기존 지능형 CCTV의 치명적 한계
‘지능형이라고 쓰고, 무능형이라고 읽는다.’
지금까지의 지능형 CCTV는 과연 지능적이 었을까요? 정답은 반은 맞고, 반은 틀리다 입니다. 실제로 기존 지능형 영상 관제 시스템의 기술적 진보는 딥러닝 디텍션을 활용한 객체 인식에 집중돼 있었습니다. 그래서 사실상 ‘반쪽짜리 지능형 관제’에 불과했죠. 즉, 사람, 차량, 화재와 같은 객체를 감지할 수는 있지만, 그 장면이 왜 중요한지, 지금 무슨 일이 벌어지고 있는지 이해하는 건 불가능 했습니다.
‘현실판 양치기 소년이 된 지능형 CCTV’
“CCTV가 쓰러진 사람을 감지한다.” 는 말은 그럴듯하게 들리지만, 현장에서는 조금 다른 얘기가 펼쳐집니다.

실제로는 앉아 있는 사람을 쓰러진 것으로 잘못 판단하거나, 그림자와 배경을 사람으로 착각하는 일이 자주 일어납니다. 이런 상황이 반복되면 어떤 일이 벌어질까요? 처음엔 놀라서 달려가던 관제 요원도, 나중엔 “또 저 CCTV야…” 하며 무심히 넘기게 됩니다. 진짜 문제는 그 다음입니다. 실제로 위험 상황이 생겨도 “또 오탐이겠지” 하고 지나칠 수 있다는 점이죠.
‘객체는 보지만 상황은 모른다’
이런 문제가 반복되는 이유는 무엇일까요? 바로 기존 CCTV 분석 시스템이 사용하는 YOLO, SSD와 같은 CNN 기반 딥러닝 모델의 근본적인 한계 때문입니다.
- 빈번한 오탐/미탐
– 배경이 어둡거나 복잡하면 객체 인식률 급격히 하락
– 시간대별로 변화하는 환경(동틈, 해질녘, 야간 빛번짐, 우천, 안개 등)에 따라 상이한 정확도 - 정적인 객체 존재만 인식
– “사람이 있다/없다”와 같은 객체의 존재 여부만 파악
– 실제 그 사람이 무엇을 하고 있는지, 어떤 의도로 행동하는지는 분석 불가 - 사전 룰(rule)에 의존
– 미리 정해진 조건 안에서만 정확한 판단 가능
– 새로운 패턴이나 예외적인 상황에서 대응력 부족

단순히 ‘보는 것’을 넘어, ‘상황을 이해하는’ 시스템으로
그렇다면 해답은 무엇일까요?
단순히 눈앞의 대상을 인식하는 데 그치지 않고, 상황의 맥락을 이해하는 관제 시스템이 필요합니다.
여기서 등장하는 것이 바로 Odin AI입니다.
Odin Ai는 단순히 “사람이 있다 / 없다”를 구분하는 수준을 넘어, 객체 간의 관계, 장면의 맥락, 행동의 의도까지 해석할 수 있습니다.
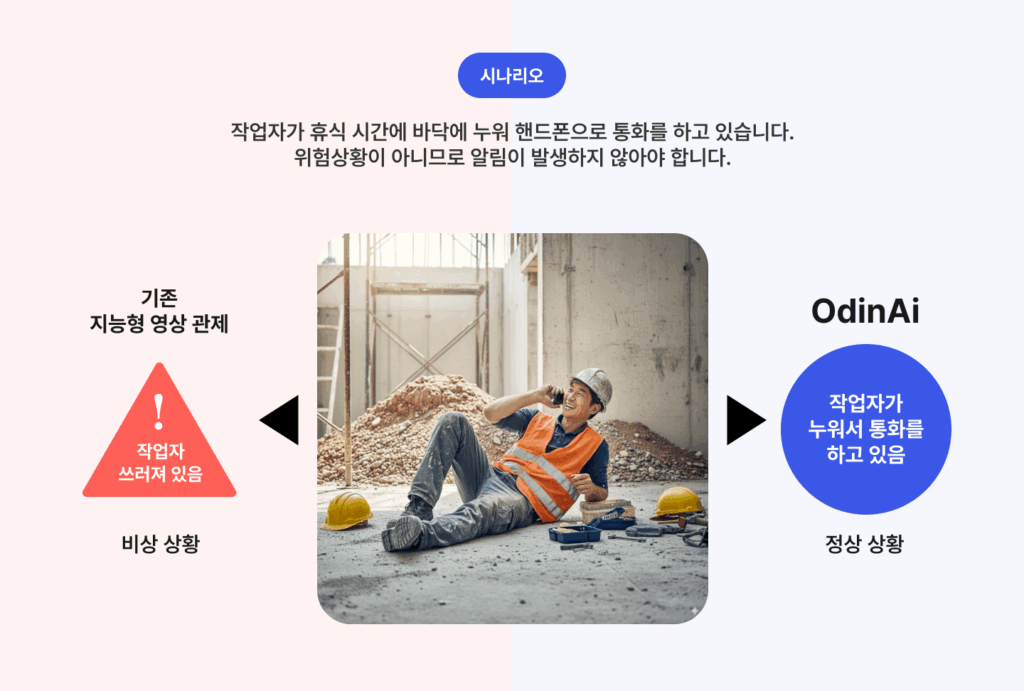
예를 들어, 작업자가 바닥에 누워 있다고 가정해봅시다. 기존 시스템은 무조건 “쓰러짐”으로 인식해 경고를 울렸습니다. 하지만 Odin Ai는 주변 상황을 함께 고려합니다.
작업자가 휴대전화를 들고 통화 중이라면? → “휴식”으로 해석합니다.
반대로 주변에 위험 요인이 감지된다면? → “사고 발생”으로 판단하죠.
영상관제의 새로운 표준을 제시하는 Odin AI
Odin AI는 생성형 AI 기반 영상 관제 시스템으로, 기존 딥러닝 기반의 지능형 CCTV의 구조적 한계를 뛰어넘습니다. 단순 객체 인식을 넘어, 상황을 이해하고 설명까지 해내는 차원이 다른 AI 관제 시스템입니다.
- 맥락 이해: 단순 좌표값 비교가 아니라, 장면 전체 의미 해석
- 행동 인식: 객체뿐 아니라 행동·의도까지 파악
- 오탐/미탐 최소화: 불필요한 경보는 줄이고, 실제 위험에는 더 빠르게 대응
Odin AI의 기술구조 : 생성형 멀티모달 AI의 결합
ODIN AI는 영상, 텍스트, 자연어 명령을 함께 처리할 수 있는 생성형 멀티모달 AI 구조로 설계되었습니다.
LLM(거대언어모델)과 VLM(비전언어모델)을 결합해 기존 딥러닝 방식이 가진 한계를 넘어섰으며, 단순한 객체 인식을 넘어 영상 속 객체 간의 관계와 상황의 맥락까지 이해하는 관제를 실현합니다.

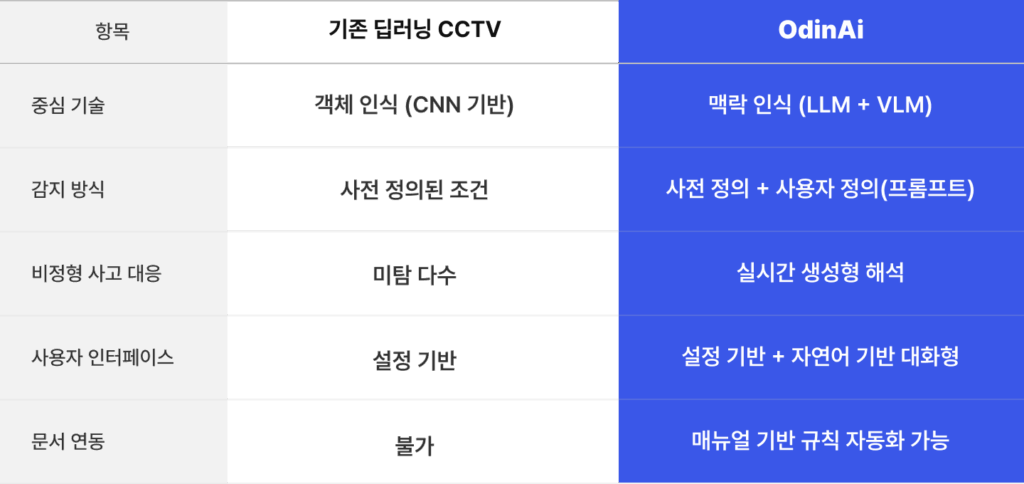
기존 지능형 CCTV와의 차별점
마치며
지금까지 살펴본 것처럼, 기존 지능형 CCTV는 객체 인식에 집중한 탓에 맥락을 이해하지 못하는 한계가 분명했습니다. Odin AI는 이러한 구조적 한계를 보완하며, 영상 속 상황을 해석하고 판단하는 새로운 접근을 제시합니다.
앞으로도 Odin AI는 지속적인 기술 발전과 현장 적용을 통해 새로운 가능성을 보여드릴 예정입니다. 다음 소식도 기대해 주세요.!



