2022년 하반기부터 2023년까지 VLM의 발전은 강력한 거대 언어 모델(LLM)을 멀티모달 인터페이스에 결합하는 방향으로 전개되었다. 이 시기의 모델들은 단순히 이미지를 설명하는 것을 넘어, 사용자의 복잡한 지시를 따르고 시각 정보에 기반해 추론하며 대화할 수 있는 능력을 갖추게 되었습니다.
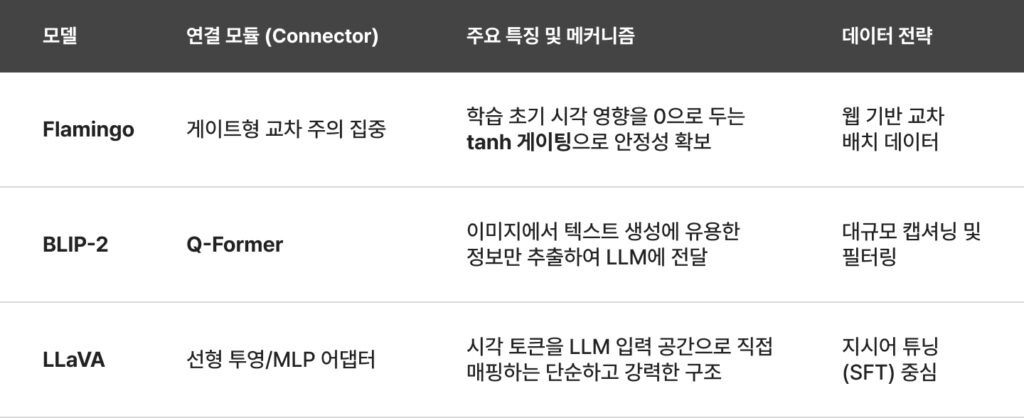
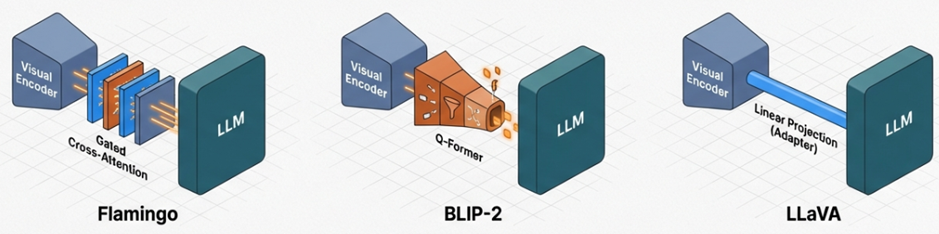
게이트형 교차 주의 집중 (Flamingo)
DeepMind의 Flamingo는 고정된 LLM 계층 사이에 새로운 ‘교차 주의 집중(Cross-attention)’ 계층을 삽입하는 방식을 취했습니다. Flamingo는 시각적 특징을 키(Key)와 값(Value)으로, 텍스트 토큰을 쿼리(Query)로 사용하여 언어 모델이 텍스트 생성 과정에서 시각 정보를 직접 참조할 수 있게 합니다. 특히, 기존 언어 모델의 가중치를 파괴하지 않기 위해 학습 초기에는 시각 정보의 영향력을 0으로 설정했다가 점진적으로 늘리는 ‘tanh 게이팅’ 메커니즘을 도입하여 안정적인 학습을 도모하였습니다.
질의 트랜스포머 (BLIP-2)
BLIP-2는 시각 인코더와 LLM 사이에서 정보를 선택적으로 추출하여 전달하는 ‘Q-Former’ 모듈을 도입하였습니다. Q-Former는 학습 가능한 소수의 쿼리 토큰을 사용하여 이미지 인코더로부터 텍스트 생성에 가장 유용한 정보만을 추출한 뒤, 이를 LLM의 임베딩 공간으로 투영합니다. 이 방식은 시각 정보의 병목 현상을 해결하고, 매우 적은 수의 학습 매개변수만으로도 시각-언어 정렬을 가능케 하여 효율성 측면에서 큰 주목을 받았습니다.
선형 투영 및 MLP 어댑터 (LLaVA)
LLaVA는 가장 단순하면서도 강력한 ‘선형 투영(Linear Projection)’ 방식을 대중화하였습니다. LLaVA 아키텍처에서는 CLIP의 시각 특징 벡터를 단순한 선형 계층 또는 2계층 MLP를 통해 LLM의 입력 토큰 임베딩 공간으로 직접 매핑합니다. 이렇게 변환된 시각 토큰은 텍스트 토큰과 나란히 배열되어 LLM에 입력되며, 모델은 이를 일반적인 텍스트 시퀀스처럼 처리합니다. LLaVA 1.5와 LLaVA-NeXT는 더 나아가 고해상도 이미지를 여러 타일로 나누어 처리하는 기법을 도입하여 OCR 및 정밀 시각 추론 성능을 비약적으로 향상시켰습니다.
시각-언어 연결 아키텍처 비교 분석
- 학습 전략: 단순히 캡션을 다는 수준을 넘어, GPT-4 등을 활용해 생성한 합성 데이터(Synthetic Data)가 핵심이 되었습니다. 특히 ShareGPT4V와 같은 데이터셋은 정밀한 시각 정보를 제공하여 모델이 미세한 공간 관계를 추론하도록 훈련시켰습니다.
[2024] 네이티브 멀티모달리티와 프런티어 모델의 패권
2024년은 모델 설계 단계부터 모든 모달리티를 통합 처리하는 ‘네이티브 멀티모달(Native Multimodal)’ 시대가 열렸습니다. 별도의 어댑터 없이 옴니모달 토큰화(Omni-modal Tokenization)를 통해 텍스트, 이미지, 오디오를 단일 공간에서 처리합니다.
아키텍처의 내재적 통합: 옴니모달 토큰화
네이티브 멀티모달 모델의 핵심은 더 이상 별도의 시각 인코더를 어댑터로 붙이는 방식이 아니라는 점입니다. 예를 들어, Google의 Gemini 1.5 Pro는 희소 혼합 전문가(Sparse Mixture-of-Experts, MoE) 트랜스포머 아키텍처를 기반으로 설계되었으며, 학습 초기 단계부터 텍스트, 이미지, 오디오, 비디오를 통합된 고차원 임베딩 공간에서 동시에 처리하도록 훈련되었습니다.
2024 프런티어 VLM 모델 분석
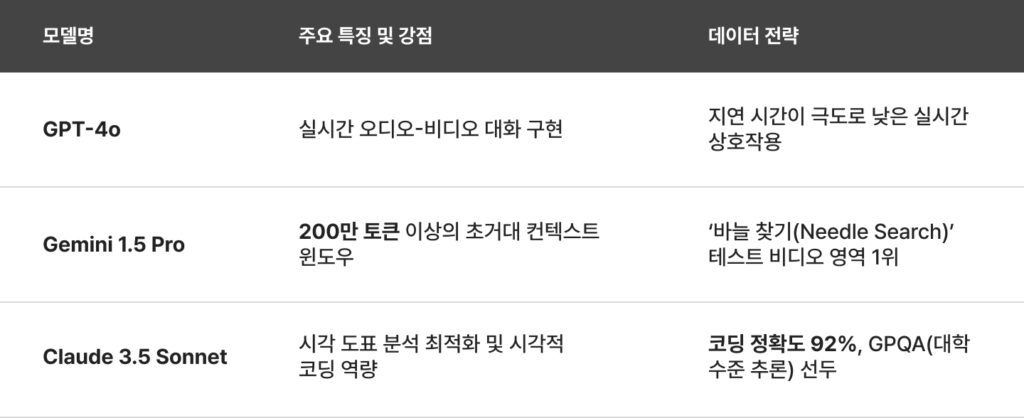
- 핵심 기술: 입력 이미지의 종횡비에 맞춰 타일을 생성하는 동적 해상도 관리와 비디오를 오디오-비디오 토큰이 교차 배치된 병렬 스트림으로 처리하는 기술이 완성되었습니다.
[2025-2026] 실용성과 신뢰성: 엣지 AI 및 할루시네이션 완화
최신 VLM 연구는 거대화를 넘어 모바일 기기에서의 효율적 구동과 답변의 신뢰성(Grounding) 확보에 집중하고 있습니다.
- 온디바이스 VLM: 메모리 대역폭 한계를 극복하기 위해 4비트 양자화가 표준이 되었으며, BitNet(1.58비트)과 같은 극단적 경량화 기술이 등장했습니다. 또한 작은 모델이 생성하고 큰 모델이 검증하는 투기적 디코딩과 경량 MoE 기술이 활용됩니다.
- 신뢰성 지표: 시각적 할루시네이션을 측정하기 위해 다음 세 가지 지표가 중요해졌습니다.
- CPS (Conditional Prompt Sensitivity): 프롬프트 구조 차이가 할루시네이션에 미치는 영향 측정.
- CMV (Conditional Model Variability): 동일 프롬프트 내 모델 아키텍처의 취약성 측정.
- JAS (Joint Attribution Score): 프롬프트와 아키텍처가 결합되어 오류를 증폭시키는 상호작용 측정.
- 억제 전략: 외부 지식을 검색하는 RAG와 스스로 답변을 검토하는 CoVe(Chain-of-Verification) 기법이 적용됩니다.
[2026년 이후] 미래 전망: 피지컬 AI와 자율적 에이전트
VLM은 이제 디지털 세계를 넘어 물리적 세계에서 행동하는 인공지능으로 확장되고 있습니다.
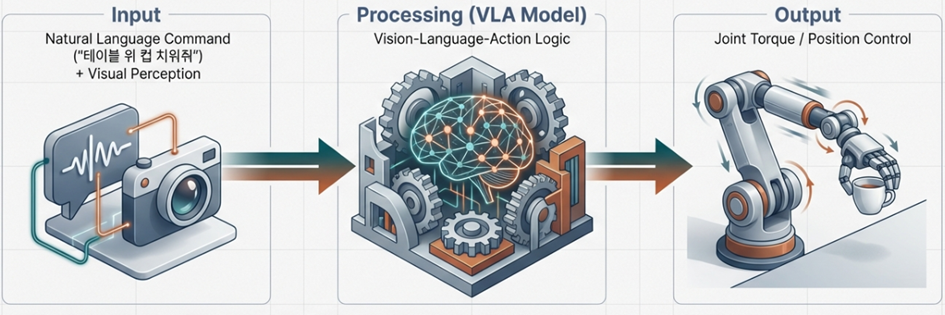
- VLA 모델의 등장: 시각-언어-행동(Vision-Language-Action) 모델은 시각적 피드백을 실시간으로 로봇의 제어 토크로 전환합니다. NVIDIA의 GR00T나 Physical Intelligence의 π₀와 같은 모델은 수조 개의 비디오를 학습하여 물리적 법칙을 익히고 있습니다.
- 스케일링 법칙: 로보틱스 분야에서도 100B 이상의 대규모 모델 도입 시 언어 모델에서 보았던 ‘창발적 능력’이 물리 제어 영역에서 나타날 것으로 기대됩니다.
향후 주요 기술 동향 요약
- 자율 에이전트(Agentic AI): 감독 없는 복잡한 워크플로우 수행 및 자기 수정형 공장 구현.
- 피지컬 AI(Physical AI): 시각-언어-행동 통합을 통한 인간 수준의 로봇 손재주 구현.
- 세계 모델(World Models): 시각적 인과관계를 예측하여 사고를 방지하는 시뮬레이션 능력.
- 소버린 멀티모달(Sovereign AI): 지역 데이터 및 보안 규정에 특화된 의료·법률용 VLM.
마치며: 인간의 진정한 동반자로 거듭나는 VLM
지난 10년간 VLM은 파편화된 기술의 결합체에서 완전한 통합 지능으로 진화해 왔습니다. 단순히 이미지를 묘사하던 초기 단계를 지나, 이제는 네이티브 멀티모달 설계를 통해 인간처럼 감각을 융합하고 방대한 문맥 속에서 통찰을 도출하고 있습니다. VLM은 기계가 세상을 이해하는 방식을 근본적으로 변화시키고 있으며, 향후 우리 삶의 모든 기기에 내재된 개인 비서이자 물리적 노동을 돕는 로봇의 두뇌로서 인간의 진정한 동반자가 될 것입니다.




