“If I could just finish reading all of this, I could finally prepare the quotation…”
Anyone who has spent hours flipping through hundreds of pages of technical specification documents searching for a single requirement knows how exhausting the process can be. You keep reading line after line, yet the information you actually need somehow continues to evade you. Even today, many manufacturing organizations still devote enormous amounts of time to this manual specification review process.
A question we hear surprisingly often is: “We uploaded the specification document into ChatGPT. Why couldn’t it extract the specs correctly?” The answer is not that the model lacks intelligence. The real problem is that specification documents themselves are inherently chaotic. Every company uses different formats, and even identical specifications are described using completely different terminology. For example, one company may write “Allowable Current 50A,” another may call it “Rated Current,” while a third may simply label it “Imax” inside a table.

To humans, these expressions often feel intuitively connected. To AI systems, however, they can appear completely unrelated. This is precisely what makes unstructured documents so difficult to process. Rule-based systems built on rigid if-then logic quickly break down in these environments. What is really required is something much closer to human intuition: the ability to recognize that seemingly different expressions may actually refer to the same underlying concept.
Replicating the Intuition of a Veteran Engineer
🔍 How Humans Actually Read Specification Documents
Experienced engineers rarely read specification documents line by line. A senior engineer with ten years of field experience can skim through a document and immediately recognize that “Imax” refers to allowable current. That intuition is driven by two things.
First, they already know what information matters. The key specifications required for quotation and design are effectively embedded in their memory.
Second, they rely heavily on contextual interpretation. Even if explicit keywords are missing, they can infer meaning from surrounding language. A phrase such as “overload protection criteria” immediately signals that a current-related specification is likely hidden nearby.
This type of accumulated intuition is what we often call tacit knowledge.
And tacit knowledge is difficult to teach because it is built almost entirely through experience. It explains why a new employee may struggle with a document for hours while an experienced engineer finishes the same task in thirty minutes.
🤖 Teaching AI Tacit Knowledge Through Hybrid Retrieval
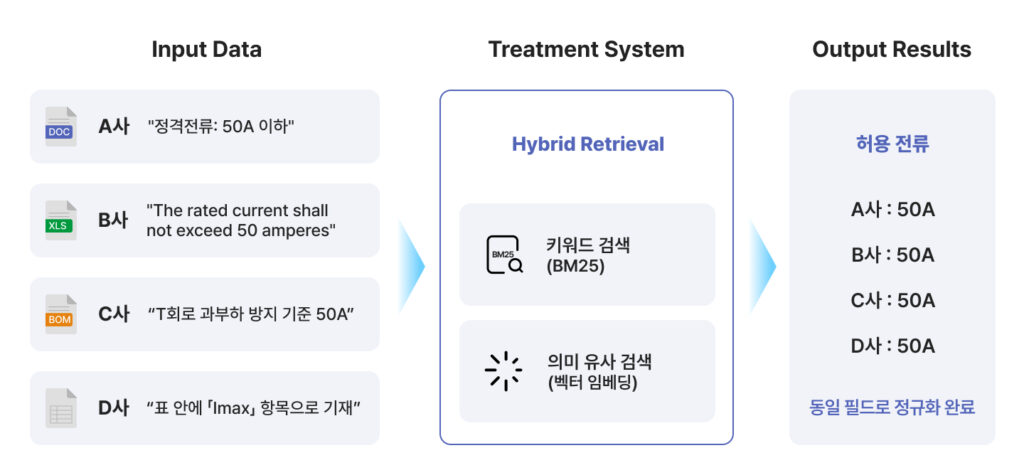
HI FENN Works was designed specifically to replicate this kind of expert intuition.
Rather than merely searching for matching keywords, the system combines multiple retrieval mechanisms through a technique called Hybrid Retrieval, allowing AI to mimic the way experienced humans interpret documents.
The system operates through two complementary approaches.
- Keyword Definition (Keyword Definition)
Essential specification terms such as: “Allowable Current”, “Rated Current”, “Imax”are predefined as important semantic targets. - Semantic Similarity Search (Reading Through Context)
At the same time, the entire document is transformed into vector representations that allow the AI to search for semantically related concepts, even when explicit wording differs. As a result, even if a specification is written as: “Overload protection threshold: 50A”. the AI can still correctly interpret it as an allowable current specification because the surrounding semantic meaning closely aligns with related concepts.
In practice, keyword retrieval ensures precision, while semantic search handles the enormous variability of real-world language. The result is that HI FENN Works can replicate years of accumulated operational know-how in under a minute.
Redefining the Time Required for Specification Review
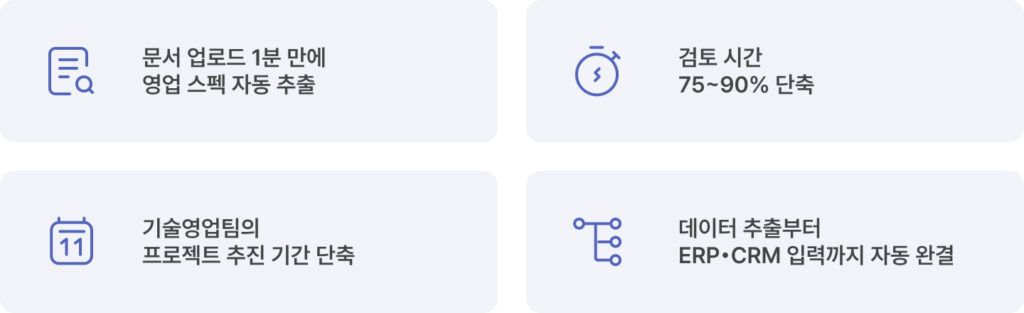
Once the underlying pipeline is properly designed, the workflow changes dramatically for the people actually doing the work. An engineer uploads a document, grabs a cup of coffee, and within moments HI FENN Works automatically extracts key sales specifications from hundreds of pages. Processes that once required hours of manual review can often be reduced by 75% to 90%.
And the workflow does not end there. Extracted data can immediately flow into internal systems such as ERP or CRM platforms, allowing downstream operations to continue automatically without additional manual input. Projects that previously tied up technical sales teams for days can now move through a far more streamlined and efficient operational flow.
Teaching AI to Read Drawings Through VLMs
But extracting specifications from documents is only part of the challenge. The real difficulty often begins afterward: technical drawings.
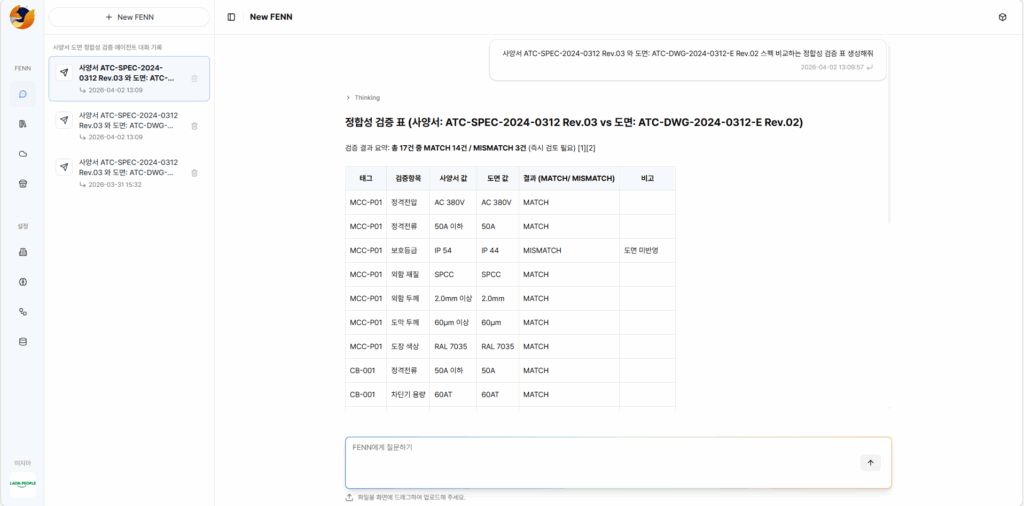
Values written inside specification documents must precisely match the values shown in engineering drawings. Verifying that consistency manually requires enormous concentration and repetitive cross-checking. Over time, fatigue accumulates, and even small discrepancies become increasingly difficult to catch reliably.
This is where we introduced VLMs, or Vision-Language Models, as the AI’s “eyes.” Trained on large volumes of engineering drawings, the VLM can interpret symbols, dimensions, and technical annotations directly from images. It then compares those values against the extracted specification data in real time, often completing the verification process in under a minute. More importantly, the system can detect subtle inconsistencies that humans frequently overlook during repetitive review tasks.
Of course, simply “reading” drawings is not enough in real-world industrial environments. Different organizations may interpret identical dimensions differently depending on internal conventions. The same numerical value may represent length, width, thickness, or tolerance depending on the company’s operational context.
That is why the system undergoes extensive domain-specific tuning aligned with each organization’s terminology and standards. Once this adaptation process is complete, the VLM no longer extracts isolated numbers alone. It begins to understand the contextual meaning behind those numbers as well. At that point, specification documents and engineering drawings stop behaving like disconnected information sources and begin functioning as part of a unified operational workflow.
The Real Breakthrough Was Never the Model. It Was the Pipeline.
So how is it possible to connect specification documents and engineering drawings into a single coherent process?
The answer lies not in the model itself, but in the pipeline architecture surrounding it. Handling unstructured industrial documents requires understanding entirely different organizational languages, workflows, and operational logic across companies and departments.
The real challenge involves questions such as:
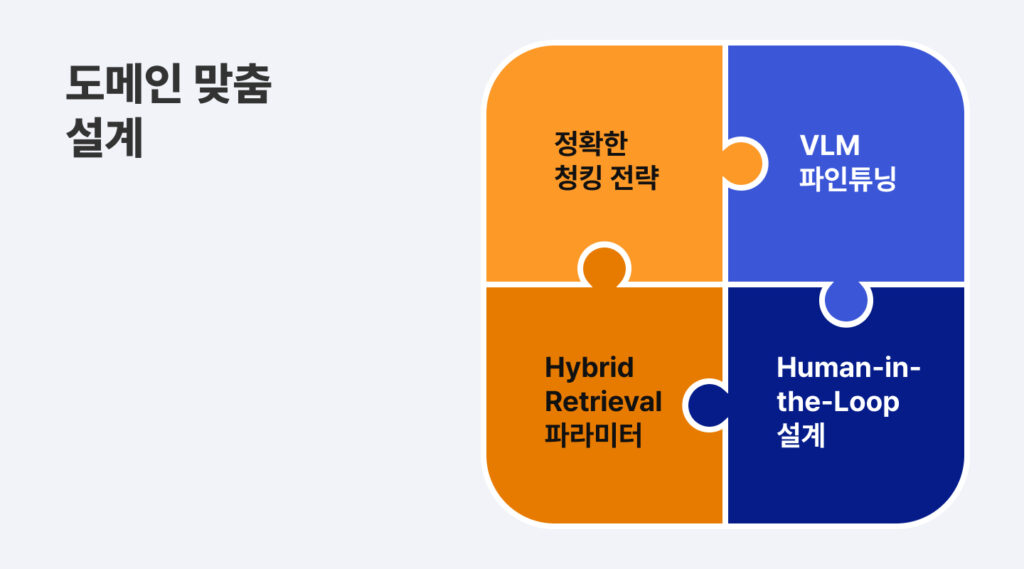
- How should data be segmented while preserving contextual continuity? (Chunking)
- How should the AI be adapted to domain-specific language and workflows? (Fine-tuning)
- Where should human judgment remain inside the loop? (Human-in-the-Loop)
The placement and orchestration of these components fundamentally determine whether the same underlying model produces mediocre results or production-ready performance.
Ultimately, designing an AI pipeline is less about maximizing automation and more about carefully balancing what should be entrusted to machines versus where human expertise must still intervene.
Through years of experience in machine vision and VLM development, LaonPeople has developed a deep understanding of both the strengths and limitations of AI systems. Just as importantly, the company understands how human judgment can strategically compensate for the areas where AI still struggles.
Built upon that balance, the HI FENN Works Agent aims to deliver something beyond simple automation: an AI workflow mature enough for real operational deployment.
In 2026, perhaps the most valuable transformation will not simply be faster document review, but finally freeing technical teams from repetitive specification and drawing verification work so they can focus on higher-value decisions, strategy, and engineering insight instead.