
AI의 ‘기억상실증’을 해결하다.
AI 챗봇과 대화하다가 방금 나눈 이야기를 까맣게 잊어버리는 경험, 다들 한 번쯤 있으실 겁니다. 마치 ‘단기 기억상실증’에 걸린 듯, 대화의 맥락을 놓치고 엉뚱한 답변을 내놓는 AI에게 답답함을 느끼셨을 텐데요. 사실 이것은 AI의 지능이 낮아서가 아니라, 지난 10년간 AI 시대를 지배해 온 ‘트랜스포머(Transformer)’ 아키텍처가 가진 태생적 한계 때문이었습니다.
트랜스포머는 한 번에 처리할 수 있는 정보의 양(컨텍스트 윈도우)이 제한되어 있고, 그 창을 벗어난 정보는 가차 없이 잊어버리는 구조(O(N^2) 복잡도)를 가지고 있습니다. 이 고질적인 ‘망각(Forgetting)’ 문제 때문에 AI는 진정한 의미의 기억력을 가질 수 없었죠.
하지만 구글이 발표한 ‘타이탄(Titans: Learning to Memorize at Test Time)’이라는 새로운 AI는 이 모든 판도를 뒤엎었습니다. AI가 드디어 ‘기억상실증’을 극복하고, 우리와의 모든 상호작용을 영원히 기억할 수 있는 ‘진정한 기억력’을 갖게 된 것입니다.
🧠 발상의 전환: 기억은 ‘저장’이 아니라 ‘최적화’다.
타이탄 아키텍처의 가장 혁신적인 지점은 ‘기억’에 대한 기존의 관념을 완전히 뒤집었다는 것입니다. 그 기저에는 MIRAS(Memorization, Information Retrieval, and Associative Systems)라는 새로운 이론적 프레임워크가 있습니다. MIRAS는 기억을 ‘저장된 데이터(Stored Data)’로 보는 대신, ‘최적화 문제(Optimization Problem)’로 재정의합니다.
“Titans는 “기억은 학습 과정 그 자체(Memorization is Learning)“라는 철학을 따릅니다.”
이는 인간의 뇌가 작동하는 방식과 놀랍도록 닮아있습니다. 우리가 새로운 경험을 할 때, 뇌의 특정 공간에 데이터 파일이 생기는 것이 아니라 뇌세포(뉴런) 사이의 연결, 즉 시냅스의 강도가 변합니다. 타이탄도 마찬가지입니다. 새로운 정보가 들어올 때마다, 모델 내부의 신경망을 실시간으로 미세하게 다시 훈련시켜 정보 그 자체를 ‘체화(體化)’합니다. 즉, 정보를 가장 잘 재현할 수 있도록 신경망의 파라미터를 최적화하는 과정이 바로 기억인 것입니다.
기존 트랜스포머가 이전 대화 내용을 임시 저장소(KV 캐시)에 쌓아두다 용량이 차면 버리는 방식이었다면, 타이탄은 모든 정보를 자신의 신경망 가중치(Weight)에 녹여내어 영구적인 지식으로 바꾸는 것입니다. 기억은 더 이상 저장된 파일이 아니라, 끊임없이 최적의 상태를 찾아가는 모델 그 자체가 된 것이죠. 그래서 한번 학습을 마치면, 동결(freeze) 되는 다른 모델들과 달리, Titans는 심층 신경망 메모리를 이용해 Test-time에도 기억을 update하는 완전히 새로운 구조를 갖고 있으며, 심층 신경망 메모리에 있는 MLP를 이용해 기억을 처리하기 때문에 최적화라는 개념이 성립하는 것입니다.
이 개념은 어느 날 갑자기 툭 튀어 나온 개념이 아니라, 사람의 인지적 모델을 빌려온 것입니다. 인간의 뇌가 단기 기억, 장기 기억, 그리고 경험을 통해 얻은 지식을 분리하여 관리하듯, TITAN 역시 세 가지 유형의 메모리 모듈을 통합하여 정보를 처리합니다.

사람의 기억이 해마 영역에 머물다가 장기기억 영역으로 넘어가듯이, 심층 신경망 메모리(Neural Long-term Memory)를 이용해 이 부분을 구현하는데, 이것이 다른 모델들과 달리 놀라운 성능을 얻을 수 있는 핵심 요인이 됩니다.
🚀불가능의 증명: 10억 개 파라미터로 1000만 토큰을 기억하다.
타이탄의 등장은 단순히 점진적 개선이 아닌, AI 메모리 시스템의 근본적인 도약이라고 할 수 있습니다. 기존 AI 메모리 시스템을 분류해 보면 그 차이가 명확해지는데요. 트랜스포머는 과거 정보를 완벽히 보존하지만 비용이 엄청난 ‘비모수적(Non-parametric)’ 기억, Mamba와 같은 RNN 계열은 정보를 고정된 벡터에 압축하며 손실이 발생하는 ‘손실(Lossy)’ 기억입니다. 하지만 타이탄은 정보를 신경망의 파라미터 자체에 학습시키는 혁신적인 ‘모수적(Parametric)’ 기억 방식을 제시합니다.
이 새로운 방식이 얼마나 대단한 성과를 거두었는지는 하나의 실험 결과로 요약됩니다. MAC(Memory as Context)이라는 아키텍처 변형(메모리가 생성한 ‘기억 토큰’을 일반 텍스트처럼 처리하는 방식)을 사용한 10억 개(1B) 미만의 작은 모델이 무려 1,000만 토큰(책 수십 권 분량)에 달하는 방대한 텍스트 속에서 특정 정보를 80% 이상의 정확도로 찾아낸 것입니다.
이 성능은 ‘건초더미에서 바늘 찾기(Needle-in-a-Haystack)’라는 혹독한 벤치마크를 통해 검증되었습니다. 말 그대로 수십 권의 책 내용(건초더미) 속에 특정 문장(바늘) 하나를 숨겨두고, AI에게 찾아보라고 시키는 테스트입니다. 기존 초거대 모델들과의 성능 비교 결과는 그야말로 충격적입니다.
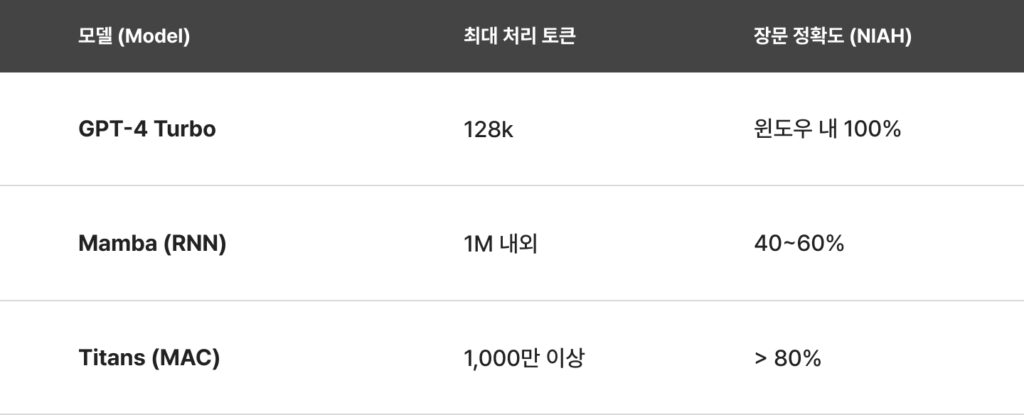
이 표가 의미하는 바는 단순히 컨텍스트 창이 늘어났다는 것이 아닙니다. 이는 AI의 지능을 담당하는 ‘용량(Capacity)’과 정보를 담는 ‘기억력(Memory)’이 처음으로 분리될 수 있음을 증명한 사건입니다. 즉, 덩치는 작지만 세상의 모든 책을 기억하는 ‘작지만 박식한 AI’의 등장을 예고한 것입니다. 더욱 놀라운 점은 이 모든 과정이 A100이나 H100 같은 일반 GPU 한 장에서도 구동 가능할 정도로 효율적이라는 사실입니다.
하지만 구글 연구진은 80%의 정확도에 만족하지 않았습니다. 1,000만 토큰 이상에서는 파라미터가 포화되며 성능이 정체될 조짐을 보였기 때문입니다. 이 한계를 돌파하기 위해 등장한 후속작이 바로 ‘아틀라스(Atlas)’입니다. 아틀라스는 기억을 고차원 공간에 매핑하는 기술을 통해 파라미터의 간섭 문제를 해결했고, 마침내 1,000만 토큰 이상에서도 성능 저하가 거의 없는 ‘무손실에 가까운(Near-lossless)’ 기억력을 달성했습니다. 타이탄이 장벽을 부쉈다면, 아틀라스는 그 기술을 완성한 것입니다.
💡 효율성의 비밀: AI는 ‘놀라운’ 것만 기억한다.
1,000만 단어를 전부 기억하려면 엄청난 에너지가 필요할 텐데, 타이탄은 어떻게 작은 모델로 이 모든 것을 해냈을까요? 비밀은 인간처럼 ‘중요하고 놀라운 사건’을 선별적으로 기억하는 데 있습니다.
타이탄은 모든 정보를 무차별적으로 학습하지 않습니다. 대신 MIRAS 프레임워크의 정보 이론에 기반한 ‘놀라움(Surprise)’이라는 지표를 사용해 기억할 정보의 우선순위를 정합니다. 여기서 ‘놀라움’이란 모델의 ‘예측 오류’를 의미합니다.
- 놀랍지 않은 정보: “나는 학교에…” 다음에 “간다”가 나올 것은 쉽게 예측할 수 있습니다. 이런 정보는 예측 오류가 거의 없으므로 ‘놀랍지 않다’고 판단하고 그냥 지나칩니다.
- 놀라운 정보: 반면, 딱딱한 법률 문서 중간에 “갑자기 춤을 추는 고양이”라는 문장이 나타난다면 어떨까요? 모델의 예측은 완전히 빗나가고, 엄청난 예측 오류가 발생합니다. 타이탄은 이를 정보량이 높은 ‘놀라운 정보’로 판단하고, 이 내용을 자신의 기억 신경망(LMM)에 강하게 각인시킵니다.
이처럼 예측 가능한 일상은 흘려보내고, 예측 불가능한 특별한 사건에 집중하는 ‘놀라움’ 기반의 선택적 기억은 단순한 발견이 아닙니다. 이는 제한된 메모리 자원을 가장 정보 가치가 높은 데이터에 할당하는, 수학적으로 정교하게 설계된 전략입니다. 덕분에 타이탄은 제한된 파라미터 용량으로도 방대한 정보의 핵심을 효율적으로 저장하고 불필요한 노이즈는 걸러낼 수 있습니다.
🌊 현실적 파급력: 검색 증강 생성(RAG)의 시대가 저물다.
현재 많은 AI 서비스들은 ‘검색 증강 생성(RAG)’이라는 기술에 의존합니다. 사용자의 질문과 관련된 정보를 외부 데이터베이스에서 ‘검색’한 뒤, 그 내용을 프롬프트에 ‘복사-붙여넣기’하여 답변을 생성하는 방식입니다. 하지만 이 방식은 검색이 부정확하거나, 여러 문서에 흩어진 정보들 사이의 유기적인 연결(organic connections)을 파악하지 못하는 명백한 한계가 있었습니다.
타이탄은 이 패러다임을 완전히 바꿉니다. Titan Miras 모델은 문서를 검색하지 않습니다. 대신, 수천 개의 논문과 책을 통째로 ‘읽고 학습하여’ 지식 자체를 내재화합니다.
구글의 ‘NotebookLM’ 서비스에 Titan Miras가 통합된 사례가 대표적입니다. 사용자가 자신의 연구 자료 수십 개를 업로드하면, AI는 그 모든 내용을 완전히 외운 전문가처럼 막힘없이 답변합니다. 외부 DB를 뒤지는 것이 아니라 자신의 내재된 기억 속에서 직접 답을 꺼내오고, 문서 간의 숨겨진 연결고리를 꿰뚫어 보는 통찰력까지 보여줍니다. 덕분에 정보가 누락되거나 왜곡되는 환각(Hallucination) 현상이 현저히 줄어듭니다.
머지않아 우리는 AI에게 문서를 ‘검색’시키는 것이 아니라, 직접 ‘학습시키는’ 시대를 맞이하게 될 것입니다. RAG의 시대는 저물고, AI가 스스로 지식을 체득하는 새로운 표준이 열리고 있습니다.
📱 내 손 안의 AI: 내 모든 것을 기억하는 개인 비서의 탄생
타이탄의 혁신은 거대한 데이터센터에만 머물지 않습니다. 내부적으로 ‘바나나 2 플래시(Banana 2 Flash)’라는 코드명으로 개발된 초경량 모델, Titan Nano의 등장은 이 강력한 기억력이 우리의 스마트폰과 같은 개인 기기 안으로 들어올 수 있음을 의미합니다.
온디바이스 AI의 가장 큰 장점은 보안입니다. Titan Nano는 사용자의 문자 메시지, 이메일, 일정, 사진 등 지극히 개인적인 데이터를 외부 서버로 전송하지 않고, 기기 내에서 안전하게 학습하고 기억할 수 있습니다.
이 기술이 상용화된다면, 우리의 AI 비서는 더 이상 어제 나눈 대화를 잊어버리지 않을 것입니다. 사용자의 말투, 습관, 중요한 기념일, 친구와의 약속 등 삶의 모든 맥락을 기억하고, 쓰면 쓸수록 나를 더 잘 이해하는 ‘진정한 의미의 개인 비서’가 모든 사람의 손안에 쥐어질 것입니다.
마치며
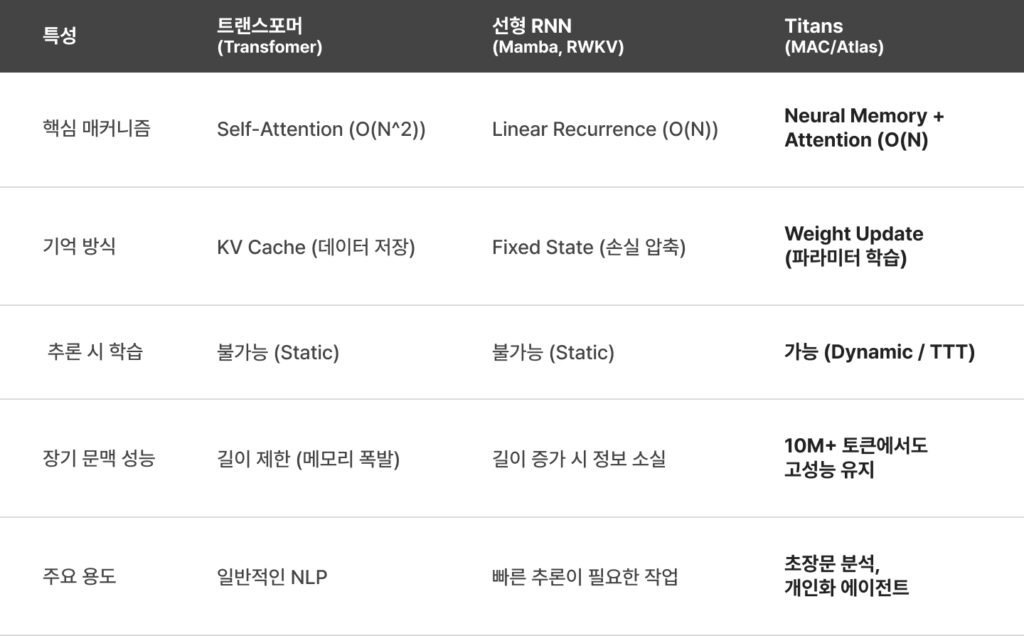
타이탄의 등장은 단순히 새로운 모델의 출시가 아닙니다. 이는 AI가 더 이상 한 번 만들어지면 변하지 않는 ‘고정된 제품(Static AI)’이 아니라, 사용자와 상호작용하며 매 순간 성장하고 진화하는 ‘유기체적 소프트웨어(Organic Software)’의 시대가 열렸음을 선언하는 사건입니다. 이제 AI의 성능은 단순히 얼마나 많은 파라미터를 가졌는지와 같은 하드웨어 스펙 경쟁을 넘어, ‘학습 알고리즘의 효율성’이 결정하는 새로운 시대로 접어들었습니다.



