
라벨링 없이 이미지를 이해하고 스스로 배우며 학습하는 AI가 있다면 어떨까요?
오늘은 Meta의 VISION AI 모델인 DINOv3를 함께 파헤쳐봅니다.
DINOv3는 사람이 붙인 라벨이 없어도 스스로 시각적 패턴을 학습하는 Self-Supervised Learning 기반의 비전 모델을 말합니다.
단 한 번의 학습으로 다양한 시각 작업에 활용될 만큼 강력한 범용성을 보여주며, 업계에서는 “이미지 인식의 패러다임을 바꾼 모델”로 주목받고 있는데요.
지금부터 DINOv3가 어떻게 스스로 배우고, 이미지를 촘촘히 이해하는지, 그리고 실제 산업 현장에서 어떻게 활용될 수 있는지 하나씩 살펴보겠습니다.
1. Self-Supervised Learning – 라벨 없이 스스로 패턴을 파악하는 AI
우리가 흔히 AI를 가르칠 때, “이 사진엔 고양이가 있다”처럼 사람이 일일이 설명(라벨)을 붙여주는 과정을 거칩니다. 하지만 Self-Supervised Learning(자가 지도 학습)은 이런 귀찮은 라벨링 없이도 AI가 스스로 규칙을 찾아내는 방식을 의미합니다.

즉, AI가 “이 이미지 안에서 어떤 부분이 비슷하고, 어떤 부분이 다른지”를 비교하며 스스로 학습 기준을 만들어내는 거죠. 이렇게 되면 사람의 도움 없이도 인터넷, 위성, 의료, 산업 현장 등 다양한 분야의 방대한 이미지를 학습할 수 있습니다.
DINO 시리즈는 이런 자가 지도 학습의 대표적인 모델입니다. 특히 DINOv3는 이전 버전보다 훨씬 더 큰 규모로 확장되어, 무려 17억 장의 이미지를 이용해 학습했는데요. 이렇게 라벨이 없는 데이터를 대규모로 학습했기 때문에, 특정 분야에 종속되지 않고, 다양한 이미지 도메인에서 우수한 일반화 성능을 보여줄수 있는 것이죠.
그 결과, DINOv3는 “라벨이 없어도 세상의 패턴을 이해하는 AI”로, 인간에 가까운 시각적 이해 능력(Visual Intelligence)에 한 걸음 더 다가섰다고 볼 수 있습니다.
2. Vision Foundation Model – 한 번의 학습으로 어디서나 통하는 범용 모델
우리가 학교에서 수학·과학·언어 등을 배울 때 기본기가 탄탄해야 여러 분야에 응용할 수 있듯이, Foundation Model(파운데이션 모델)도 한 가지 문제만 푸는 것이 아니라 다양한 시각 과제를 두루 잘 풀 수 있는 기본기를 갖춘 모델을 말합니다.
이런 기본기를 갖춘 모델은, 새로운 문제를 만나도 처음부터 다시 배우지 않고 바로 적응할 수 있죠. DINOv3는 바로 이런 ‘비전 파운데이션 모델’을 목표로 만들어졌습니다.
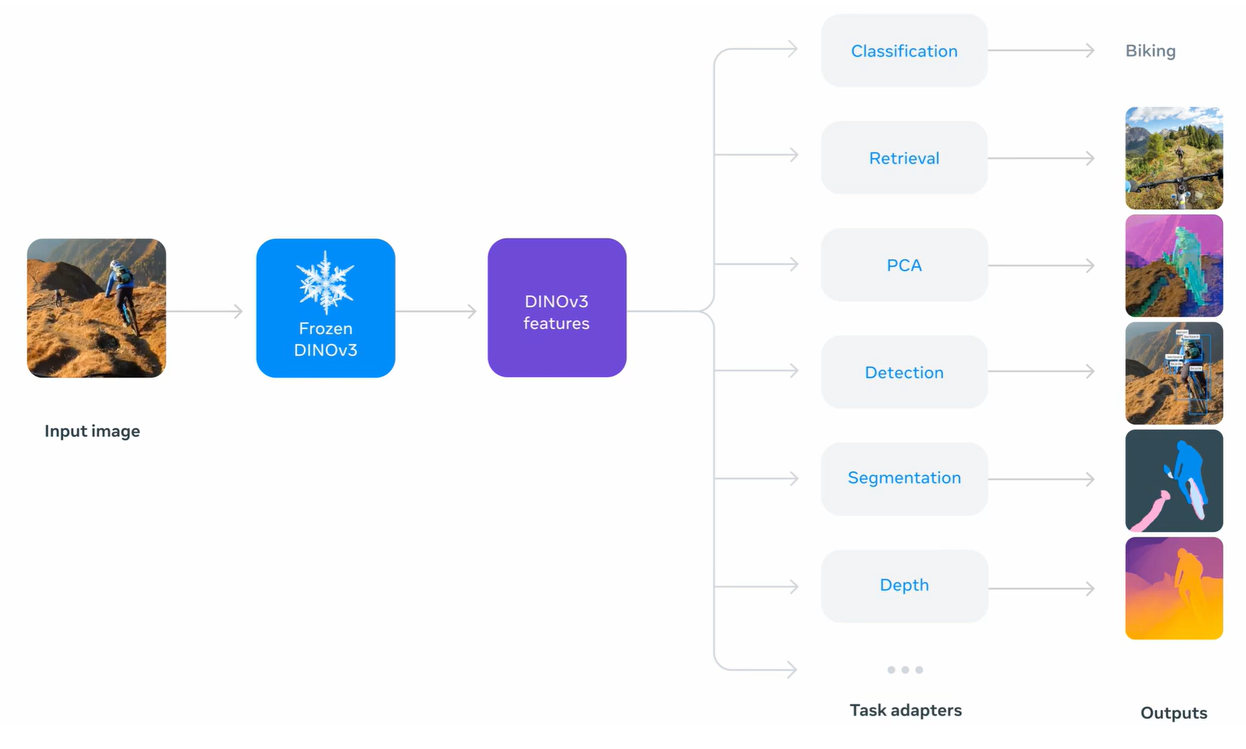
한 번 학습해 두면, 다음과 같은 여러 작업을 추가 학습 없이 수행할 수 있습니다:
- Classification — 이미지 속 사물이 무엇인지 맞히기
- Segmentation — 픽셀 단위로 물체의 경계를 구분하기
- Object Detection — 이미지 속 물체의 위치와 종류 찾기
- Video Tracking — 시간에 따라 물체의 움직임을 따라가기
이전 세대 모델들이 특정 과제에 맞게 따로 fine-tuning(미세 조정) 을 해야 했다면, DINOv3는 별도의 조정 없이도 다양한 설정에서 강력한 성능을 발휘합니다. 진정한 범용 시각 AI에 한 걸음 더 다가선 것이죠.
3. Dense Feature Alignment -‘그림 전체를 촘촘히 이해’하도록 만드는 비법: Gram Anchoring
AI가 이미지를 볼 때 단순히 “이건 고양이야”라고만 이해하는 건 한계가 있습니다. 진짜 똑똑한 모델이라면, 그림 속 모든 부분(픽셀, 패치) 이 어떤 의미를 가지는지도 함께 이해해야 하죠. 이렇게 이미지 전역에서 세밀하게 추출한 정보를 ‘Dense Features(촘촘한 특징)’이라고 부릅니다.
그런데 아이러니하게도, 모델을 크게 키우고 아주 오래 학습시키면 오히려 이 촘촘함이 흐릿해지는 현상이 발생합니다. 다시 말해, 세밀한 구분이 무너지고, 전체적으로 뭉뚱그려보는 경향이 생기는데요.

DINOv3는 이를 해결하기 위해 새로운 정규화 단계인 Gram Anchoring 기법을 도입했습니다. 이 방법은 하나의 이미지 안에 여러 패치들이 서로 얼마나 비슷한지를 기준점(Anchor)으로 잡아, 학습 도중에도 패치 간의 관계를 일정하게 유지하도록 돕습니다.
덕분에 DINOv3는 고해상도 이미지에서도 더 깨끗하고 안정적인 유사도 맵(similarity map)을 만들어낼 수 있습니다. 그 결과, 깊이 추정(Depth Estimation), 3D 매칭(3D Correspondence), 정밀 객체 분할(Segmentation) 같은 세밀한 시각 과제에서 훨씬 뛰어난 성능을 보여줍니다.
4. DINOv3 모델 구조 — 익숙하지만 견고하게 다듬은 설계
DINOv3의 구조를 보면 완전히 새로운 발명이라기보다는, 지금까지 효과가 검증된 여러 기법을 정교하게 조합하고 안정화한 모델이라는 걸 알 수 있습니다. 즉, 익숙한 구성요소들이지만 조립 방식이 훨씬 견고해진 셈이죠.
1. Backbone — ViT와 ConvNeXt를 아우르는 유연한 설계
DINOv3는 기본 네트워크(Backbone)로 Vision Transformer(ViT) 뿐 아니라 ConvNeXt 계열도 지원합니다. 이는 연구 환경뿐 아니라 산업·배포 환경의 다양성까지 고려한 설계로, GPU 자원이 한정된 상황에서도 유연하게 활용할 수 있습니다. 공식 허브와 GitHub에는 이미 사전 학습된 가중치(pretrained weights)가 공개되어 있어, 개발자는 이를 다양한 작업에 적용할 수 있습니다.
2. Self-Distillation — ‘학생-교사’ 구조로 안정적인 학습
DINOv3는 학습 중에 학생(Student)과 교사(Teacher) 네트워크를 함께 사용합니다. 학생은 다양한 크롭 이미지(여러 시야, 해상도)를 보며 학습하고, 교사는 학생의 파라미터를 EMA(Exponential Moving Average, 지수 이동 평균)로 부드럽게 따라갑니다. 이 과정에서 교사는 안정적인 목표(soft target)를 제공하고, 학생은 그 목표를 모방하면서 점점 더 견고한 표현을 배우게 되죠. 결국 대형 7B 파라미터의 교사 → 소형 학생 모델로 지식이 증류(distilled)되어, 성능과 효율을 모두 잡은 구조로 완성됩니다.
3. Multi-Crop Strategy — 다양한 시야에서 배우는 시각적 유연성
한 이미지를 여러 해상도와 시야(global/local crops)로 잘라 학습시키는 멀티-크롭 전략을 사용합니다. 이 덕분에 모델은 크기가 달라도, 시점이 달라도 본질을 인식할 수 있는 표현력을 얻게 됩니다. 즉, DINOv3는 “멀리서 보나, 가까이서 보나 같은 물체임을 알아보는” 시각적 감각을 스스로 익히는 셈이죠.
4. Masking & Self-Prediction — 보이지 않는 걸 스스로 예측하기
DINOv3는 iBOT 스타일의 자기예측(Self-Prediction) 기법도 함께 사용합니다. 이미지의 일부 패치를 가리고(masking), 나머지 정보를 바탕으로 가려진 부분을 예측하게 만드는 방식입니다. 이 과정을 통해 모델은 이미지 구조와 맥락을 깊이 이해하는 능력을 키우게 됩니다.
요약하자면, DINOv3는 새롭기보다 “완성형에 가까운 설계”입니다. 검증된 요소들을 정교하게 엮어 안정성·효율성·일반화 모두를 극대화한 비전 파운데이션 모델이죠.
5. DINOv3 모델 활용 – 라벨이 적어도, 프로토타이핑에서 실사용까지 빠르게
DINOv3는 단순히 연구용 모델을 넘어, “라벨이 부족한 현실 환경에서도 빠르게 시작할 수 있는 범용 시각 엔진”으로 설계되었습니다. 즉, 소량의 데이터만 있어도 강력한 시각 기반 AI를 빠르게 만들어볼 수 있습니다.
1. Few-shot / 저라벨 환경에서도 강한 출발점
DINOv3의 핵심 강점은 사전 학습된 백본(backbone)의 표현력이 매우 뛰어나다는 점입니다. 그래서 전체 모델을 다시 학습할 필요 없이, 백본은 그대로 동결(frozen)하고 위에 얇은 헤드(예: 선형 분류기, MLP 등)만 얹어도 분류(Classification), 세그멘테이션(Segmentation), 깊이 추정(Depth Estimation) 등 여러 과제에서 훌륭한 성능을 냅니다. 특히 Dense Feature 품질이 좋아진 덕분에, 픽셀 단위로 세밀한 구분이 필요한 세그멘테이션이나 3D 정합(3D matching)작업에 매우 유리합니다.
2. 프로덕션 고려 — 엣지부터 서버까지 폭넓은 선택
DINOv3는 실제 배포 환경까지 염두에 두고 설계되었습니다.
공개된 모델군은 다음과 같이 다양합니다:
- ViT 시리즈: Small / Base / Large / Huge+
- ConvNeXt 시리즈: Tiny ~ Large
즉, 엣지 디바이스(경량 환경)에서부터 서버급 GPU(고성능 환경)까지 상황에 맞는 모델을 손쉽게 선택하고 배치(deploy)할 수 있습니다.
3. 오픈소스 생태계와의 완벽한 연결
DINOv3는 PyTorch Hub, Hugging Face Transformers, GitHub 등 주요 오픈소스 플랫폼과 완전히 통합되어 있습니다. 덕분에 개발자는 다음과 같은 활용이 가능합니다:
- 즉시 임베딩 추출(Feature Embedding)
- 다른 모델과의 조합 실험 (예: CLIP, SAM 등)
- 공식 예제 코드 + 사전학습 가중치 바로 불러오기
즉, 연구용 실험부터 산업용 프로토타이핑까지 “라벨 없이도 바로 써먹을 수 있는 실전형 비전 모델”이 바로 DINOv3라고 할 수 있습니다.
마무리 — DINOv3가 보여주는 ‘스스로 배우는 시각지능’의 방향
DINOv3는 단순히 “또 하나의 새로운 모델”이 아닙니다. 인간의 개입 없이 스스로 시각 세계를 이해해 나가는 AI, 즉 시각 지능(Visual Intelligence)의 진화를 보여주는 이정표입니다.
라벨링이 없이 수십억 장의 이미지를 학습하고, 단 한 번의 학습으로 분류 · 세그멘테이션 · 3D 인식 등 다양한 과제에 바로 적응하는 DINOv3의 모습은 AI가 인간에 가까운 방식으로 세상을 관찰하고 해석하는 시대가 도래했음을 시사합니다.
이제 우리는 DINOv3 같은 파운데이션 모델을 기반으로,
적은 데이터로도 빠르게 프로토타입을 만들고,
현실의 문제를 해결하는 ‘고효율의 AI 개발 시대’로 진입하고 있습니다.




댓글
운영 정책에 반하는 글은 사전 고지 없이 삭제될 수 있습니다.