
건망증에 걸린 천재 AI들
시를 쓰고 코드를 짜는 천재 AI 모델들이 사실은 방금 나눈 대화조차 잊어버리는 ‘심각한 건망증(Profoundly Amnesic)’에 걸려있다는 사실을 아시나요? 이 역설은 현재 초거대 AI 모델들이 가진 본질적인 한계입니다. 아무리 많은 정보를 한 번에 입력 받아도, 그 기억은 대화가 끝나면 사라지는 휘발성 정보에 불과합니다.
이 문제에 대한 해답은 놀랍게도 순수한 컴퓨터 공학이 아닌, 인간의 ‘뇌’와 ‘인지과학’에서 영감을 받은 Google의 ‘Titan’ 아키텍처에서 나왔습니다. 그리고 그 결과는 충격적이었습니다. 170M(1억 7천만) 파라미터에 불과한 소형 Titan 모델이, 장기 기억 추론 능력을 평가하는 BABILong 벤치마크에서 수조 개의 파라미터를 가진 GPT-4를 능가하는 ‘다윗과 골리앗’의 싸움을 증명해 보였습니다. Titan은 AI가 정보를 기억하고 학습하는 방식 자체를 근본적으로 바꾸는 혁명을 제안합니다.
이 글에서는 다음과 같은 핵심 질문들을 통해 Titan의 혁신을 파헤쳐 보겠습니다.
- Test-time 학습이란 무엇인가?
- 기존 모델의 기억 방식과 무엇이 다른가?
- 뇌를 모방한 심층 신경망 메모리의 동작 원리
- ‘놀라움(Surprise)’을 통해 기억을 업데이트하는 방법
1. Test-Time 추론이란 무엇인가?: AI가 대화하며 성장하는 시대
‘테스트 타임 학습(Test-Time Training, TTT)’은 기존 AI 개발의 ‘학습 → 동결 → 배포’라는 고정된 패러다임을 완전히 뒤집는 개념입니다. 지금까지의 모델은 한번 배포되면 지능이 변하지 않았지만, Titan은 사용자와 상호작용하는 ‘추론(Test) 시점’에도 모델이 계속해서 학습하고 진화합니다.
Titan의 핵심 철학은 “기억은 데이터가 아니라, 파라미터의 변화다” 라는 한 문장으로 요약됩니다. 기존 모델과 Titan의 차이는 다음과 같은 비유로 명확히 설명할 수 있습니다.
- 기존 모델: 대화 내용을 ‘노트’에 받아 적는 방식입니다. 모든 내용을 그대로 저장하기에 정확하지만, 노트가 꽉 차면(Context Window 한계) 더 이상 쓸 수 없습니다.
- Titan 모델: 대화 내용을 이해해서 ‘뇌의 지식’으로 만드는 방식입니다. 정보가 들어올 때마다 뇌의 시냅스 연결(가중치)이 변하는 것이므로, 용량 제한 없이 정보를 압축하고 축적할 수 있습니다.
2. 기존 모델과의 근본적인 차이점: 기억을 다루는 세 가지 방식
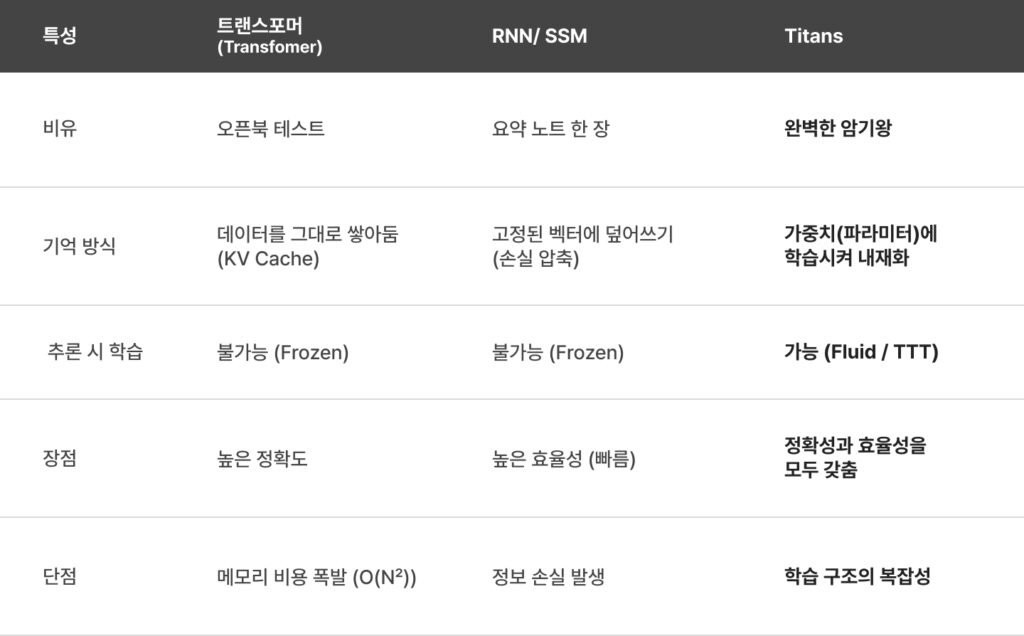
AI가 과거 정보를 기억하는 방식은 Google이 제시한 MIRAS (Memorization, Information Retrieval, and Associative Systems) 프레임워크를 통해 명확히 분류할 수 있습니다. MIRAS는 ‘기억’을 단순히 데이터를 저장하는 문제가 아니라, 손실 함수를 최소화하는 최적화(Optimization) 문제로 재정의합니다. 이 관점에서 세 가지 대표 모델을 ‘시험공부하는 학생’에 비유하면 그 차이점이 극명해집니다.
- 트랜스포머 (Transformer): “오픈북 테스트” 교과서 전체를 펼쳐놓고 답을 찾는 방식입니다. 펼쳐놓은 교과서는 바로 KV Cache이며, 책 내용 그대로이니 정확합니다. 하지만 책이 두꺼워질수록(데이터가 많아질수록) 책상이 모자라고(메모리 폭발) 답을 찾는 데 오래 걸립니다. 이를 MIRAS는 ‘비모수적(Non-parametric) 연관 기억’이라고 부릅니다.
- RNN/SSM: “요약 노트 한 장” 모든 내용을 작은 쪽지 하나에 계속 덮어쓰며 요약하는 방식입니다. 이 쪽지는 고정된 크기의 상태 벡터(Hidden State)이며, 가볍고 빨라서 효율적입니다. 하지만 옛날 내용은 뭉개져서 사라져 버리는 정보 손실이 발생합니다. 이를 ‘손실(Lossy) 연관 기억’이라고 합니다.
- Titan: “완벽한 암기왕” 교과서 내용을 완전히 이해하고 암기하여 자기 지식으로 만드는 방식입니다. 책을 들고 다닐 필요도 없이, 학습된 뇌, 즉 메모리 모듈의 학습 가능한 파라미터에서 바로 정답이 튀어나옵니다. 정확하면서도 가볍고 효율적입니다. 이를 ‘모수적(Parametric) 연관 기억’이라고 부릅니다.
세 가지 기억 방식의 차이점은 아래 표와 같습니다.
3. Titan의 심장: 뇌를 모방한 심층 신경망 메모리
3.1. 구현 방법: 뇌를 닮은 3중 기억 시스템
Titan 아키텍처의 핵심은 인간의 인지 시스템을 모방한 세 가지 분리된 메모리 모듈에 있습니다.
- Core (어텐션 / 작업 기억): 현재 작업에 즉각적으로 집중합니다. 우리가 대화할 때 방금 들은 단어와 문장을 처리하는 작업 기억(Working Memory)과 같습니다.
- Neural Long-term Memory (LMM / 장기 기억): 실시간으로 변하는 경험과 대화 내용을 자신의 파라미터에 압축 저장합니다. 이는 새로운 경험을 빠르게 기록하는 뇌의 해마(Hippocampus)와 유사합니다.
- Persistent Memory (영구 기억): 언어 규칙, 기본 상식 등 사전 학습된 후 변하지 않는 지식을 담고 있습니다. 이는 뇌의 대뇌피질(Neocortex)에 저장된 의미 기억과 같습니다.
이 복잡한 3중 구조는 운영 관점에서 두 가지 역할로 단순화할 수 있습니다. 이는 “유능하지만 지식은 고정된 교수님”과 “실시간으로 노트를 필기하며 성장하는 조교”의 협업과 같습니다.
- Frozen Main Brain (고정된 주 두뇌):
- 정체: Core와 Persistent Memory 모듈이 합쳐진 부분으로, 일반적인 Transformer 모델과 유사합니다.
- 상태: 동결됨 (Frozen). 사전 학습 후 파라미터가 변하지 않습니다.
- 역할: 언어를 이해하고 추론하며, 가장 중요하게는 LMM에 “이거 외워!”라고 명령을 내리는 관리자 역할을 합니다.
- Fluid Memory Module (유동적인 기억 저장소):
- 정체: Neural Long-term Memory (LMM)에 해당하는 작고 단순한 MLP 신경망입니다.
- 상태: 계속 변함 (Fluid). 추론 중에도 실시간으로 파라미터가 업데이트됩니다.
- 역할: 과거의 정보를 자신의 가중치에 압축하여 저장하는 ‘살아있는 메모리’입니다.
3.2. 동작 원리 및 인지과학과의 유사점
이 시스템은 크게 ‘읽기(Recall)’와 ‘쓰기(Memorize)’ 두 단계로 작동합니다. 새로운 정보가 들어오면, 주 두뇌는 먼저 LMM에 저장된 과거 기억을 ‘읽어서’ 현재 정보와 종합해 답변을 생성합니다.
그 후 ‘쓰기’ 단계가 진행됩니다. 이때 주 두뇌는 방금 들어온 정보가 얼마나 예상 밖이었는지, 즉 ‘놀라움(Surprise)’의 정도를 측정합니다. 만약 놀라움이 크다면, 주 두뇌는 LMM의 파라미터를 크게 업데이트하도록 명령합니다. 이 과정은 인간의 뇌에서 놀라운 사건이 발생했을 때 ‘노르아드레날린’이 분비되어 기억을 강하게 각인시키는 원리와 놀랍도록 유사합니다.
4. 살아있는 파라미터: 테스트 타임에 학습된 기억의 관리
테스트 타임 학습의 결과로, ‘메모리 파라미터’는 고정되지 않고 사용자와의 상호작용에 따라 여러 버전으로 갈라질 수 있습니다. Titan의 해법은 ‘플러그 앤 플레이(Plug & Play)’ 방식입니다. 거대한 본체 모델은 서버에 하나만 두고, 사용자별 또는 주제별로 작게 분리된 ‘메모리 모듈의 가중치’만 파일처럼 저장하고 불러와서 교체하는 것입니다.
이는 기존의 RAG(검색 증강 생성) 방식과 근본적인 차이를 보입니다.
- RAG: 내 하드디스크에 PDF 파일들을 폴더별로 정리해 두는 것.
- Titans: 내 AI에게 끼워줄 ‘관심사별 뇌 조각(메모리 칩)’을 서랍에 정리해 두는 것.
5. ‘놀라움(Surprise)’이 기억을 만드는 원리
정답지가 없는 추론 상황에서 어떻게 학습이 가능할까요? 그 해답은 ‘자가 지도 학습(Self-Supervised Learning)’ 원리에 있습니다. 언어 모델의 세계에서는 “다음에 올 단어가 곧 정답지”가 됩니다.
‘놀라움 지표(Surprise Metric)’는 기술적으로 손실 함수의 기울기(Gradient of Loss)를 의미하며, 이는 모델의 ‘예측과 실제의 차이’를 나타냅니다. 파라미터 업데이트는 이 놀라움의 크기에 따라 두 가지 경우로 나뉩니다.
- Case A (뻔한 내용): 모델의 예측(“나는 학교에”)이 실제 입력(“간다”)과 거의 일치합니다. 이때 놀라움(오차)은 거의 0에 가까워 파라미터는 변하지 않습니다. 이는 “이미 아는 내용은 기억할 필요 없다”는 효율적인 기억 관리 방식입니다.
- Case B (새로운 정보): 모델이 전혀 예상치 못한 정보(“나는 학교에 갑자기 춤을 추는 고양이”)가 들어옵니다. 예측이 실제와 크게 다르므로 놀라움(오차)이 커지고, 파라미터는 크게 변합니다. 이는 “몰랐던 정보는 뇌리에 강하게 새긴다”는 원리를 구현한 것입니다.
혹시 “아무말 대잔치” 같은 쓸모없는 정보가 들어와 메모리가 오염될 수 있다는 우려가 있을 수 있습니다. 하지만 Titan은 방어 기제를 갖추고 있습니다. 입력된 정보가 문맥에 맞지 않으면 주 두뇌가 게이트를 닫아 업데이트를 막거나, 수학적 패턴이 없는 순수한 노이즈는 학습되기 어려워 자연스럽게 걸러집니다.
하지만 Titan에도 한계는 존재합니다. 인지과학의 상보적 학습 시스템(Complementary Learning Systems, CLS) 이론에 따르면, 인간의 진정한 학습은 빠른 기억을 담당하는 ‘해마’와 느리게 지식을 구조화하는 ‘대뇌피질’의 상호작용으로 이루어집니다. Titan처럼 기억 모듈(해마)만 계속 변하고 주 두뇌(대뇌피질)가 고정되어 있다면, 진정한 의미의 ‘이해’나 ‘지식의 일반화’에는 한계가 있을 수 있다는 점은 앞으로 해결해야 할 과제입니다.
진정한 의미의 ‘학습하는 기계’를 향하여
Titan이 제시한 패러다임은 AI가 더 이상 ‘공장에서 찍어낸 고정된 제품’이 아니라, 사용자와 함께 상호작용하며 성장하는 ‘유기체적 소프트웨어’가 될 것임을 예고합니다. 사용자와의 대화 하나하나가 모델의 뇌 구조를 미세하게 바꾸며, 쓸수록 더 똑똑해지는 진정한 의미의 ‘학습하는 기계’가 탄생하는 것입니다.
Titan의 한계를 보완한 후속 연구 ‘Atlas’는 고차원 특징 매핑을 통해 메모리 포화 문제를 해결하는 등, 이 기술은 이미 빠르게 진화하고 있습니다. 이는 단순히 컨텍스트 창을 늘리는 기술적 개선을 넘어, AI가 정보를 기억하고, 학습하고, 진화하는 방식 자체를 근본적으로 바꾼 혁명이라 할 수 있습니다. 우리는 이제 막 기억 상실을 끝낸 AI와 함께 새로운 시대를 맞이하고 있습니다.



