
The Reason Why Adding Data Can Actually Degrade AI Model Performance

“Why does our model’s performance decrease over time?” This is the most common concern heard at manufacturing sites that have adopted AI. Facing an endless stream of accumulating data and new defect types, model performance becomes unstable, eventually requiring large-scale retraining to boost performance again.
So, why does model performance often decrease when data is added?
Many people believe that model performance improves with more data, but a decline frequently occurs in reality—this is due to Overfitting. When full retraining is repeatedly performed every time new data is added, the model becomes overly exposed to the existing data, which ironically leads to performance degradation.
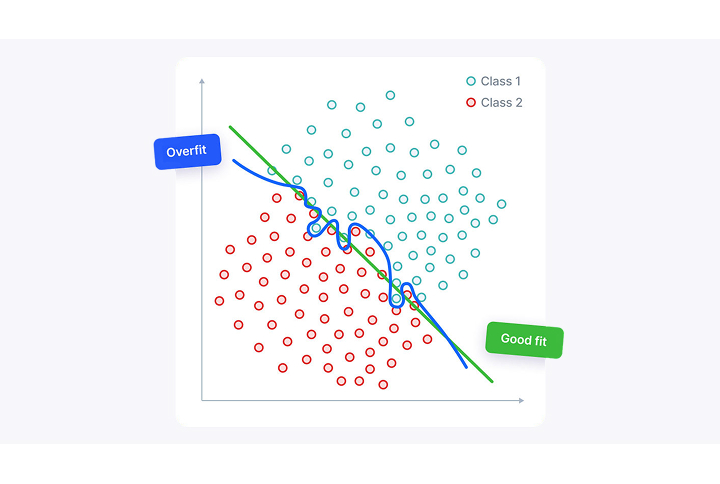
NAVI AI Pro fundamentally solves this problem. The newly added ‘Continual Learning’ feature effectively leverages the weights of the existing model to quickly incorporate new data and defect types.
Let’s now explore the Continual Learning feature, which is the key to solving the chronic problem of AI model performance degradation.
1. The Key to Unlocking the Overfitting Trap: Continual Learning
Continual Learning Overview
To address this issue, NAVI AI PRO applies a Continual Learning approach that involves internal learning algorithm adjustments and data selection based on Confidence Scores. In other words, instead of repeatedly training on the entire dataset, it selects and trains only the data points that the model struggles with, along with newly introduced data that has a potentially high learning difficulty. This prevents overfitting and enables rapid performance improvement.
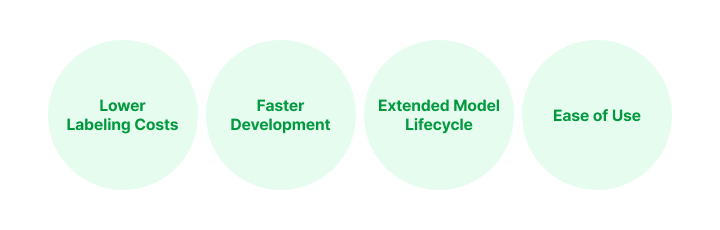
4 Major Benefits
Continual Learning allows users to quickly train the existing model with only new data and defect types in an intuitive environment, providing the following useful benefits:
2. When Continual Learning is Most Needed
CASE 1. When you want to boost performance by adding only new data to an already trained model.
- Conventional Method: The entire dataset is reconstructed, and the model is fully retrained from scratch to reflect the new data.
↓
- Continual Learning Method: Instead of retraining on the entire data, the focus is placed on the new data, drastically reducing the model optimization time.
Data Continual Learning
Data Continual Learning is used to update model performance when new data is added within an existing class. By speeding up training through efficient data sampling and dynamic Learning Rate adjustment, it not only accelerates the learning process but also improves the model’s overall performance and efficiency without overfitting.
- Focus on data increase within existing classes.
- Weight updates without significant model structure changes
- Efficient Data Sampling
- Dynamic Learning Rate adjustment
- Reduced training time (average 60% reduction compared to conventional methods)
- Continuous performance improvement without overfitting
- Faster learning of new patterns or features
- Simple new dataset addition via UI
CASE 2. When a new defect type emerges due to a process issue
- Conventional Method: The entire dataset is reconstructed to include the new defect type, and the model structure itself is modified to recognize the new class.
↓
- Continual Learning Method: The process of reconstructing the dataset by merging existing and new data is simplified by effectively modifying only the classifier part, while maintaining the feature extraction capabilities learned by the existing model, enabling the learning of new data.
Class Continual Learning
Class Continual Learning is a method for rapidly responding to new defect types emerging in manufacturing sites. The core lies in two aspects: Transfer Learning, which maximizes the utilization of existing model knowledge, and data sampling, which maximizes the effect with minimal data. By applying already learned knowledge to new data through Transfer Learning, the model can learn much faster. Adding strategic data sampling maximizes the learning effect without using massive amounts of data. This approach optimizes model performance in a short time and effectively detects new defect types.
- Requires model structure modification due to the addition of a new class
- Preserving existing knowledge while learning new classes
- Maintaining feature extraction capability through Transfer Learning
- Effective modification of the classifier section
- Maintained ability to detect existing defect types
- Effective learning and identification of new defect types
- Simplified model retraining process
- Improved performance compared to conventional methods (quick adaptation to new classes)
- Software features for automatic dataset configuration and model structure modification.
CASE 3. When non-experts need to easily manage retraining and model performance
To retrain a model, one typically had to go through the cumbersome process of reorganizing the data and retraining the entire model from scratch. This process was time-consuming and inevitably placed a greater burden on those without specialized technical knowledge.
NAVI AI PRO simplifies this problem.
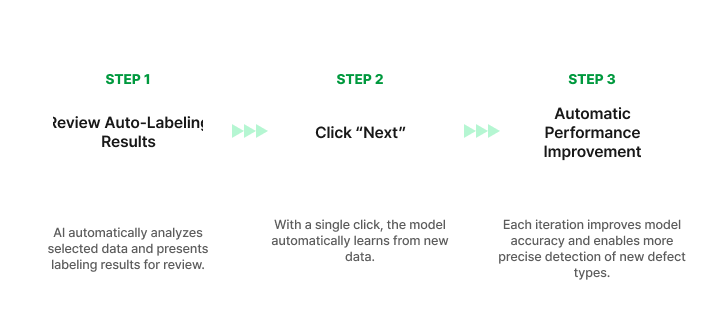
You can maintain and manage the latest model state with just three clicks, without any complex configurations or coding. This is especially easy and beneficial for general users, not just specialized engineers.
Because non-experts can easily retrain and manage the model, field personnel can maintain stable AI operation without technical barriers.
3. Concluding Remarks
While AI adoption in manufacturing sites is increasing, many companies still face the dilemma of data growth leading to performance degradation. NAVI AI PRO was created to solve these fundamental problems.
No longer stress about increasing data. With just 3 clicks, you can immediately respond to new defect types and ensure stable quality control even in unpredictable manufacturing environments!
Now, experience the next level of manufacturing AI with NAVI AI Pro!



Comments
Posts that violate our policies may be removed without prior notice.