Success in B2B sales often comes down to one thing: how quickly and accurately you can understand a customer’s requirements.
The challenge is that those requirements are rarely simple. In industries such as elevator manufacturing, where thousands of specifications must be combined based on building structures, regulations, and operational requirements, lengthy RFQs and highly detailed specification documents become the very first hurdle in the sales process.
One global manufacturing company we worked with faced exactly this problem. Because elevator systems must simultaneously account for payload capacity, speed, control methods, safety standards, and numerous other variables, reviewing specification documents consumed a significant amount of time and became a major bottleneck slowing down bid response speed.
To solve this issue, LaonPeople designed a “Specification Sales-Spec Extraction Agent.”
Once a specification document is uploaded, the agent automatically extracts relevant sales specifications using predefined attribute names, specification codes, and domain-specific keyword mappings. The extracted information is then automatically mapped into CRM fields without requiring manual input.
As a result, the time previously spent analyzing specification documents was reduced by more than 50%. So how was this transformation actually possible? Let’s take a closer look.
How LaonPeople Solved the Problem
Step 1: Turning Specification Documents into AI-Readable Data
Specification documents, the blueprints of technical sales operations, are among the most difficult types of documents for AI systems to process effectively.
The challenge goes far beyond simple text recognition. The AI must understand product-specific business context while simultaneously interpreting highly complex document structures.
Historically, there were two major barriers preventing AI from analyzing specification documents reliably.
- The first barrier(information asymmetry): AI models do not inherently understand a company’s product structure, terminology, or which specifications are actually critical for quotation and sales workflows. Without contextual grounding, it becomes extremely difficult for the system to distinguish meaningful operational data from surrounding noise.
- The second barrier(document complexity): Specification documents typically contain a chaotic mixture of text, tables, engineering drawings, scanned images, and customer-specific terminology. Formats differ widely between organizations, and critical specifications are often embedded indirectly within long technical descriptions. Simple keyword-based approaches frequently fail to capture the true intent hidden inside the document.
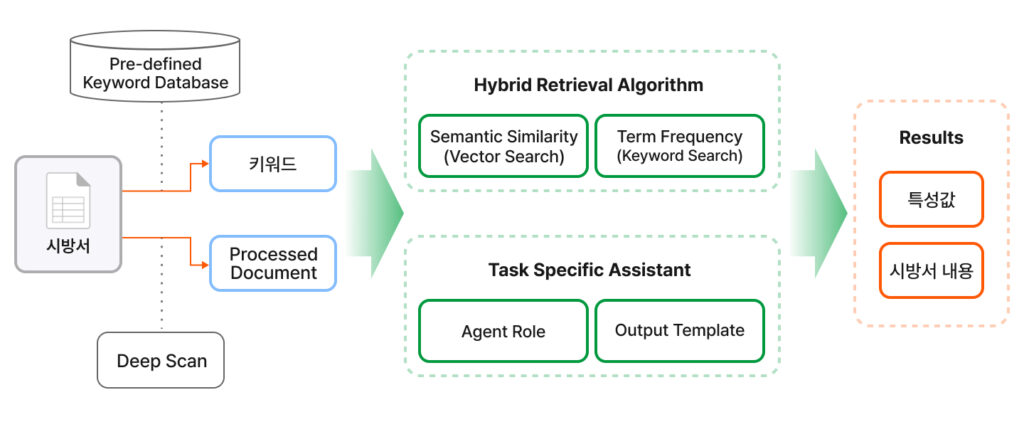
Hi FENN addressed these two challenges directly through its DeepScan technology.
🔍 DeepScan VLM Technology: Understanding Hierarchy Beyond Plain Text
Most of the critical information inside specification documents is buried within tables.
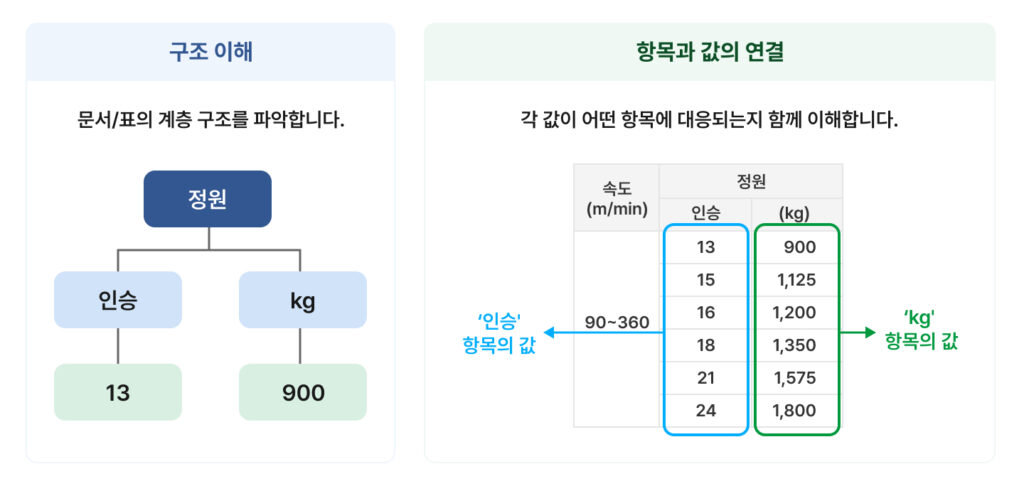
Take elevator capacity specifications as an example. In many real-world documents, the specification is rarely written as something straightforward like “Capacity: 900kg.”
Instead, the information is often structured hierarchically. A higher-level category such as “Occupancy” may contain multiple subfields like “Passengers” and “kg,” each paired with corresponding values such as “13” and “900.”
In this type of document, the important factor is not the number itself, but understanding how each value is structurally connected to surrounding fields.
Traditional AI systems often struggle here.
- Conventional AI: If the keyword “capacity” does not explicitly appear, the system may either fail to extract the specification entirely or retrieve isolated numbers without contextual meaning.
- DeepScan: Using a VLM (Vision-Language Model)-based architecture, the system analyzes document layout itself. It recognizes visual hierarchical relationships the way humans do, including merged cells, nested headers, multi-level table structures, and spatial relationships between fields and values.
👀 Intelligent Embedding: Structuring Data Through an Expert’s Lens
Unlike conventional parsers that simply scrape text fragments, DeepScan preserves the structural relationships between data points during the embedding process.
For example, relationships such as: Occupancy → kg → 900 are stored together as connected contextual information rather than isolated tokens.
Because of this intelligent embedding architecture, when a user requests something like “Find the capacity value,” the AI agent can trace the structural relationships inside the table itself and retrieve the correct value, such as “975kg” or “1125kg,” together with its proper contextual meaning.
In practice, this allows DeepScan to move far beyond simple information retrieval.
Instead of treating specification documents as fragmented text, the system enables AI to interpret documents more like a human expert would, understanding hierarchy, relationships, and semantic structure simultaneously.
This sophisticated transformation process becomes the foundation for highly accurate quotation workflows, ensuring that even a single critical specification hidden deep inside a complex document is not overlooked.
Step 2: Hybrid Retrieval
Connecting Field Language to System Language
Once the data has been extracted through document parsing, the next step is to accurately map those values into the company’s internal CRM structure: Attribute Name – Attribute Code – Attribute Value.
For example, information such as “13 passengers / 900kg” extracted from a specification document must be connected to the corresponding CRM attribute code, such as Capacity (EL_ACAPA), so it can be converted into practical quotation data.
📚 Same Meaning, Different Language: Building a Keyword Knowledge Base
The biggest challenge at this stage is that every customer tends to describe the same specification differently.
Payload Capacity: 1,000kg / Maximum Load: 975kg / Rated Capacity: 1,125kg / Capacity: 1,200kg
Although expressions such as “Payload Capacity,” “Rated Capacity,” and “Capacity” may appear completely different on the surface, all of them ultimately need to be mapped to the same CRM attribute code: Capacity (EL_ACAPA).
To solve this problem, we built a dedicated keyword knowledge base that maps the wide variety of terminology used in real industrial environments to standardized internal system codes.
In other words, we established a predefined semantic reference layer that teaches the AI how different expressions should be interpreted and connected to the correct operational codes.
🧩 Hybrid Retrieval: Combining Precision with Flexibility
Built on top of this keyword knowledge base, we implemented a Hybrid Retrieval architecture that combines two complementary retrieval approaches to maximize mapping accuracy and reliability.
- Keyword Retrieval (Term Frequency): Searches for sections that exactly match predefined keywords. This approach is extremely fast and precise when handling clearly defined specifications, standard terminology, or structured code values.
- Vector Retrieval (Semantic Similarity): Identifies contextually similar expressions even when the wording differs. This allows the system to recognize that terms such as “Payload Capacity” and “Capacity” should ultimately map to the same operational code.
By combining the strict precision of keyword-based retrieval with the flexibility of semantic vector search, the system minimizes confusion between similar concepts while significantly improving overall extraction accuracy.
As a result, workflows that previously required sales teams to manually compare documents and enter CRM data field by field became fully automated, dramatically improving both operational speed and data consistency.
Step 3: Agentic Reasoning
Adding Intelligence That Understands Technical Intent Beyond Keywords
Even after automating document structure analysis and CRM attribute mapping, one major challenge still remained.
Not every requirement inside a specification document is expressed through explicit keywords or clearly defined numerical values. In many real-world cases, critical specifications are implied indirectly across multiple sentences and contextual relationships, making them difficult for traditional keyword-driven systems to detect reliably.
To solve this problem, we introduced Agentic Reasoning.
🧠 Contextual Reasoning Beyond Simple Keyword Matching
One representative example involves detecting whether an elevator specification requires a dual vibration isolation system, a critical condition in many quotation workflows.
What is vibration isolation rubber?
Vibration isolation rubber is installed beneath elevator motors to prevent mechanical vibration from propagating through the building structure. In noise-sensitive environments, two layers of vibration isolation, known as “dual isolation,” are often mandatory.
The challenge is that specification documents frequently do not contain explicit phrases such as: “Apply dual vibration isolation.” Instead, the requirement may appear indirectly through sentences like:
”Install primary vibration isolation rubber and additionally install secondary vibration isolation rubber beneath the machine base.“
Traditional approaches struggle here.
- Conventional keyword systems: If the exact phrase “dual vibration isolation” does not appear, the requirement may be missed entirely.
- Agentic Reasoning: Instead of searching only for explicit keywords, the system interprets contextual relationships between sentences. By recognizing that both primary and secondary isolation layers are specified together, the agent can infer that the CRM field for dual vibration isolation should automatically be marked as “Applied.”
In other words, the agent derives hidden operational meaning even when terminology is never stated directly. More importantly, once a design rule is inferred from one section of the document, the system can consistently propagate that interpretation across related specifications throughout the entire workflow. This allows the AI to move beyond simple extraction and begin reasoning more like an experienced technical engineer reviewing the document itself.
50% Faster Review Time: Shifting Work from “Analysis” to Simple “Verification”
Through this 3 stage innovation process, the customer achieved several measurable operational improvements.
- 50% reduction in review time: The time previously spent reviewing specification documents and manually entering CRM data was cut in half.
- 50% shorter lead time: Processes that once required nearly two weeks to prepare quotations were reduced to less than one week.
- Significantly improved operational efficiency: Sales teams no longer needed to spend hours manually analyzing documents. Instead, their role shifted toward simply validating the AI-generated results and reviewing supporting evidence.
Turning AX (AI Transformation) into Operational Reality
The true value of AX is not simply adopting new technology for the sake of trend-following. Its real purpose is solving concrete operational pain points inside the field.
Through this project, fragmented specification data was transformed into standardized operational data, while experience-dependent workflows evolved into intelligent, system-driven processes capable of reducing variation between individuals.
In rapidly changing industrial markets, this kind of structured operational system becomes a significant competitive advantage.
With Hi FENN Works
, organizations can build faster, more accurate, and far more scalable technical sales environments.