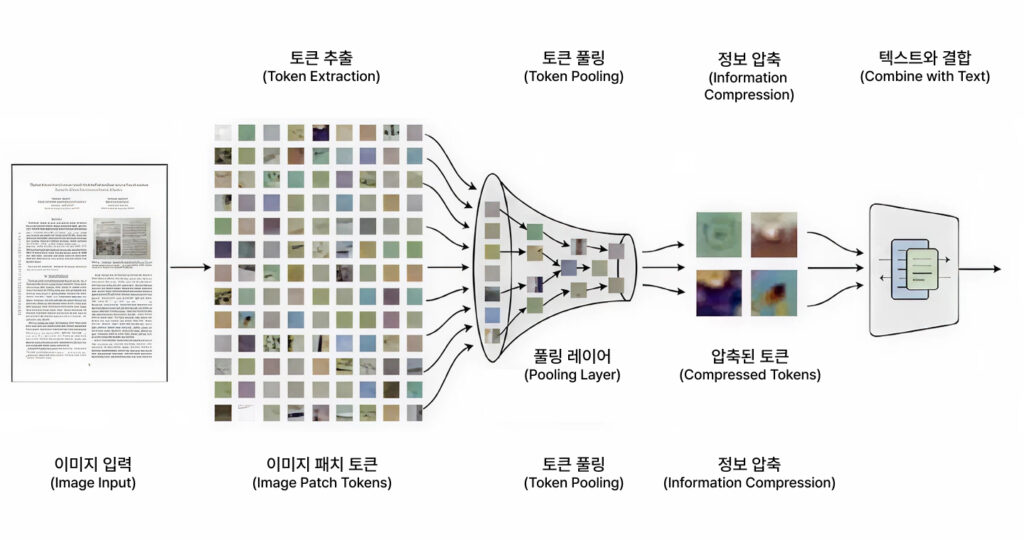
YOLO26: 엣지 AI의 판을 바꾸는 새로운 표준
엣지 컴퓨팅 시대의 새로운 패러다임, YOLO26의 등장
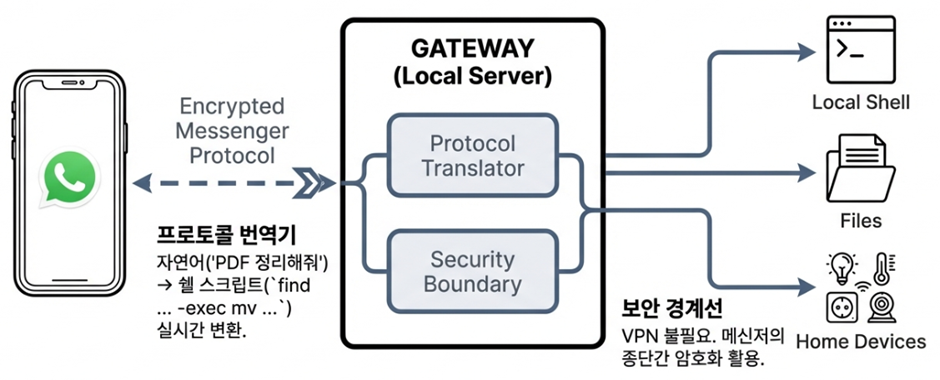
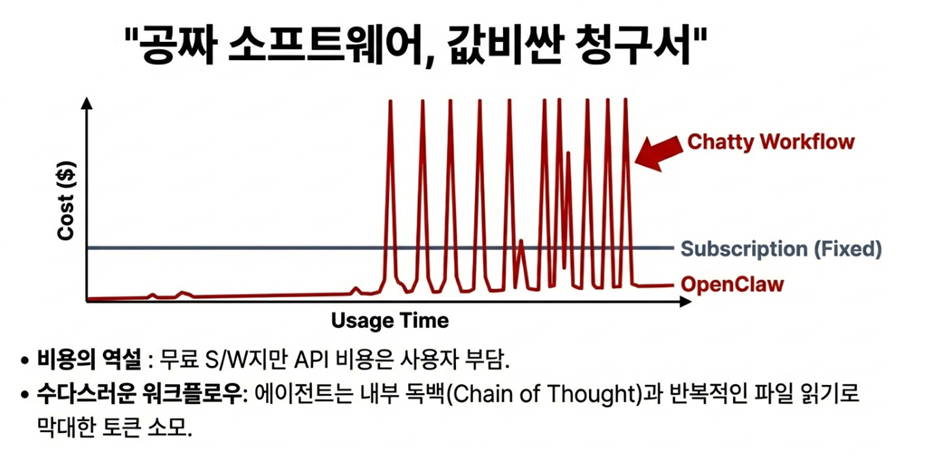
2026년 1월, 드디어 베일을 벗은 YOLO26은 그동안의 AI 개발 트렌드와는 정반대의 길을 선택했습니다. 지난 수년간 더 정확한 모델을 만들기 위해 구조를 복잡하게 쌓아 올리는 것이 유행이었지만, YOLO26은 과감하게 ‘다이어트’를 선언했습니다. 바로 현장에서 가장 환영받는 ‘엣지 우선(Edge-first)’ 철학을 담기 위해서입니다.
YOLO26의 가장 큰 매력은 단순히 시험 점수(벤치마크)만 잘 나오는 모범생이 아니라는 점입니다. 연구실의 고성능 컴퓨터가 아닌, 공장의 저전력 칩이나 로봇의 두뇌(ARM CPU)에서도 쌩쌩 돌아가는 ‘실전형 인재’에 가깝습니다. 그동안 개발자들을 괴롭혔던, 연구실 모델을 현장 장비로 옮길 때 발생하는 골치 아픈 호환성 문제(배포 마찰)를 획기적으로 줄여주었기 때문입니다.
이번 글에서는 YOLO26이 어떻게 군더더기를 걷어내고 구조를 단순화했는지, 그리고 거대 언어 모델(LLM)의 똑똑한 학습법을 빌려와 성능까지 놓치지 않았는지 자세히 살펴보려 합니다. 왜 2026년 이후의 비전 AI 프로젝트들이 YOLO26을 표준으로 삼게 될지, 그 혁신의 이면을 함께 들여다보겠습니다.
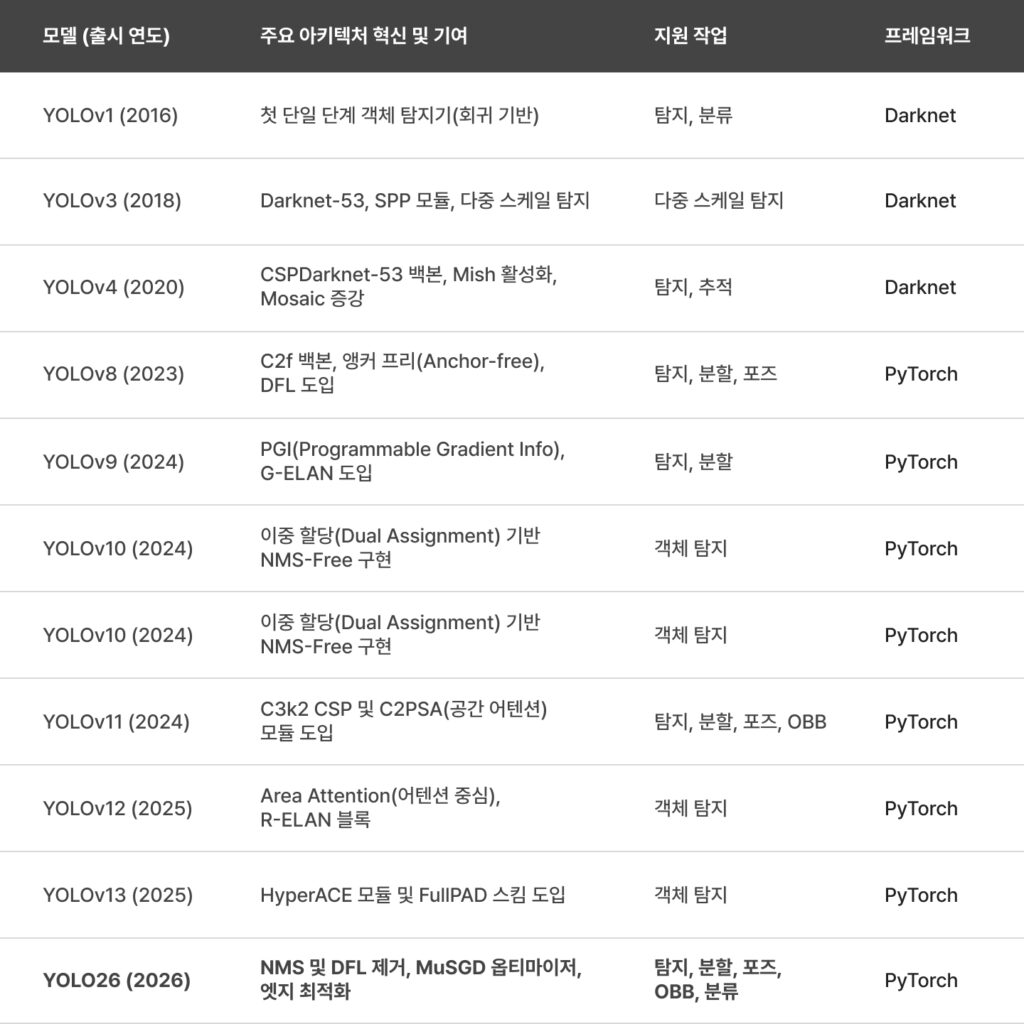
1. YOLO의 진화와 기술적 부채의 청산
YOLO 프레임워크는 2016년 YOLOv1이 등장한 이래 수많은 변천을 거쳤습니다. 그러나 정확도를 위해 도입된 복잡한 그래프 구조와 특정 하드웨어 가속기에서 오버헤드를 유발하는 연산들은 일종의 ‘기술적 부채’로 작용해 왔습니다. YOLO26은 이러한 복잡성을 과감히 덜어내고 엣지 환경에 최적화된 구조로 회귀했습니다.
2. 아키텍처 혁신: 엣지 최적화를 위한 4대 핵심 기술
2-1. 엔드-투-엔드 NMS-Free 추론 및 Jitter 제거
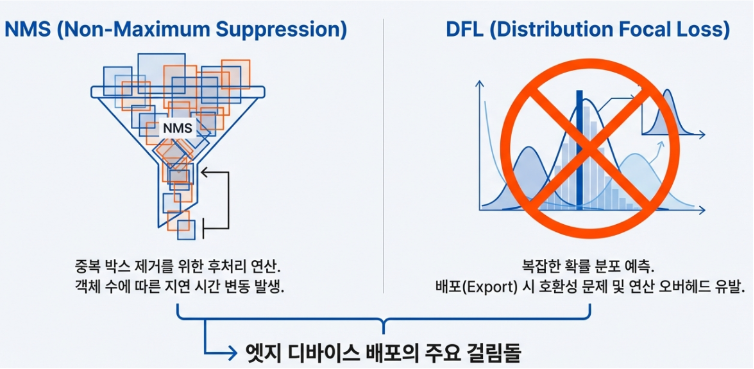
객체 탐지(Object Detection) 모델을 현업에 적용해 본 개발자라면, 모델이 만들어 내는 수많은 중복 박스를 처리하는 과정이 얼마나 번거로운지 공감하실 겁니다. 그동안 우리는 ‘NMS(Non-Maximum Suppression)’라는 후처리 단계에 의존해, 겹쳐진 수많은 예측 박스 중 진짜 정답 하나를 골라내는 작업을 필수적으로 거쳐야 했습니다. 하지만 최신 모델인 YOLO26은 이 복잡한 과정을 과감히 없애고, 입력에서 결과까지 막힘없이 이어지는 진정한 ‘엔드-투-엔드(End-to-End)’ 추론을 구현했습니다.

YOLO26의 핵심은 모델이 더 이상 “일단 많이 던져보고 나중에 거르는” 방식을 쓰지 않는다는 데 있습니다. 대신, 학습 단계부터 하나의 물체당 오직 하나의 정답 박스만을 예측하도록 훈련받습니다. 이를 위해 모델의 가장 끝단인 예측 헤드(Head)를 재설계하여 중복 없는 결과를 직접 출력하게 만들었죠. 덕분에 추론 단계에서 별도의 NMS 과정이 아예 불필요해졌습니다.
또한, 모델 경량화를 위해 좌표 계산 방식도 단순화했습니다. 기존에는 정밀도를 높이기 위해 복잡한 확률 분포 계산(DFL)을 사용했지만, YOLO26은 이를 걷어내고 하드웨어가 더 빨리 처리할 수 있는 직관적인 방식을 채택했습니다. 물론, 이에 따른 정확도 손실은 새로운 학습 기법들을 통해 효과적으로 보완했습니다.
결과는 매우 인상적입니다. 무거운 NMS 연산이 사라지니 CPU 처리 속도가 이전 모델 대비 40% 이상 빨라졌습니다. 무엇보다 이미지 속 물체가 많아져도 처리 시간이 들쑥날쑥하지 않고 일정하게 유지됩니다. 이는 추론 파이프라인을 단순화시켜 연산 자원이 제한된 엣지 디바이스에서도 훨씬 빠르고 안정적인 성능을 가능하게 합니다. 특히 실시간 제어 루프가 필수적인 로보틱스와 자율 주행 시스템에 결정적인 이점을 제공하죠.
복잡한 후처리 코드가 사라진 덕분에 다른 플랫폼으로 모델을 변환할 때 겪던 호환성 문제도 크게 줄어들었습니다. 이제 개발자들은 YOLO26을 통해 더 빠르고, 더 깔끔하게 AI 비전을 구현할 수 있게 되었습니다.
2-2. 분포 초점 손실(DFL)의 과감한 제거
이전 세대인 YOLOv8이나 YOLO11은 객체의 위치를 아주 정밀하게 맞추기 위해 ‘DFL(Distribution Focal Loss, 분포 초점 손실)’이라는 기술을 사용했습니다. 쉽게 말해, 바운딩 박스의 좌표를 딱 떨어지는 숫자 하나로 단정 짓지 않고, 확률적인 분포로 예측해 위치가 모호한 객체까지 잡아내려던 시도였죠. 하지만 이 방식은 정확도는 높여주지만, 계산 과정이 복잡해 추론 속도를 늦추고 다른 플랫폼으로 모델을 변환할 때 호환성을 떨어뜨리는 주원인이 되곤 했습니다.
YOLO26은 과감하게 이 DFL을 걷어냈습니다. 복잡한 확률 계산을 버리고, 좌표를 직접 예측하는 단순하고 직관적인 ‘직접 회귀’ 방식으로 돌아간 것입니다. 덕분에 모델의 구조는 훨씬 단순해졌고, 어떤 하드웨어에서도 가볍고 빠르게 돌아가는 유연함을 얻게 되었습니다. 물론, 방식이 단순해진 만큼 정밀도가 떨어질까 걱정될 수 있습니다. YOLO26은 이 문제를 ‘똑똑한 학습 전략’으로 완벽하게 보완했습니다.
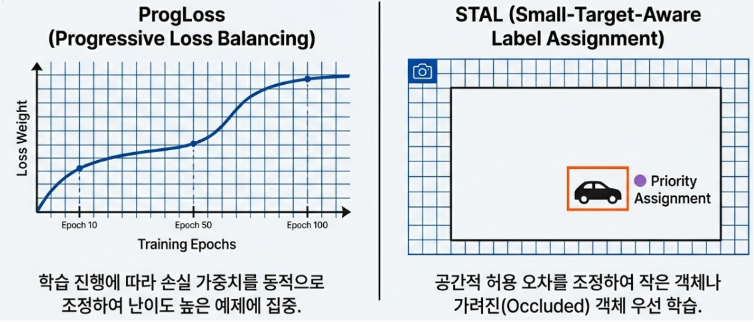
먼저, 학습이 진행될수록 모델이 풀기 어려운 문제에 더 집중하도록 유도하는 ‘ProgLoss’를 도입해 전반적인 성능을 끌어올렸습니다. 또한, 기존 모델들이 자주 놓치던 아주 작거나 가려진 객체를 위해 ‘STAL’이라는 기술을 적용하여, 작은 물체도 놓치지 않고 학습하도록 만들었죠. 여기에 대규모 언어 모델(LLM)의 학습법에서 영감을 받은 ‘MuSGD’ 최적화 도구까지 더해 학습 속도와 안정성을 동시에 확보했습니다.
결론적으로 YOLO26은 실행(Inference) 단계의 무거운 짐은 덜어내어 속도를 높이고, 대신 학습(Training) 단계를 훨씬 정교하게 설계하여 정확도 손실을 막았습니다. 개발자 입장에서는 더 가볍고 호환성 좋은 모델을 쓰면서도, 성능은 오히려 더 뛰어난 경험을 할 수 있게 된 것입니다.
2-3. ProgLoss 및 STAL: 소형 객체 탐지의 정밀화
YOLO26이 복잡한 연산 장치(DFL, NMS)를 과감히 떼어내고도 여전히, 아니 오히려 더 날카로운 탐지 능력을 보여주는 비결은 무엇일까요? 그 해답은 바로 모델을 훈련시키는 과정, 즉 ‘학습(Training)’ 단계에 숨겨진 두 가지 혁신적인 조력자, ProgLoss와 STAL 덕분입니다. 이들은 모델이 쉬운 문제에 안주하지 않도록 채찍질하고, 가장 어려워하는 부분을 집중적으로 과외하는 선생님과 같습니다.
일반적으로 AI 모델은 학습이 반복될수록 맞히기 쉬운 크고 선명한 물체에만 집중하려는 경향을 보입니다. 마치 학생이 시험 공부를 할 때 쉬운 문제만 골라 풀며 점수를 유지하려는 것과 비슷하죠. 이때 등장하는 기술이 바로 ‘점진적 손실 균형(ProgLoss)’입니다. ProgLoss는 학습 진행 상황에 맞춰 채점 기준(가중치)을 실시간으로 바꿉니다. 모델이 쉬운 예제에 적응해 나태해지려 할 때마다, 아직 정복하지 못한 까다로운 케이스들에 더 큰 비중을 두어 끝까지 긴장감을 놓지 않고 학습하게 만듭니다. 덕분에 모델은 특정 데이터에 편식하지 않고 전체적인 균형 감각을 갖추게 됩니다.
하지만 전체적인 균형만으로는 부족합니다. 화면 속의 점처럼 작거나 흐릿한 물체들은 여전히 AI에게 가장 풀기 어려운 난제이기 때문입니다. 여기서 ‘소형 대상 인식 라벨 할당(STAL)’이 해결사로 나섭니다. STAL은 픽셀 정보가 턱없이 부족해 기존 모델들이 무시하기 쉬웠던 ‘작은 객체’들에게 우선순위를 부여합니다. 작은 물체 주변의 정답 인정 범위를 유연하게 조정해 줌으로써, 모델에게 “이 작은 점도 놓쳐선 안 될 중요한 정답이야”라고 강력한 신호를 보내는 것이죠.
결국 ProgLoss가 모델이 쉬운 길로 빠지지 않게 전체적인 학습 밸런스를 잡아주는 감독관이라면, STAL은 모델의 가장 큰 약점인 ‘작은 물체’를 놓치지 않도록 돕는 족집게 과외 선생님인 셈입니다. 이 두 기술의 완벽한 협업 덕분에 YOLO26은 무거운 연산 과정을 덜어내고도, 드론 영상이나 의료 정밀 진단처럼 작은 디테일이 생명인 분야에서 압도적인 성능을 발휘할 수 있게 되었습니다.
2-4. MuSGD 옵티마이저: LLM 기술의 성공적인 이식
YOLO26이 구조는 단순해졌는데 성능은 더 좋아진 비결, 그 마지막 퍼즐 조각은 바로 학습을 담당하는 ‘최적화 도구(Optimizer)’에 있습니다. 재미있게도 YOLO26은 최근 AI 업계를 뜨겁게 달구고 있는 거대 언어 모델(LLM)의 학습 비법을 빌려왔습니다. 바로 MuSGD라는 새로운 옵티마이저입니다.
기존에 흔히 쓰이던 AdamW 같은 도구들은 파라미터를 하나하나 개별적으로 수정하는 방식을 취했습니다. 하지만 이 방식은 종종 학습 방향이 이리저리 흔들리거나, 최적의 답을 찾는 데 오랜 시간이 걸리곤 했습니다. 반면 MuSGD는 Kimi K2 모델 등 LLM 학습에 쓰이던 강력한 수학적 기법인 ‘뉴턴-슐츠 반복법’을 도입해 이 문제를 해결했습니다. 쉽게 비유하자면, 숲속에서 길을 찾을 때 나무 하나하나를 보며 헤매는 대신, 나침반을 이용해 가장 빠른 직선 경로(학습 방향)를 수학적으로 정렬해 버리는 것과 같습니다. 이를 전문 용어로 ‘행렬 직교화’라고 하는데, 덕분에 모델은 불필요한 시행착오 없이 정답을 향해 직진할 수 있게 됩니다.
이 기술이 YOLO26에게 특히 중요한 이유는 모델의 ‘다이어트’ 때문입니다. 앞서 언급했듯 YOLO26은 몸집을 가볍게 하기 위해 복잡한 안전장치(DFL)를 제거했습니다. 자칫하면 학습이 불안정해질 수 있는 상황에서, MuSGD가 강력한 길잡이가 되어준 것입니다. 덕분에 개발자들은 복잡한 파라미터 튜닝 없이도 더 빠르고 안정적으로 모델을 학습시킬 수 있게 되었습니다. 결국 MuSGD는 가벼워진 YOLO26이 거대 모델 못지않은 똑똑함을 가질 수 있게 만든 숨은 공신이라 할 수 있습니다.
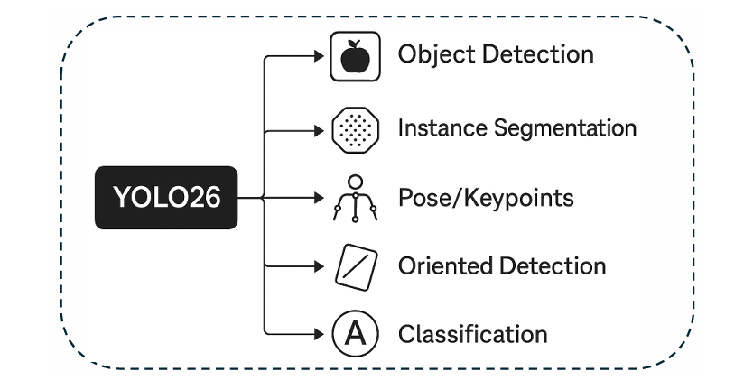
3. 다중 작업(Multi-task) 통합 프레임워크
YOLO26은 단일 백본을 통해 5가지 핵심 비전 작업을 지원하며 각 작업에 특화된 모듈을 통합했습니다.
- Object Detection: 앵커 프리 및 엔드-투-엔드 NMS-free 방식.
- Instance Segmentation: Multi-scale Proto Module과 시맨틱 분할 손실을 결합- 하여 정교한 마스크 경계 생성.
- Pose/Keypoints Estimation: 잔차 로그-우도 추정(RLE) 기법을 통합하여 복잡한 관절 위치의 불확실성을 관리.
- Oriented Detection (OBB): 특화된 각도 손실(Angle Loss) 적용으로 회전된 객체의 정밀 탐지.
- Classification: ImageNet 기반의 고효율 헤드를 통한 초고속 분류 지원.
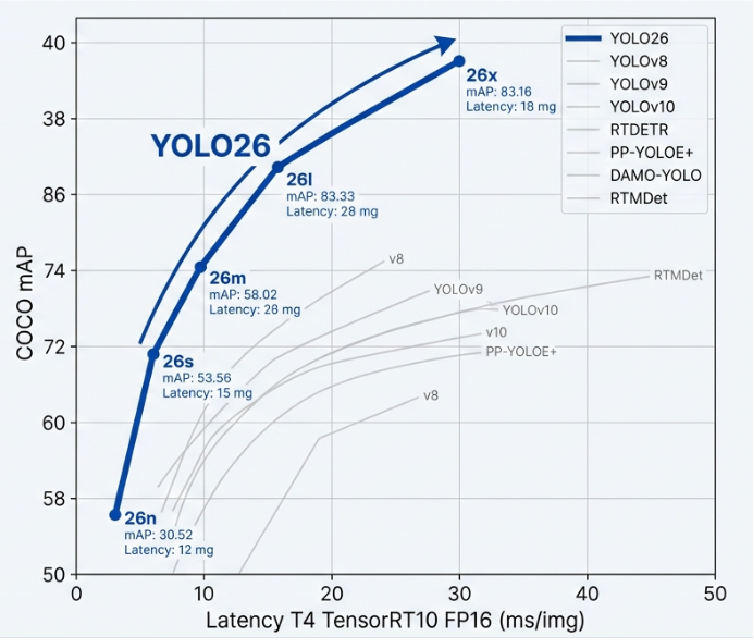
4. 성능 벤치마크: 속도와 정확도의 압도적 균형
YOLO26이 단순히 이름만 바뀐 후속작이 아니라는 사실은, 직전 모델인 YOLO11과 비교해 보면 명확해집니다. 가장 가벼운 모델인 Nano 버전을 기준으로 볼 때, YOLO26은 YOLO11보다 정확도는 더 높으면서도 속도는 무려 40% 이상 빨라졌습니다. 이는 마치 자동차의 엔진 성능은 올리면서 차체 무게는 줄인 것과 같습니다. 특히 라즈베리 파이 같은 저사양 기기에서도 쾌적하게 돌아간다는 점은 현장 개발자들에게 매우 매력적인 요소입니다.
YOLOv12나 v13 같은 고성능 모델들과 비교하면 YOLO26의 ‘실용주의’ 철학이 더 돋보입니다. 경쟁 모델들은 정확도를 높이기 위해 복잡한 최신 기술들을 대거 도입했지만, 그 탓에 모델이 무거워지고 특정 하드웨어에서는 제 성능을 내기 힘든 경우가 많았습니다. 반면, 구조를 단순화한 YOLO26은 모바일이나 엣지 디바이스용으로 변환(Quantization)해도 성능 저하가 거의 없고, 어떤 환경에서든 안정적으로 작동합니다.
흥미로운 점은 최근 유행하는 트랜스포머 기반 모델(RT-DETR)과의 대결입니다. 일반적으로 트랜스포머 모델이 문맥 파악 능력이 뛰어나다고 알려져 있지만, YOLO26은 속도 면에서 이들을 압도합니다. 비슷한 정확도를 내면서도 처리 속도는 두 배 가까이 빠르죠. 결국 YOLO26은 복잡한 유행을 쫓기보다, ‘일정한 응답 속도(Deterministic Latency)’와 ‘호환성’이라는 기본기에 집중했습니다. 자율 주행차처럼 0.01초의 지연도 허용되지 않는 시스템에서, 예측 가능한 속도를 보장한다는 것은 그 어떤 화려한 기능보다 강력한 무기이기 때문입니다.
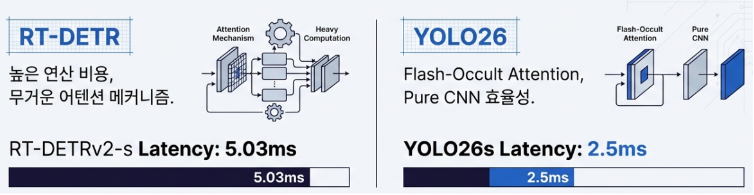
[참고: 모델 성능 요약 (COCO 데이터셋 기준)]

5. 실전 배포 및 산업별 활용 전략
5-1. 유연한 내보내기 및 양자화 강점
YOLO26은 ONNX, TensorRT, CoreML, TFLite 등 모든 주요 포맷을 지원합니다. 특히 아키텍처 단순화(DFL 제거 등) 덕분에 INT8/FP16 양자화 시 가중치 민감도가 낮아 정밀도 하락이 최소화됩니다. 이는 하드웨어 컴파일러와의 충돌을 방지하고 안정적인 산업용 배포를 가능케 합니다.
5-2. 산업별 적용 시나리오
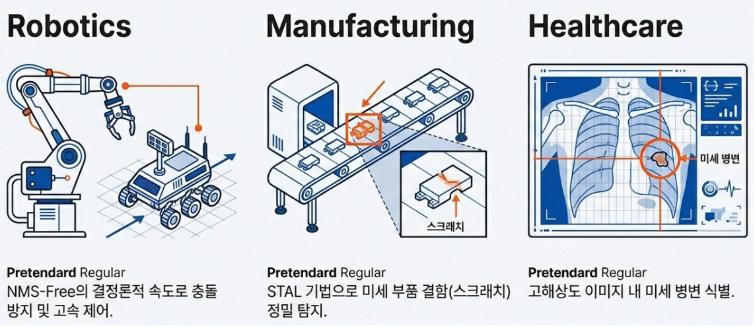
- 자율 주행 및 로보틱스: NMS 제거를 통해 객체 밀집도와 관계없이 일정한 응답 시간을 보장, 실시간 제어 안정성 확보.
- 스마트 팩토리: 저사양 CPU 임베디드 장치에서도 초당 25프레임 이상의 결함 검수를 실시간 수행하여 구축 비용 절감.
- 의료 및 항공 이미지: STAL 알고리즘을 활용하여 엑스레이 병변이나 원거리 드론 영상의 미세 객체를 고정밀 탐지.
6. 결론 및 향후 전망: 2026년 이후의 비전 AI
YOLO26의 등장은 단순한 버전 업그레이드를 넘어, 객체 탐지 기술의 패러다임이 ‘복잡한 연산’에서 ‘똑똑한 학습’으로 이동하고 있음을 시사합니다. 이를 바탕으로 향후 YOLO 시리즈의 발전 방향을 세 가지로 전망해 볼 수 있습니다.
첫째, ‘엔드-투-엔드(End-to-End)’ 구조의 표준화입니다. YOLO26이 증명했듯, 골치 아픈 후처리(NMS)를 없애는 것은 속도와 정확도 두 마리 토끼를 잡는 가장 확실한 방법이 되었습니다. 앞으로 나올 YOLO 모델들은 NMS-free 방식을 기본으로 채택하여, 입력 이미지를 넣으면 중간 과정 없이 즉시 정답 좌표가 나오는 완전한 직관형 모델로 진화할 것입니다.
둘째, ‘엣지 디바이스 친화적 설계’의 가속화입니다. 무거운 GPU가 없는 환경에서도 돌아갈 수 있도록 모델을 경량화하는 추세는 더욱 강해질 것입니다. 단순히 모델 크기만 줄이는 것이 아니라, YOLO26처럼 하드웨어 가속기(NPU)가 좋아하는 단순한 연산 구조를 채택하여 실질적인 체감 속도를 높이는 방향으로 발전할 것입니다. 이는 로봇, 드론, 모바일 기기 등 산업 현장 곳곳에 AI의 눈을 심는 기폭제가 될 것입니다.
마지막으로, ‘비전-언어 모델(VLM)과의 단계적 융합’입니다. 현재의 YOLO는 학습된 사물만 찾을 수 있는 Closed-set 탐지에 머물러 있지만, 미래의 YOLO는 거대 AI 모델의 효율성을 높이고, 스스로 언어를 이해하는 방향으로 진화할 것입니다.
마지막으로, ‘비전-언어 모델(VLM)과의 단계적 융합’입니다. 현재의 YOLO는 학습된 사물만 찾을 수 있는 Closed-set 탐지에 머물러 있지만, 미래의 YOLO는 거대 AI 모델의 효율성을 높이고, 스스로 언어를 이해하는 방향으로 진화할 것입니다.
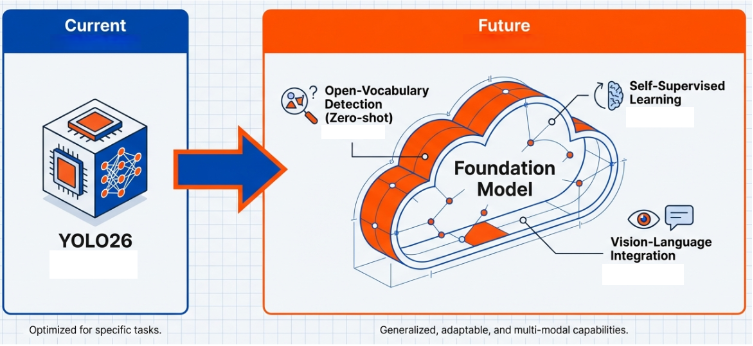
우선, YOLO는 무거운 VLM의 연산 부하를 획기적으로 줄여주는 ‘실시간 프리 필터(Pre-filter)’ 역할을 수행하게 될 것입니다. 모든 이미지 처리를 거대 모델에 맡기는 것은 비용과 속도 면에서 비효율적입니다. 따라서 빠르고 가벼운 YOLO가 먼저 관심 객체의 위치를 1차적으로 걸러내고, VLM은 선별된 영역만 깊이 있게 분석하는 ‘하이브리드 파이프라인’이 보편화될 것입니다. 이를 통해 시스템 전체의 추론 속도를 확보하면서도 VLM의 고도화된 인식 능력을 활용할 수 있습니다.
좀 과한 전망일 수도 있지만, 더 나아가, YOLO는 ‘오픈 어휘 탐지(Open-Vocabulary Detection)’ 능력을 자체적으로 갖춘 모델로 진화할 것입니다. 텍스트로 “빨간 모자를 쓴 사람을 찾아줘”라고 명령하면, 별도의 추가 학습 없이도(Zero-shot) 즉시 대상을 찾아내는 방식입니다. 이를 위해 자기 지도 학습(Self-supervised Learning)과 CNN, 트랜스포머의 장점을 결합한 지능형 하이브리드 아키텍처가 도입될 것입니다.
결국 YOLO는 단순한 객체 탐지기를 넘어, 범용 비전 파운데이션 모델(Vision Foundation Model)로 거듭날 것입니다. 인간의 언어를 이해하고 맥락을 파악하는 거대 AI 에이전트의 빠르고 정확한 ‘눈’이 되는 것, 그것이 바로 YOLO가 나아갈 미래입니다.